
On this blog post, we outline the challenges and solutions involved in generating an artificial dataset with billions of tokens to duplicate Phi-1.5, resulting in the creation of Cosmopedia. Synthetic data has turn out to be a central topic in Machine Learning. It refers to artificially generated data, for example by large language models (LLMs), to mimic real-world data.
Traditionally, creating datasets for supervised fine-tuning and instruction-tuning required the costly and time-consuming means of hiring human annotators. This practice entailed significant resources, limiting the event of such datasets to just a few key players in the sector. Nevertheless, the landscape has recently modified. We have seen lots of of high-quality synthetic fine-tuning datasets developed, primarily using GPT-3.5 and GPT-4. The community has also supported this development with quite a few publications that guide the method for various domains, and address the associated challenges [1][2][3][4][5].
Figure 1. Datasets on Hugging Face hub with the tag synthetic.
Nevertheless, this is just not one other blog post on generating synthetic instruction-tuning datasets, a subject the community is already extensively exploring. We give attention to scaling from a few thousand to tens of millions of samples that may be used for pre-training LLMs from scratch. This presents a novel set of challenges.
Why Cosmopedia?
Microsoft pushed this field with their series of Phi models [6][7][8], which were predominantly trained on synthetic data. They surpassed larger models that were trained for much longer on web datasets. Phi-2 was downloaded over 617k times up to now month and is among the many top 20 most-liked models on the Hugging Face hub.
While the technical reports of the Phi models, comparable to the “Textbooks Are All You Need” paper, make clear the models’ remarkable performance and creation, they omit substantial details regarding the curation of their synthetic training datasets. Moreover, the datasets themselves should not released. This sparks debate amongst enthusiasts and skeptics alike. Some praise the models’ capabilities, while critics argue they could simply be overfitting benchmarks; a few of them even label the approach of pre-training models on synthetic data as « garbage in, garbage out». Yet, the concept of getting full control over the info generation process and replicating the high-performance of Phi models is intriguing and value exploring.
That is the motivation for developing Cosmopedia, which goals to breed the training data used for Phi-1.5. On this post we share our initial findings and discuss some plans to enhance on the present dataset. We delve into the methodology for creating the dataset, offering an in-depth have a look at the approach to prompt curation and the technical stack. Cosmopedia is fully open: we release the code for our end-to-end pipeline, the dataset, and a 1B model trained on it called cosmo-1b. This allows the community to breed the outcomes and construct upon them.
Behind the scenes of Cosmopedia’s creation
Besides the lack of expertise concerning the creation of the Phi datasets, one other downside is that they use proprietary models to generate the info. To deal with these shortcomings, we introduce Cosmopedia, a dataset of synthetic textbooks, blog posts, stories, posts, and WikiHow articles generated by Mixtral-8x7B-Instruct-v0.1. It comprises over 30 million files and 25 billion tokens, making it the most important open synthetic dataset up to now.
Heads up: In case you are anticipating tales about deploying large-scale generation tasks across lots of of H100 GPUs, in point of fact more often than not for Cosmopedia was spent on meticulous prompt engineering.
Prompts curation
Generating synthetic data may appear straightforward, but maintaining diversity, which is crucial for optimal performance, becomes significantly difficult when scaling up. Subsequently, it’s essential to curate diverse prompts that cover a wide selection of topics and minimize duplicate outputs, as we don’t wish to spend compute on generating billions of textbooks only to discard most because they resemble one another closely. Before we launched the generation on lots of of GPUs, we spent a number of time iterating on the prompts with tools like HuggingChat. On this section, we’ll go over the means of creating over 30 million prompts for Cosmopedia, spanning lots of of topics and achieving lower than 1% duplicate content.
Cosmopedia goals to generate an enormous quantity of high-quality synthetic data with broad topic coverage. In accordance with the Phi-1.5 technical report, the authors curated 20,000 topics to provide 20 billion tokens of synthetic textbooks while using samples from web datasets for diversity, stating:
We fastidiously chosen 20K topics to seed the generation of this latest synthetic data. In our generation prompts, we use samples from web datasets for diversity.
