
Addendum
After consulting with the authors of the IPO paper, we discovered that the implementation of IPO in TRL was incorrect; specifically, the loss over the log-likelihoods of the completions must be averaged as an alternative of summed. Now we have added a fix in this PR and re-run the experiments. The outcomes are actually consistent with the paper, with IPO on par with DPO and performing higher than KTO within the paired preference setting. Now we have updated the post to reflect these recent results.
TL;DR
We evaluate three promising methods to align language models without reinforcement learning (or preference tuning) on numerous models and hyperparameter settings. Particularly we train using different hyperparameters and evaluate on:
Introduction
On this post, we perform an empirical evaluation of three promising LLM alignment algorithms: Direct Preference Optimization (DPO), Identity Preference Optimisation (IPO) and Kahneman-Tversky Optimisation (KTO). We conducted our experiments on two prime quality 7b LLMs which have undergone a supervised fine-tuning step, but no preference alignment. We discover that while one algorithm clearly outshines the others, there are key hyper-parameters that have to be tuned to attain the very best results.
Alignment without Reinforcement Learning
Direct Preference Optimization (DPO) has emerged as a promising alternative for aligning Large Language Models (LLMs) to human or AI preferences. Unlike traditional alignment methods, that are based on reinforcement learning, DPO recasts the alignment formulation as an easy loss function that might be optimised directly on a dataset of preferences , where is a prompt and are the popular and dispreferred responses.
 |
|---|
| Sample of a preference tuning dataset. |
This makes DPO easy to make use of in practice and has been applied with success to coach models like Zephyr and Intel’s NeuralChat.
The success of DPO has prompted researchers to develop recent loss functions that generalise the tactic in two most important directions:
- Robustness: One shortcoming of DPO is that it tends to quickly overfit on the preference dataset. To avoid this, researchers at Google DeepMind introduced Identity Preference Optimisation (IPO), which adds a regularisation term to the DPO loss and enables one to coach models to convergence without requiring tricks like early stopping.
- Dishing out with paired preference data altogether: Like most alignment methods, DPO requires a dataset of paired preferences , where annotators label which response is best in keeping with a set of criteria like helpfulness or harmfulness. In practice, creating these datasets is a time consuming and expensive endeavour. ContextualAI recently proposed an interesting alternative called Kahneman-Tversky Optimisation (KTO), which defines the loss function entirely by way of individual examples which were labelled as “good” or “bad” (for instance, the 👍 or 👎 icons one sees in chat UIs). These labels are much easier to amass in practice and KTO is a promising approach to continually update chat models running in production environments.
At the identical time, these various methods include hyperparameters, an important one being , which controls how much to weight the preference of the reference model. With these alternatives now available within the practitioner’s arsenal through libraries like 🤗 TRL, a natural query then becomes which of those methods and hyperparameters produce the very best chat model?
This post goals to reply this query by performing an empirical evaluation of the three methods. We’ll sweep over key hyperparameters comparable to and training steps, then evaluate the resulting models’ performance via MT-Bench, which is a standard benchmark to measure chat model capabilities.
We offer open-source code to duplicate these ends in a recent update to the 🤗 alignment-handbook.
Let’s start!
Links
Listed below are the essential links related to our evaluation:
Experimental Setup
There are two most important ingredients that one needs to contemplate when performing alignment experiments: the model we elect to optimize and the alignment dataset. To get more independent data points, we considered two models, OpenHermes-2.5-Mistral-7B and Zephyr-7b-beta-sft, and two alignment datasets Intel’s orca_dpo_pairs and the ultrafeedback-binarized dataset.
For the primary experiment, we used OpenHermes-2.5-Mistral-7B because it’s top-of-the-line 7B parameter chat models that hasn’t been subject to any alignment techniques. We then used Intel’s orca_dpo_pairs dataset, which consists of 13k prompts where the chosen response is generated by GPT-4, and the undesired response is generated by Llama-Chat 13b. That is the dataset behind NeuralChat and NeuralHermes-2.5-Mistral-7B. Since KTO doesn’t require pairwise preferences per se, we simply treat the GPT-4 responses as “good” labels and the Llama-Chat 13b ones as “bad”. While GPT-4’s responses are more likely to be preferred over Llama-Chat 13b, there could also be some cases where Llama-Chat-13b produces a greater response, we consider this to represent a small minority of the examples.
