Large language models (LLMs) are taking the machine learning world by storm. Due to their Transformer architecture, LLMs have an uncanny ability to learn from vast amounts of unstructured data, like text, images, video, or audio. They perform thoroughly on many task types, either extractive like text classification or generative like text summarization and text-to-image generation.
As their name implies, LLMs are large models that usually exceed the 10-billion parameter mark. Some have greater than 100 billion parameters, just like the BLOOM model. LLMs require numerous computing power, typically present in high-end GPUs, to predict fast enough for low-latency use cases like search or conversational applications. Unfortunately, for a lot of organizations, the associated costs might be prohibitive and make it difficult to make use of state-of-the-art LLMs of their applications.
On this post, we are going to discuss optimization techniques that help reduce LLM size and inference latency, helping them run efficiently on Intel CPUs.
A primer on quantization
LLMs often train with 16-bit floating point parameters (a.k.a FP16/BF16). Thus, storing the worth of a single weight or activation value requires 2 bytes of memory. As well as, floating point arithmetic is more complex and slower than integer arithmetic and requires additional computing power.
Quantization is a model compression technique that goals to unravel each problems by reducing the range of unique values that model parameters can take. For example, you may quantize models to lower precision like 8-bit integers (INT8) to shrink them and replace complex floating-point operations with simpler and faster integer operations.
In a nutshell, quantization rescales model parameters to smaller value ranges. When successful, it shrinks your model by no less than 2x, with none impact on model accuracy.
You may apply quantization during training, a.k.a quantization-aware training (QAT), which generally yields the perfect results. In the event you’d prefer to quantize an existing model, you may apply post-training quantization (PTQ), a much faster technique that requires little or no computing power.
Different quantization tools can be found. For instance, PyTorch has built-in support for quantization. You may also use the Hugging Face Optimum Intel library, which incorporates developer-friendly APIs for QAT and PTQ.
Quantizing LLMs
Recent studies [1][2] show that current quantization techniques don’t work well with LLMs. Specifically, LLMs exhibit large-magnitude outliers in specific activation channels across all layers and tokens. Here’s an example with the OPT-13B model. You may see that one among the activation channels has much larger values than all others across all tokens. This phenomenon is visible in all of the Transformer layers of the model.
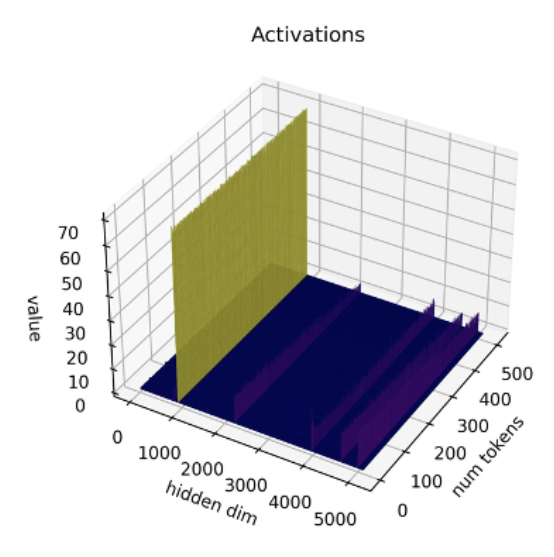
*Source: SmoothQuant*
The perfect quantization techniques thus far quantize activations token-wise, causing either truncated outliers or underflowing low-magnitude activations. Each solutions hurt model quality significantly. Furthermore, quantization-aware training requires additional model training, which just isn’t practical typically resulting from lack of compute resources and data.
SmoothQuant [3][4] is a brand new quantization technique that solves this problem. It applies a joint mathematical transformation to weights and activations, which reduces the ratio between outlier and non-outlier values for activations at the price of accelerating the ratio for weights. This transformation makes the layers of the Transformer “quantization-friendly” and enables 8-bit quantization without hurting model quality. As a consequence, SmoothQuant produces smaller, faster models that run well on Intel CPU platforms.