Assuming a mean file length of 1000 tokens, this means using roughly 20 million distinct prompts. Nevertheless, the methodology behind combining topics and web samples for increased diversity stays unclear.
We mix two approaches to construct Cosmopedia’s prompts: conditioning on curated sources and conditioning on web data. We discuss with the source of the info we condition on as “seed data”.
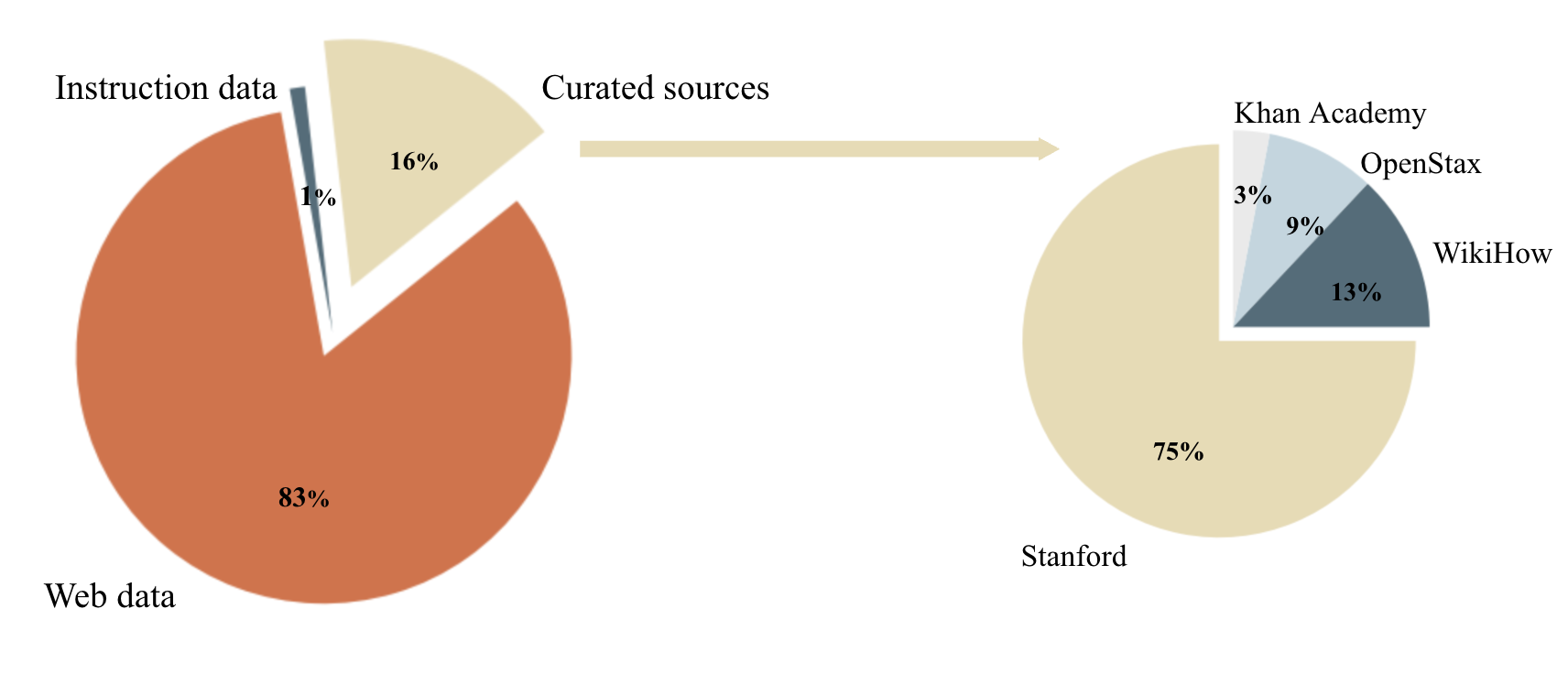
Figure 2. The distribution of information sources for constructing Cosmopedia prompts (left plot) and the distribution of sources contained in the Curated sources category (right plot).