The second experiment performed preference alignment on theZephyr-7b-beta-sft model with the ultrafeedback-binarized dataset, which incorporates 66k prompts with pairs of chosen and rejected responses. This dataset was used to coach the unique Zephyr model, which on the time was the very best in school 7B model on quite a few automated benchmarks and human evaluations.
Configuring the experiments
The alignment handbook provides a simple approach to configure a single experiment, these parameters are used to configure the run_dpo.py script.
model_name_or_path: teknium/OpenHermes-2.5-Mistral-7B
torch_dtype: null
dataset_mixer:
HuggingFaceH4/orca_dpo_pairs: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
bf16: true
beta: 0.01
loss_type: sigmoid
do_eval: true
do_train: true
evaluation_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: HuggingFaceH4/openhermes-2.5-mistral-7b-dpo
hub_model_revision: v1.0
learning_rate: 5.0e-7
logging_steps: 10
lr_scheduler_type: cosine
max_prompt_length: 512
num_train_epochs: 1
optim: adamw_torch
output_dir: data/openhermes-2.5-mistral-7b-dpo-v1.0
per_device_train_batch_size: 8
per_device_eval_batch_size: 8
push_to_hub_revision: true
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1
We created an analogous base configuration file for the Zephyr experiments.
Chat templates were routinely inferred from the bottom Chat model, with OpenHermes-2.5 using ChatML format and Zephyr using the H4 chat template. Alternatively, if you must use your individual chat format, the 🤗 tokenizers library has now enabled user-defined chat templates using a jinja format strings:
"{% for message in messages %}n{% if message['role'] == 'user' %}n{>n' + message['content'] + eos_token }n{% elif message['role'] == 'system' %}n{system}n{% elif message['role'] == 'assistant' %}n{assistant}n{% endif %}n{% if loop.last and add_generation_prompt %}n{>' }n{% endif %}n{% endfor %}"
Which formats conversations as follows:
Hyperparameter Sweep
We trained the DPO, IPO and KTO methods via the loss_type argument TRL’s DPOTrainer with the beta going from 0.01, 0.1, 0.2, …, 0.9. We included 0.01 as we observed that some alignment algorithms are especially sensitive to this parameter. All experiments were trained for one epoch. All other hyperparameters are kept the identical during each run, including the random seed.
We then launched our scan on the Hugging Face cluster using the bottom configurations defined above. #GPURICH
#!/bin/bash
configs=("zephyr" "openhermes")
loss_types=("sigmoid" "kto_pair" "ipo")
betas=("0.01" "0.1" "0.2" "0.3" "0.4" "0.5" "0.6" "0.7" "0.8" "0.9")
for config in "${configs[@]}"; do
for loss_type in "${loss_types[@]}"; do
for beta in "${betas[@]}"; do
job_name="$config_${loss_type}_beta_${beta}"
model_revision="${loss_type}-${beta}"
sbatch --job-name=${job_name} recipes/launch.slurm dpo pref_align_scan config_$config deepspeed_zero3
"--beta=${beta} --loss_type=${loss_type} --output_dir=data/$config-7b-align-scan-${loss_type}-beta-${beta} --hub_model_revision=${model_revision}"
done
done
done
Results
We evaluated all models using MT Bench, a multi-turn benchmark that uses GPT-4 to evaluate models’ performance in eight different categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, and Humanities. Although imperfect, MT Bench is a very good approach to evaluate conversational LLMs.