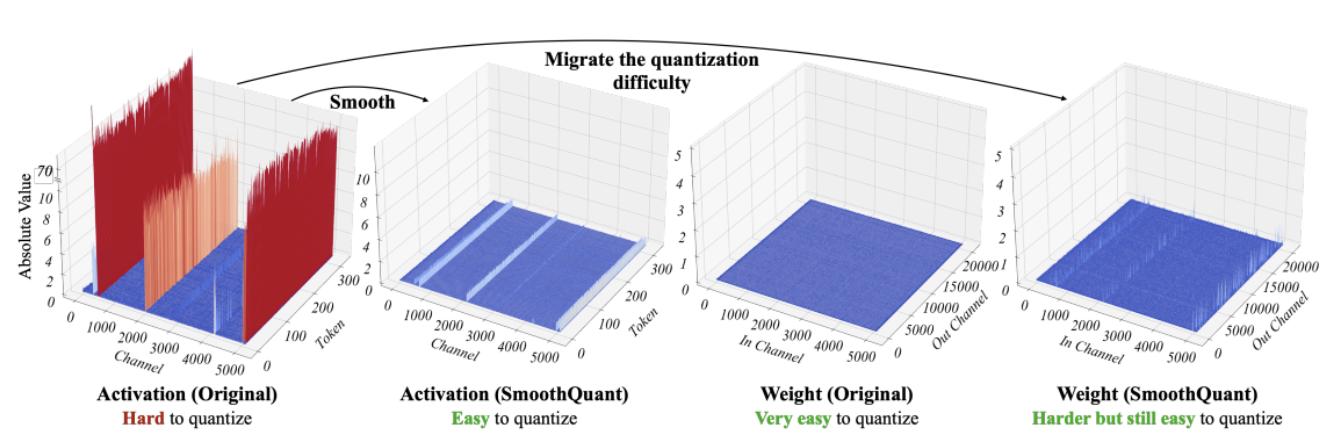
*Source: SmoothQuant*
Now, let’s see how SmoothQuant works when applied to popular LLMs.
Quantizing LLMs with SmoothQuant
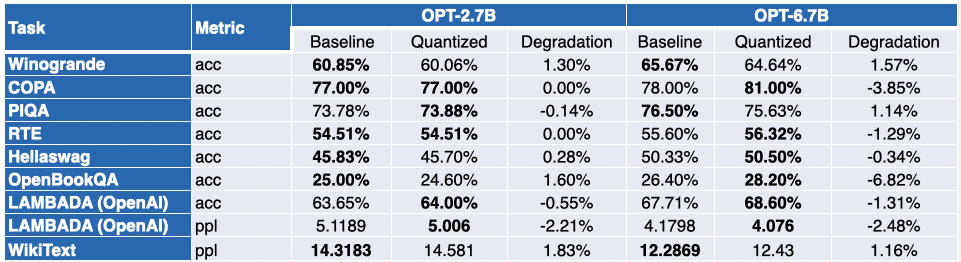
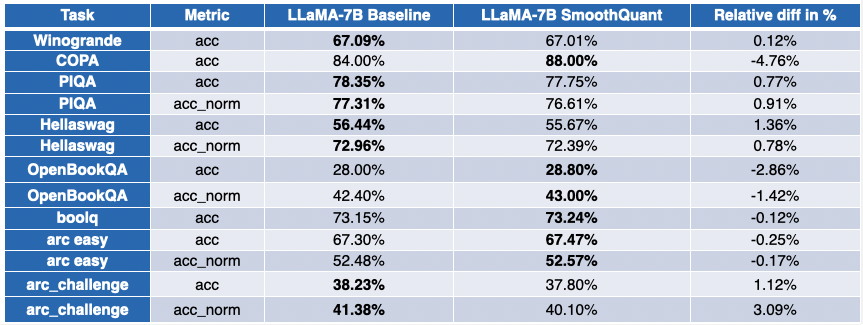
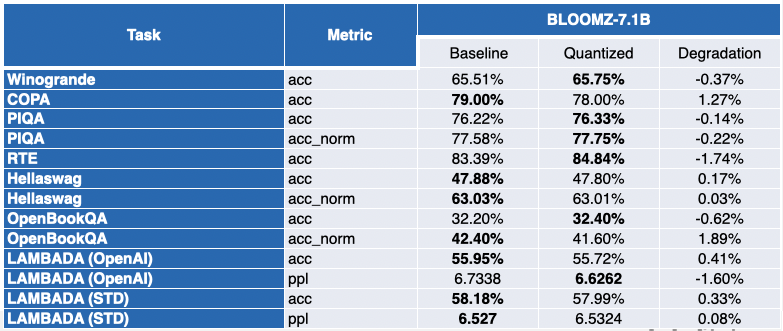
Our friends at Intel have quantized several LLMs with SmoothQuant-O3: OPT 2.7B and 6.7B [5], LLaMA 7B [6], Alpaca 7B [7], Vicuna 7B [8], BloomZ 7.1B [9] MPT-7B-chat [10]. Additionally they evaluated the accuracy of the quantized models, using Language Model Evaluation Harness.
