


Model merging has quickly develop into the de-facto standard of pushing the performance limits of huge language models. On the Open LLM Leaderboard, we proceed to note merged models topping up the charts. Our very own Omar Sanseviero, made somewhat sprint on model merging and discovered interesting findings.
The standard way of model merging, to this point, has been to take a set of models and merge them. This post gives a pleasant primer on this topic. Generally, for merging multiple models, we first download their checkpoints after which perform merging. Depending on the merge algorithm and the sizes of the underlying model, this process may be quite memory-intensive. The mergekit library provides optimized ways for handling this, making the method manageable on limited memory.
But what if we desired to merge different “adapters” obtained from the same model? You would possibly have 4 different LoRA checkpoints obtained from the identical base model, and you desire to experiment with different merging techniques. Eventually, you desire to settle with the most effective merge, supplying you with the most effective results in your task. A few things develop into evident when approaching such a developer experience:
- When coping with adapters akin to LoRA, it’s common for users to swap out and in different adapters and even mix them. Adapters may be activated, de-activated, or completely swapped out of the memory. Due to this fact, we’d like to do the “merging” part on the fly (versus the tactic described above) to offer a seamless experience to the users.
- Different adapters might need different requirements for merging. The merging algorithm for LoRA won’t equally translate to IA3, for instance.
With these facets in mind, we shipped recent merging methods targeting the favored LoRA adapters in 🤗 PEFT. On this post, we would like to take you thru the methods available, code examples to make it easier to get cracking, impressive results, and our future plans. Let’s start 🚀
Table of content
Methods for combining/merging LoRA adapters
Concatenation (cat)
On this method, the LoRA matrices are concatenated. For instance, if we have now 2 LoRA adapters and together with weights and for weighted merging of those two adapters, then the merging happens as follows:
where .
Now, the output of this recent merged LoRA layer can be as if the unique 2 LoRAs were energetic with weights and for applied to the primary and second adapters, respectively.
Here, we will observe that:
set_adapters() wherein as a substitute of making a brand new merged adapter, the energetic adapters are combined sequentially, as shown on the right-hand side of the above equation. When using this method, it allows for participating LoRA adapters to have different ranks.
Linear/Task Arithmetic (linear)
On this method, the LoRA matrices are involved in weighted sum. That is what the Task arithmetic paper implements on task weights. In task arithmetic, one first computes the duty weights which is difference between finetuned weights and base model weights, then does a weighted sum of those task weights. Here, the delta weights considered are the person matrices and as a substitute of their product . This method may be applied only when all of the participating LoRA adapters have same rank.
Let’s undergo an example. Consider 2 LoRA adapters & together with weights and for weighted merging of those two adapters, then the merging happens as follows:
For more details, please check with the paper: Editing Models with Task Arithmetic.
SVD (svd)
As a substitute of considering individual matrices and as task weights, their product which is the delta weight is taken into account the duty weight.
Let’s proceed with the instance from the previous sub-sections. Here, first the delta weight of merged combination is computed as follows:
After getting the above-merged delta weight, SVD (singular value decomposition) is applied to get the approximates and :

🧠 Much like cat method, this method also allows for LoRA adapters with different ranks. As well as, one can select the rank for the resultant merged LoRA adapter which defaults to the utmost rank among the many participating LoRA adapters. A limitation of this approach is that it requires lots of GPU memory for performing the SVD operation.
TIES (ties , ties_svd )
This builds upon the linear and svd methods by changing the way in which merged adapters are computed from task weights and end in the ties and ties_svd methods, respectively. In TIES (TRIM, ELECT SIGN & MERGE), one first computes the duty weights which in our case can be the LoRA adapters , for non svd variant and their product for svd variant. After this, you prune the smallest values of the duty weights and retain the top-k values based on the required fraction density . Then, you calculate the bulk sign mask from the participating pruned task weights, multiply task tensors with the user provided weightage followed by disjoint merge based on the bulk sign mask. For majority sign mask computation, you may have two options:
totalconsiders the magnitude in addition to sign to get the bulk sign, i.e., sum up all of the corresponding weights;frequencyonly considers the burden sign to acquire the bulk sign, i.e., sum up the sign of all of the corresponding weights.
For more details, check with the paper: TIES-Merging: Resolving Interference When Merging Models.
DARE (dare_linear , dare_ties , dare_linear_svd , dare_ties_svd )
This also builds upon the linear and svd methods wherein the duty weights are LoRA adapters , for non svd variant and their product for svd variant. DARE method proposed in Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch first randomly prunes the values of the duty weight based on the required fraction 1-density, after which rescales the pruned task weights by 1/density. DARE is a general plug-in and may be applied to any existing model merging methods. We’ve implemented DARE with Linear/Task Arithmetic (*_linear*) and TIES (*_ties*).
For *_linear* variants of DARE, we first use DARE to randomly prune task weights after which perform weighted sum of task tensors based on user specified weightage for participating LoRA adapters.
For *_ties* variants of DARE, we first use DARE to get the pruned task weights, then adopt the last 2 steps of ties, i.e., calculating majority sign mask and using the mask to perform disjoint merge of the duty weights.
Magnitude Prune (magnitude_prune , magnitude_prune_svd )
This also builds upon the linear and svd methods wherein the duty weights are LoRA adapters , for non svd variant and their product for svd variant. On this method, you first prune the smallest values of the duty weights and retain the top-k values based on the required fraction density. Then, you perform the weighted sum of task tensors based on user-specified weightage for participating LoRA adapters.
How do I merge my LoRA adapters?
In PEFT, when using LoRA, you should use the category method add_weighted_adapter() to try the various combining methods. For instance, below you may see how we will mix three LoRA adapters using ties method and the resulting generations from the brand new merged adapter. We will observe that merged adapter is capable of retain the capabilities of individual adapters:

You could find the above example within the PEFT repo’s examples.
Let’s take one other example, as shown below, using magnitude_prune method and the resulting generations.
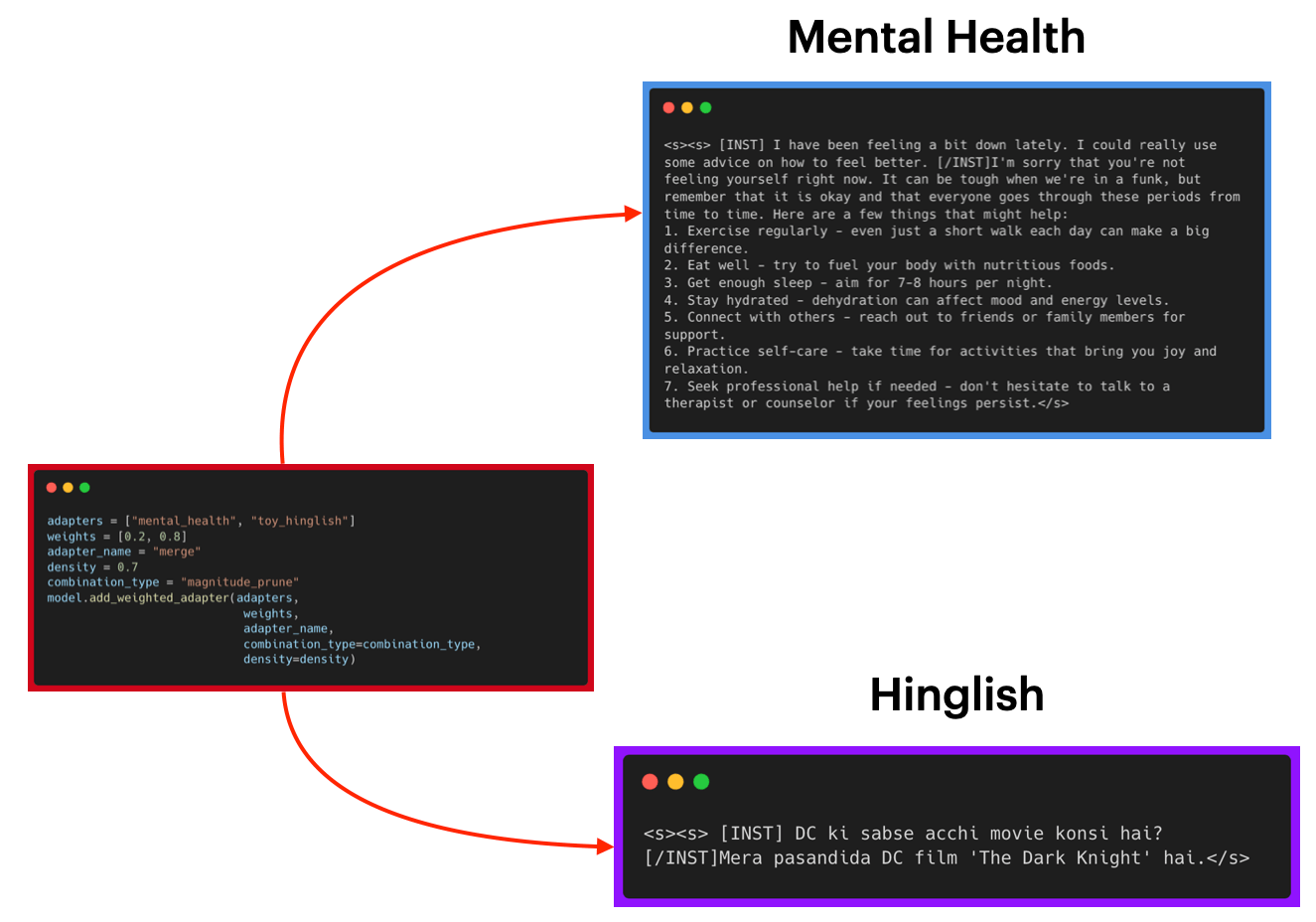
Now, what if we would like to make use of the merged adapters capability to reply a mental health related query in Hinglish? This could require capabilities from each the adapters for use. Below we will see the outcomes on the query “Sad feelings ko kaise dur kare?” (Translation: Methods to do away with sad feelings?). When, all adapters are disabled and the bottom model is used, the response starts with it being an AI followed by general suggestions. When hinglish adapter is enabled, the response is in Hinglish and short following the finetuning data but doesn’t do job at giving concrete suggestions to assist overcome sadness. When mental_health adapter is enabled, the response is akin to what a human would say but sadly it isn’t in Hinglish. When merge adapter is enabled, we will see that the response is in Hinglish and short while giving concrete suggestions which may be present in the response of mental_health adapter akin to exercising, spending time with friends, reading, meditation and specializing in positive considering. Due to this fact, we will observe that merging adapters can result in combining their individual capabilities to support recent use cases.