Zephyr-7b-beta-SFT
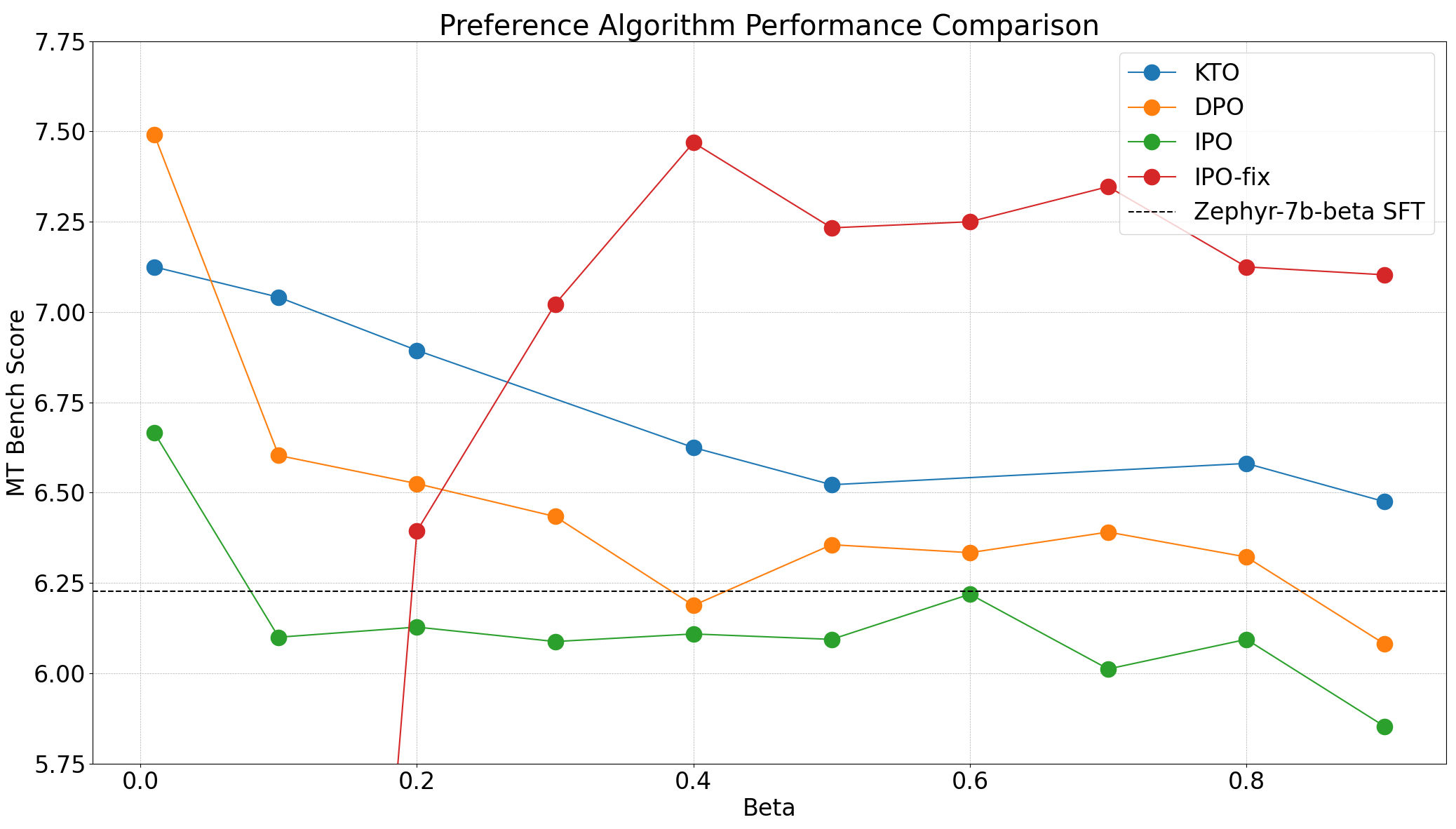 |
|---|
| MT-Bench scores for the Zephyr model for various . |
For the Zephyr model, we observed that the very best performance was achieved with the bottom value, 0.01. That is consistent across all three of the algorithms tested, an interesting follow on experiment for the community can be a high-quality grained scan within the range of 0.0-0.2. While DPO can achieve the very best MT Bench rating, we found that KTO (paired) achieves higher ends in all but one setting. IPO, while having stronger theoretical guarantees, appears to be worse than the bottom model in all but one setting.