Curated Sources
We use topics from reputable educational sources comparable to Stanford courses, Khan Academy, OpenStax, and WikiHow. These resources cover many useful topics for an LLM to learn. For example, we extracted the outlines of varied Stanford courses and constructed prompts that request the model to generate textbooks for individual units inside those courses. An example of such a prompt is illustrated in figure 3.
Although this approach yields high-quality content, its foremost limitation is scalability. We’re constrained by the variety of resources and the topics available inside each source. For instance, we will extract only 16,000 unique units from OpenStax and 250,000 from Stanford. Considering our goal of generating 20 billion tokens, we want at the very least 20 million prompts!
Leverage diversity in audience and elegance
One technique to increase the range of generated samples is to leverage the range of audience and elegance: a single topic may be repurposed multiple times by altering the target market (e.g., young children vs. college students) and the generation style (e.g., academic textbook vs. blog post). Nevertheless, we discovered that simply modifying the prompt from “Write an in depth course unit for a textbook on ‘Why Go To Space?’ intended for school students” to “Write an in depth blog post on ‘Why Go To Space?'” or “Write a textbook on ‘Why Go To Space?’ for young children” was insufficient to forestall a high rate of duplicate content. To mitigate this, we emphasized changes in audience and elegance, providing specific instructions on how the format and content should differ.
Figure 3 illustrates how we adapt a prompt based on the identical topic for various audiences.

Figure 3. Prompts for generating the identical textbook for young children vs for professionals and researchers vs for prime school students.
By targeting 4 different audiences (young children, highschool students, college students, researchers) and leveraging three generation styles (textbooks, blog posts, wikiHow articles), we will stand up to 12 times the variety of prompts. Nevertheless, we’d want to incorporate other topics not covered in these resources, and the small volume of those sources still limits this approach and may be very removed from the 20+ million prompts we’re targeting. That’s when web data turns out to be useful; what if we were to generate textbooks covering all the online topics? In the subsequent section, we’ll explain how we chosen topics and used web data to construct tens of millions of prompts.
Web data
Using web data to construct prompts proved to be essentially the most scalable, contributing to over 80% of the prompts utilized in Cosmopedia. We clustered tens of millions of web samples, using a dataset like RefinedWeb, into 145 clusters, and identified the subject of every cluster by providing extracts from 10 random samples and asking Mixtral to seek out their common topic. More details on this clustering can be found within the Technical Stack section.
We inspected the clusters and excluded any deemed of low educational value. Examples of removed content include explicit adult material, celebrity gossip, and obituaries. The total list of the 112 topics retained and people removed may be found here.
We then built prompts by instructing the model to generate a textbook related to an internet sample inside the scope of the subject it belongs to based on the clustering. Figure 4 provides an example of a web-based prompt. To boost diversity and account for any incompleteness in topic labeling, we condition the prompts on the subject only 50% of the time, and alter the audience and generation styles, as explained within the previous section. We ultimately built 23 million prompts using this approach. Figure 5 shows the ultimate distribution of seed data, generation formats, and audiences in Cosmopedia.

Figure 4. Example of an internet extract and the associated prompt.