Finally, let’s take the instance of dare_linear and check the resulting generations.
We’ve a dedicated developer guide for these merging methods in PEFT which you could find here.
Extending to text-to-image generation
On this section, we show you the right way to reap the benefits of these merging methods for text-to-image generation using 🤗 Diffusers. Note that Diffusers already relies on PEFT for all things LoRA, including training and inference. Nevertheless, currently, it’s impossible to profit from the brand new merging methods when calling set_adapters() on a Diffusers pipeline. For this reason we’re openly discussing with the community the right way to best support it natively from inside Diffusers.
But due to PEFT, there’s at all times a solution to circumvent around this. We’ll use the add_weighted_adapter() functionality for this. Precisely, these are the steps that we’ll take to mix the “toy-face” LoRA and the “Pixel-Art” loRA, and experiment with different merging techniques:
- Obtain
PeftModels from these LoRA checkpoints. - Merge the
PeftModels using theadd_weighted_adapter()method with a merging approach to our alternative. - Assign the merged model to the respective component of the underlying
DiffusionPipeline.
Let’s see this in motion. All of the code shown within the parts below come from this Colab Notebook.
Since each the LoRA checkpoints use SDXL UNet because the their base model, we are going to first load the UNet:
from diffusers import UNet2DConditionModel
import torch
unet = UNet2DConditionModel.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
subfolder="unet",
).to("cuda")
We then load the actual SDXL pipeline and the LoRA checkpoints. We start with the “CiroN2022/toy-face” LoRA:
from diffusers import DiffusionPipeline
import copy
sdxl_unet = copy.deepcopy(unet)
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
variant="fp16",
torch_dtype=torch.float16,
unet=unet
).to("cuda")
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
Now, obtain the PeftModel from the loaded LoRA checkpoint:
from peft import get_peft_model, LoraConfig
toy_peft_model = get_peft_model(
sdxl_unet,
pipe.unet.peft_config["toy"],
adapter_name="toy"
)
original_state_dict = {f"base_model.model.{k}": v for k, v in pipe.unet.state_dict().items()}
toy_peft_model.load_state_dict(original_state_dict, strict=True)
💡 You possibly can optionally push the toy_peft_model to the Hub using: toy_peft_model.push_to_hub("toy_peft_model", token=TOKEN).
Next, we do the identical for the “nerijs/pixel-art-xl” LoRA:
pipe.delete_adapters("toy")
sdxl_unet.delete_adapters("toy")
pipe.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
pipe.set_adapters(adapter_names="pixel")
pixel_peft_model = get_peft_model(
sdxl_unet,
pipe.unet.peft_config["pixel"],
adapter_name="pixel"
)
original_state_dict = {f"base_model.model.{k}": v for k, v in pipe.unet.state_dict().items()}
pixel_peft_model.load_state_dict(original_state_dict, strict=True)
Now, we’re all equipped with weighted adapter inference! We start by loading all of the essential things:
from peft import PeftModel
from diffusers import UNet2DConditionModel, DiffusionPipeline
import torch
base_unet = UNet2DConditionModel.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
subfolder="unet",
).to("cuda")
toy_id = "sayakpaul/toy_peft_model"
model = PeftModel.from_pretrained(base_unet, toy_id, use_safetensors=True, subfolder="toy", adapter_name="toy")
model.load_adapter("sayakpaul/pixel_peft_model", use_safetensors=True, subfolder="pixel", adapter_name="pixel")
Now, mix the LoRA adapters — the moment all of us have been waiting for!
model.add_weighted_adapter(
adapters=["toy", "pixel"],
weights=[0.7, 0.3],
combination_type="linear",
adapter_name="toy-pixel"
)
model.set_adapters("toy-pixel")
Here, we are only starting with the “linear” merging strategy but will experiment with other exotic merging algorithms, akin to TIES. We finally assign the model to our DiffusionPipeline and perform inference:
model = model.to(dtype=torch.float16, device="cuda")
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", unet=model, variant="fp16", torch_dtype=torch.float16,
).to("cuda")
prompt = "toy_face of a hacker with a hoodie, pixel art"
image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
image