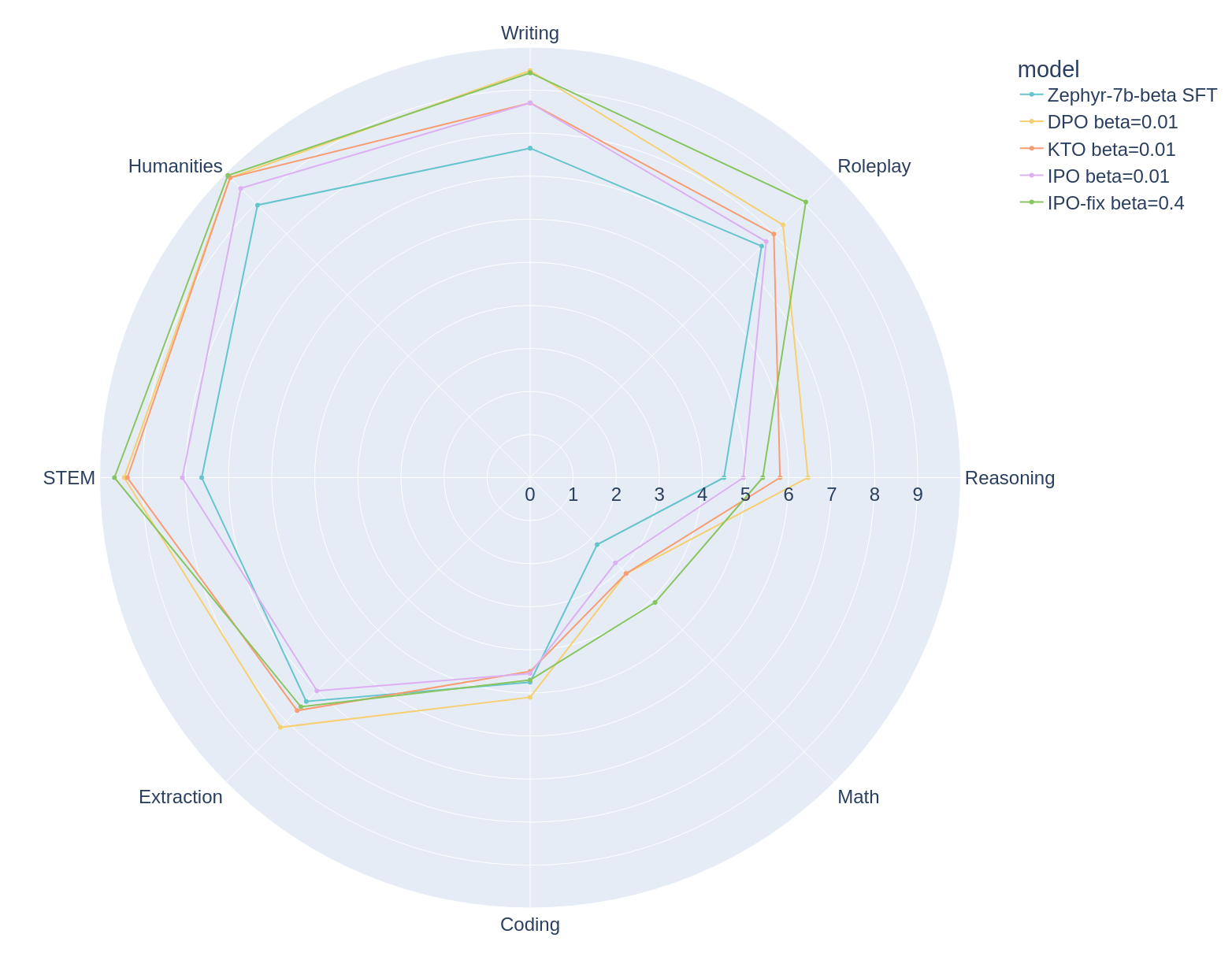 |
|---|
| Break down of the very best Zephyr models for every algorithm across MT Bench categories. |
We will break down the very best results for every algorithm across the categories that MT Bench evaluates to discover the strengths and weaknesses of those models. There remains to be a big area for improvement on the Reasoning, Coding, and Math axes.
OpenHermes-7b-2.5
While the observations about each algorithm remain the identical with OpenHermes, that’s that DPO > KTO > IPO, the sweet spot for varies wildly with each algorithm. With the very best selection of for DPO, KTO and IPO being 0.6, 0.3 and 0.01 respectively.
