
, I discussed the way to create your first DataFrame using Pandas. I discussed that the very first thing it’s essential master is Data structures and arrays before moving on to data evaluation with Python.
Pandas is a superb library for data manipulation and retrieval. Mix it with Numpy and Seaborne, and also you’ve got yourself a powerhouse for data evaluation.
In this text, I’ll be walking you thru practical ways to filter data in pandas, starting with easy conditions and moving on to powerful methods like .isin(), .str.startswith(), and .query(). By the tip, you’ll have a toolkit of filtering techniques you possibly can apply to any dataset.
Without further ado, let’s get into it!
Importing our data
Okay, to begin, I’ll import our pandas library
# importing the pandas library
import pandas as pdThat’s the one library I’ll need for this use case
Next, I’ll import the dataset. The dataset comes from ChatGPT, btw. It consists of basic sales transaction records. Let’s take a have a look at our dataset.
# trying out our data
df_sales = pd.read_csv('sales_data.csv')
df_salesHere’s a preview of the information
It consists of basic sales records with columns OrderId, Customer, Product, Category, Quantity, Price, OrderDate and Region.
Alright, let’s begin our filtering!
Filtering by a single condition
Let’s try to pick all records from a specific category. As an example, I need to understand how many unique orders were made within the Electronics category. To try this, it’s pretty straightforward
# Filter by a single condition
# Example: All orders from the “Electronics” category.
df_sales[‘Category’] == ‘Electronics’In Python, it’s essential distinguish between the = operator and the == operator.
= is used to assign a worth to a variable.
As an example
x = 10 # Assigns the worth 10 to the variable x== then again is used to match two values together. As an example
a = 3
b = 3
print(a == b) # Output: True
c = 5
d = 10
print(c == d) # Output: FalseWith that said, let’s apply the identical notion to the filtering I did above
# Filter by a single condition
# Example: All orders from the “Electronics” category.
df_sales[‘Category’] == ‘Electronics’Here, I’m mainly telling Python to go looking through our entire record to search out a category named Electronics. When it finds a match, it displays a Boolean result, True or False. Here’s the result

As you possibly can see. We’re getting a Boolean output. True means Electronics exists, while False means the latter. That is okay and all, but it may develop into confusing in case you’re coping with a lot of records. Let’s fix that.
# Filter by a single condition
# Example: All orders from the “Electronics” category.
df_sales[df_sales[‘Category’] == ‘Electronics’]Here, I just wrapped the condition within the DataFrame. And with that, we get this output

Significantly better, right? Let’s move on
Filter rows by numeric condition
Let’s attempt to retrieve records where the order quantity is larger than 2. It’s pretty straightforward.
# Filter rows by numeric condition
# Example: Orders where Quantity > 2
df_sales[‘Quantity’] > 2Here, I’m using the greater than > operator. Much like our output above, we’re gonna get a Boolean result with True and False values. Let’s fix it up real quick.

And there we go!
Filter by date condition
Filtering by date is easy. As an example.
# Filter by date condition
# Example: Orders placed after “2023–01–08”
df_sales[df_sales[“OrderDate”] > “2023–01–08”]This checks for orders placed after January 8, 2023. And here’s the output.

The cool thing about Pandas is that it converts string data types to dates routinely. In cases where you encounter an error. It is advisable to convert to a date before filtering using the to_datetime() function. Here’s an example
df[“OrderDate”] = pd.to_datetime(df[“OrderDate”])This converts our OrderDate column to a date data type. Let’s kick things up a notch.
Filtering by Multiple Conditions (AND, OR, NOT)
Pandas enables us to filter on multiple conditions using logical operators. Nevertheless, these operators are different from Python’s built-in operators like (and, or, not). Listed below are the logical operators you’ll be working with probably the most
& (Logical AND)
The ampersand (&) symbol represents AND in pandas. We use this after we’re attempting to fulfil two conditions. On this case, each conditions need to be true. As an example, let’s retrieve orders from the “Furniture” category where Price > 500.
# Multiple conditions (AND)
# Example: Orders from “Furniture” where Price > 500
df_sales[(df_sales[“Category”] == “Furniture”) & (df_sales[“Price”] > 500)]Let’s break this down. Here, now we have two conditions. One which retrieves orders within the Furniture category and one other that filters for prices > 500. Using the &, we’re capable of mix each conditions.
Here’s the result.