Let’s try ties_svd method. You could find the instance notebook here.
pipe.unet.add_weighted_adapter(
["teapot","watercolour"],
[1.0, 1.0],
"merge",
combination_type="ties_svd",
density=0.5
)

Now, let’s try combining two style LoRAs using dare_linear:
model.add_weighted_adapter(
adapters=["toy", "pixel"],
weights=[1.0, 1.0],
combination_type="dare_linear",
adapter_name="merge",
density=0.7
)
![]()
Now, let’s try ties method with majority_sign_method="frequency" :
model.add_weighted_adapter(
adapters=["toy", "sticker"],
weights=[1.0, 1.0],
combination_type="ties",
adapter_name="merge",
density=0.5,
majority_sign_method="frequency"
)

Observations
- In most scenarios,
catmethod will give great results. So, start with that. Nevertheless, note that should you mix many adapters, the resulting merged adapter can have a big size because of concatenation resulting in OOM. So, when exploring few adapters,catcan be place to begin. - In you desire to explore or
catisn’t working, trylinear,maginuted_pruneanddare_linearin that order. Formaginuted_pruneanddare_linear, we found that higherdensityvalues around 0.7-0.8 work higher. - When using
ties, we found that in lots of casesmajority_sign_method="frequency"to perform higher thanmajority_sign_method="total"(totalis currently the default). For ties, default value fordensityis 0.5. You possibly can then try tuning this lower or higher based in your observations post merging the adapters. dare_tieswasn’t giving good results.- When working with Stable Diffusion LoRA adapters which have different ranks, you may try the
*svdfamily of methods. Note that these require more GPU memory and take around ~1.5 minutes to create the merged adapter because of the expensive SVD operations.ties_svdgave good result when combiningsubject+styleLoRAs as seen in an example above. When combining 2styleadapters,dare_linearwith highdensityortieswithmajority_sign_method="frequency"seems to work higher as seen within the examples above.
Acknowledgements
We’re grateful to Le Yu and Prateek Yadav, authors of DARE and TIES, for his or her generous feedback and guidance on the PR. To honor their efforts, we have now added them because the co-authors of the PR. Because of Prateek and Le for reviewing the blog post draft as well.
Useful links
- Editing Models with Task Arithmetic
- TIES-Merging: Resolving Interference When Merging Models
- Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch
- mergekit: Tools for merging pretrained large language models.
- PEFT integration in Diffusers
- Model merging guide for PEFT users
Citations
@inproceedings{
ilharco2023editing,
title={Editing models with task arithmetic},
creator={Gabriel Ilharco and Marco Tulio Ribeiro and Mitchell Wortsman and Ludwig Schmidt and Hannaneh Hajishirzi and Ali Farhadi},
booktitle={The Eleventh International Conference on Learning Representations },
12 months={2023},
url={https://openreview.net/forum?id=6t0Kwf8-jrj}
}
@inproceedings{
yadav2023tiesmerging,
title={{TIES}-Merging: Resolving Interference When Merging Models},
creator={Prateek Yadav and Derek Tam and Leshem Choshen and Colin Raffel and Mohit Bansal},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
12 months={2023},
url={https://openreview.net/forum?id=xtaX3WyCj1}
}
@misc{yu2023language,
title={Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch},
creator={Le Yu and Bowen Yu and Haiyang Yu and Fei Huang and Yongbin Li},
12 months={2023},
eprint={2311.03099},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{
mergekit,
creator = {Charles O. Goddard and contributors},
title = {mergekit},
12 months = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/arcee-ai/mergekit}}
}