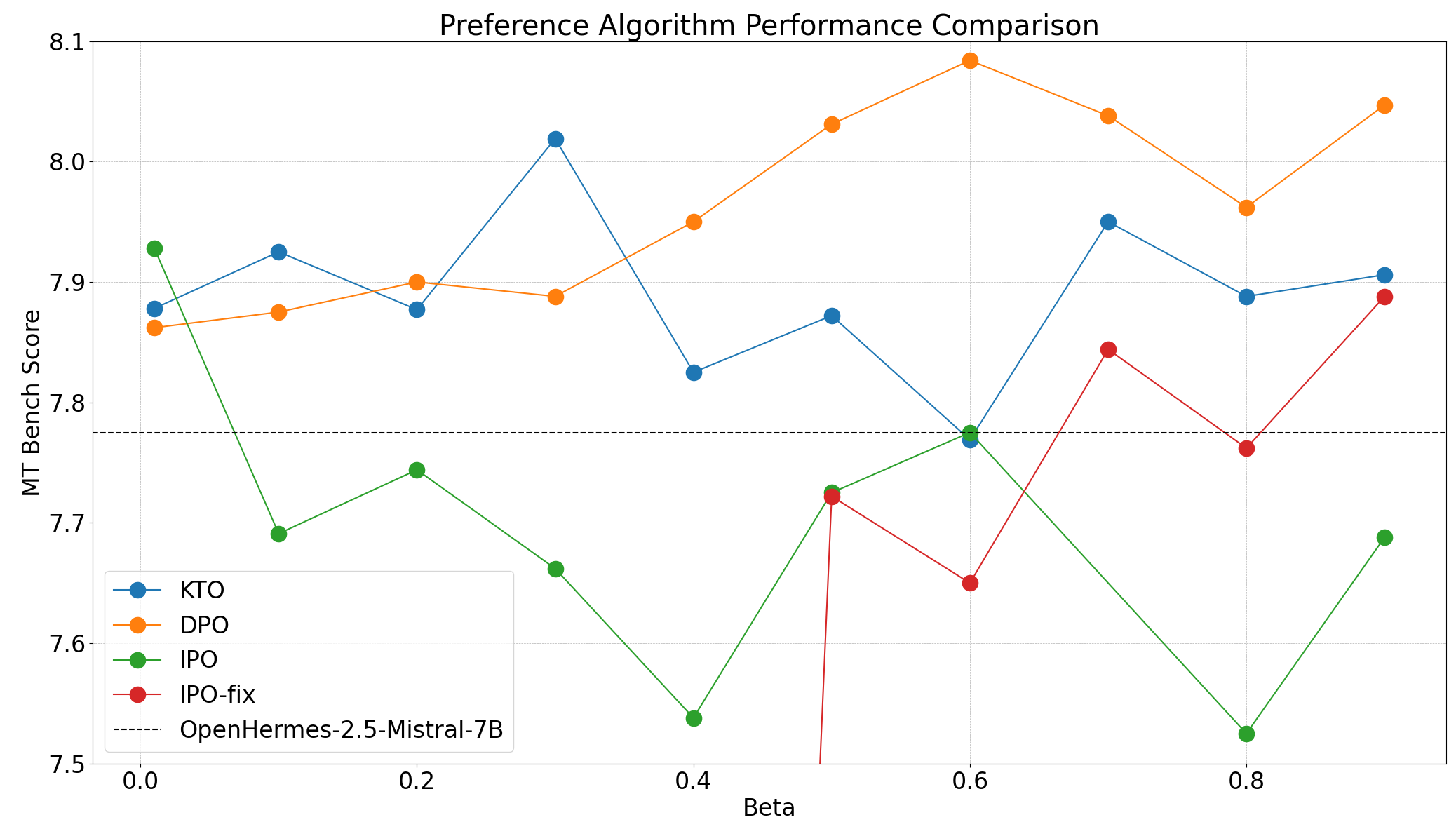 |
|---|
| MT Bench scores for the OpenHermes model for various . |
OpenHermes-7b-2.5 is clearly a stronger base model, with a mere 0.3 improvement in MT Bench rating after preference alignment.