One record was managed to be retrieved. it, it meets our condition. Let’s do the identical for OR
| (Logical OR)
The |,vertical bar symbol is used to represent OR in pandas. On this case, at the very least one among the corresponding elements needs to be True. As an example, let’s retrieve records with orders from the “North” region OR “East” region.
# Multiple conditions (OR)
# Example: Orders from “North” region OR “East” region.
df_sales[(df_sales[“Region”] == “North”) | (df_sales[“Region”] == “East”)]Here’s the output

Filter with isin()
Let’s say I need to retrieve orders from multiple customers. I could all the time use the & operator. As an example
df_sales[(df_sales[‘Customer’] == ‘Alice’) | (df_sales[‘Customer’] == ‘Charlie’)]Output:

Nothing improper with that. But there’s a greater and easier solution to do that. That’s by utilizing the isin() function. Here’s how it really works
# Orders from customers ["Alice", "Diana", "James"].
df_sales[df_sales[“Customer”].isin([“Alice”, “Diana”, “James”])]Output:

The code is way easier and cleaner. Using the isin() function, I can add as many parameters as I need. Let’s move on to some more advanced filtering.
Filter using string matching
One in every of Pandas’ powerful but underused functions is string matching. It helps a ton in data cleansing tasks whenever you’re trying to go looking through patterns within the records in your DataFrame. Much like the LIKE operator in SQL. As an example, let’s retrieve customers whose name starts with “A”.
# Customers whose name starts with "A".
df_sales[df_sales[“Customer”].str.startswith(“A”)]Output:

Pandas gives you the .str accessor to make use of string functions. Here’s one other example
# Products ending with “top” (e.g., Laptop).
df_sales[df_sales[“Product”].str.endswith(“top”)]Output:

Filter using query() method
In the event you’re coming from a SQL background, this method could be so helpful for you. Let’s attempt to retrieve orders from the electronics category where the amount > 2. It might all the time go like this.
df_sales[(df_sales[“Category”] == “Electronics”) & (df_sales[“Quantity”] >= 2)]Output:
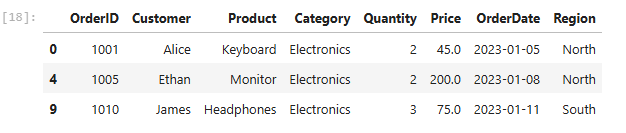
But in case you’re someone trying to usher in your SQL sauce. It will be just right for you as a substitute
df.query(“Category == ‘Electronics’ and Quantity >= 2”)You’ll get the identical output above. Pretty much like SQL in case you ask me, and also you’ll have the option to ditch the & symbol. I’m gonna be using this method very often.
Filter by column values in a variety
Pandas permits you to retrieve a variety of values. As an example, Orders where the Price is between 50 and 500 would go like this
# Orders where the Price is between 50 and 500
df_sales[df_sales[“Price”].between(50, 500)]Output:

Pretty straightforward.
Filter missing values (NaN)
This might be probably the most helpful function because, as an information analyst, one among the information cleansing tasks you’ll be working on probably the most is filtering out missing values. To do that in Pandas is easy. That’s by utilizing the notna() function. Let’s filter rows where Price just isn’t null.
# filter rows where Price just isn't null.
df_sales[df_sales[“Price”].notna()]Output:

And there you go. I don’t really notice the difference, though, but I’m gonna trust it’s done.
Conclusion
The following time you open a messy CSV and wonder , try filtering first. It’s the quickest solution to cut through the noise and find the story hidden in your data.
The transition to Python for data evaluation used to feel like an enormous step, coming from a SQL background. But for some reason, Pandas seems way easier and fewer time-consuming for me for filtering data
The cool part about that is that these same techniques work regardless of the dataset — sales numbers, survey responses, web analytics, you name it.
I hope you found this text helpful.
Be happy to say hi on any of those platforms