The table below presents a summary of their findings. The second column shows the ratio of benchmarks which have improved post-quantization. The third column incorporates the mean average degradation (* a negative value indicates that the benchmark has improved). Yow will discover the detailed results at the tip of this post.
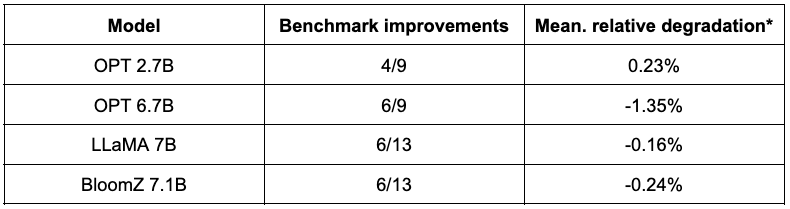
As you may see, OPT models are great candidates for SmoothQuant quantization. Models are ~2x smaller in comparison with pretrained 16-bit models. Many of the metrics improve, and those that don’t are only marginally penalized.
The image is somewhat more contrasted for LLaMA 7B and BloomZ 7.1B. Models are compressed by an element of ~2x, with about half the duty seeing metric improvements. Again, the opposite half is barely marginally impacted, with a single task seeing greater than 3% relative degradation.
The apparent advantage of working with smaller models is a major reduction in inference latency. Here’s a video demonstrating real-time text generation with the MPT-7B-chat model on a single socket Intel Sapphire Rapids CPU with 32 cores and a batch size of 1.
In this instance, we ask the model: “*What’s the role of Hugging Face in democratizing NLP?*”. This sends the next prompt to the model:
“A chat between a curious user and a man-made intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user’s questions. USER: What’s the role of Hugging Face in democratizing NLP? ASSISTANT:“
The instance shows the extra advantages you may get from 8bit quantization coupled with 4th Gen Xeon leading to very low generation time for every token. This level of performance definitely makes it possible to run LLMs on CPU platforms, giving customers more IT flexibility and higher cost-performance than ever before.
Chat experience on Xeon
Recently, Clement, the CEO of HuggingFace, recently said: “*More firms could be higher served specializing in smaller, specific models which might be cheaper to coach and run.*” The emergence of relatively smaller models like Alpaca, BloomZ and Vicuna, open a brand new opportunity for enterprises to lower the price of fine-tuning and inference in production. As demonstrated above, high-quality quantization brings high-quality chat experiences to Intel CPU platforms, without the necessity of running mammoth LLMs and complicated AI accelerators.
Along with Intel, we’re hosting a brand new exciting demo in Spaces called Q8-Chat (pronounced “Cute chat”). Q8-Chat offers you a ChatGPT-like chat experience, while only running on a single socket Intel Sapphire Rapids CPU with 32 cores and a batch size of 1.
Next steps
We’re currently working on integrating these latest quantization techniques into the Hugging Face Optimum Intel library through Intel Neural Compressor.
Once we’re done, you’ll have the ability to copy these demos with just just a few lines of code.
Stay tuned. The longer term is 8-bit!
This post is guaranteed 100% ChatGPT-free.
Acknowledgment
This blog was made at the side of Ofir Zafrir, Igor Margulis, Guy Boudoukh and Moshe Wasserblat from Intel Labs.
Special due to them for his or her great comments and collaboration.
Appendix: detailed results
A negative value indicates that the benchmark has improved.