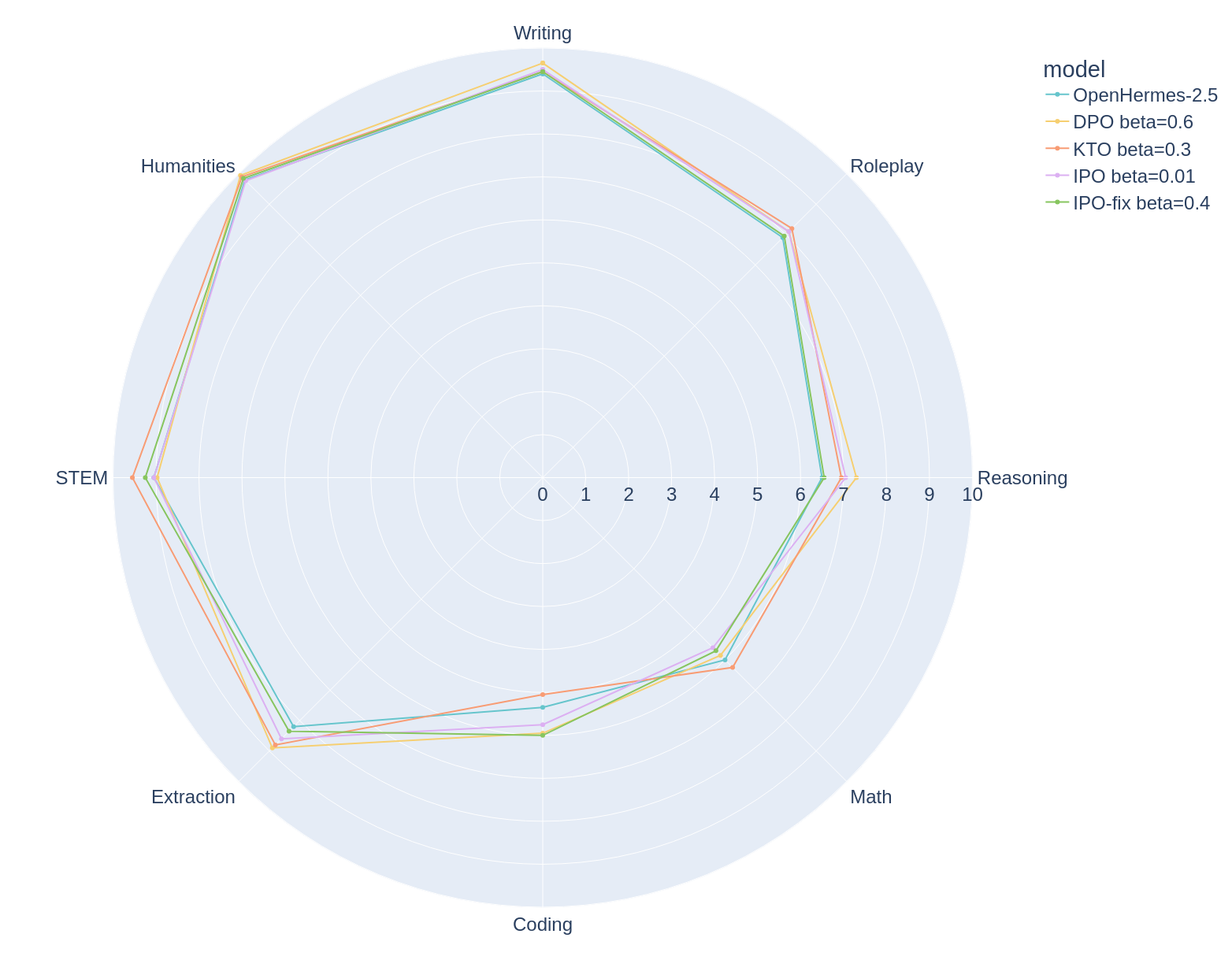 |
|---|
| Break down of the very best OpenHermes models for every algorithm across MT Bench categories. |
Summary & Insights
On this post, we’ve got highlighted the importance of selecting the proper set of hyperparameters when performing preference alignment. Now we have empirically demonstrated that DPO and IPO can achieve comparable results, outperforming KTO in a paired preference setting.
All code and configuration files replicating these results are actually available within the alignment-handbook. The most effective-performing models and datasets might be present in this collection.
What’s next?
We’ll proceed our work implementing recent preference alignment algorithms in TRL and evaluating their performance. It seems, at the least in the interim, that DPO is probably the most robust and best performing LLM alignment algorithm. KTO stays an interesting development, as each DPO and IPO require pairs preference data, whereas KTO might be applied to any dataset where responses are rated positively or negatively.
We look ahead to the brand new tools and techniques that can be developed in 2024!