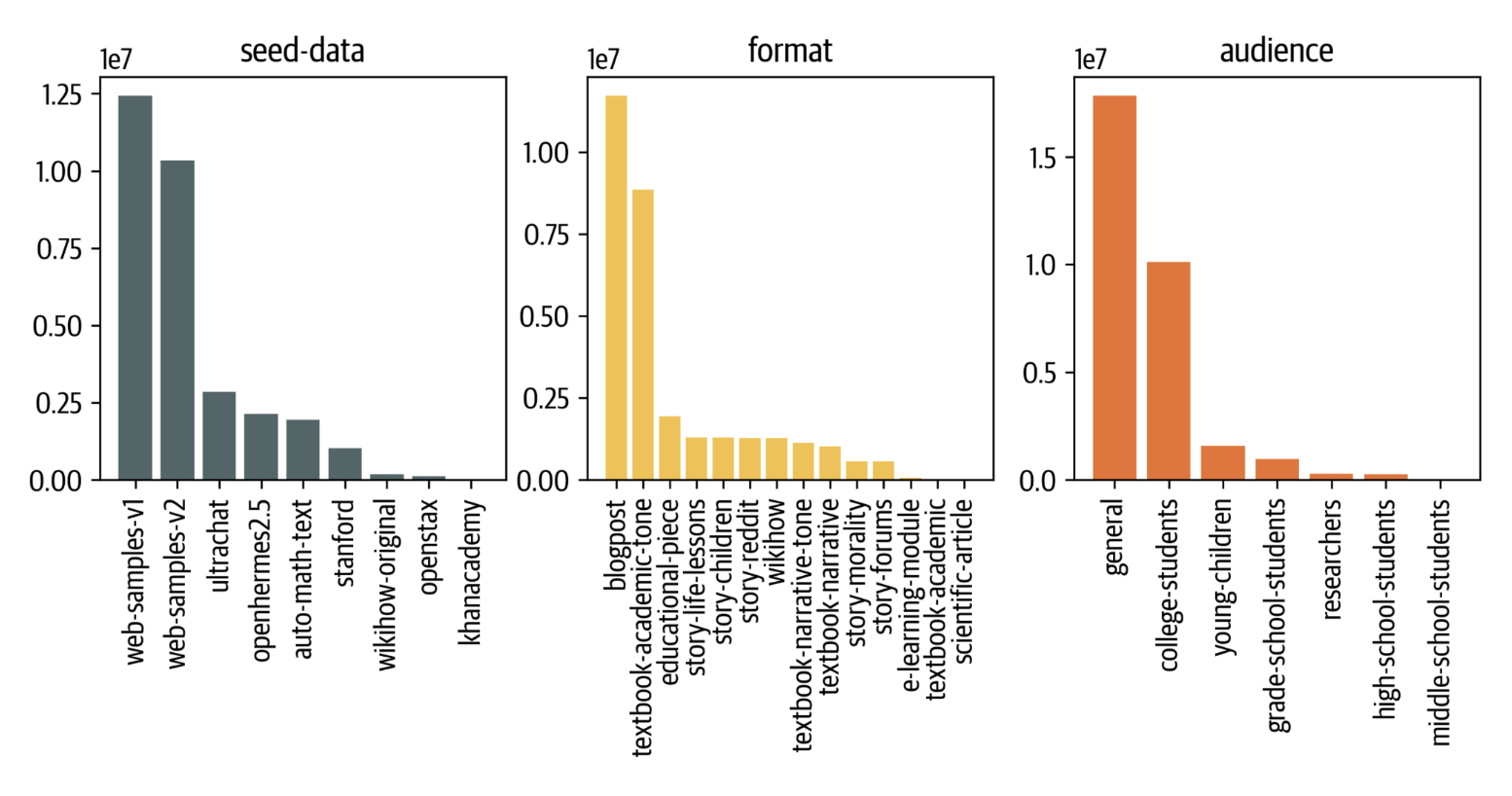
Figure 5. The distribution of seed data, generation format and goal audiences in Cosmopedia dataset.
Along with random web files, we used samples from AutoMathText, a fastidiously curated dataset of Mathematical texts with the goal of including more scientific content.
Instruction datasets and stories
In our initial assessments of models trained using the generated textbooks, we observed an absence of common sense and fundamental knowledge typical of grade school education. To deal with this, we created stories incorporating day-to-day knowledge and basic common sense using texts from the UltraChat and OpenHermes2.5 instruction-tuning datasets as seed data for the prompts. These datasets span a broad range of subjects. For example, from UltraChat, we used the “Questions on the world” subset, which covers 30 meta-concepts concerning the world. For OpenHermes2.5, one other diverse and high-quality instruction-tuning dataset, we omitted sources and categories unsuitable for storytelling, comparable to glaive-code-assist for programming and camelai for advanced chemistry. Figure 6 shows examples of prompts we used to generate these stories.

Figure 6. Prompts for generating stories from UltraChat and OpenHermes samples for young children vs a general audience vs reddit forums.
That is the tip of our prompt engineering story for constructing 30+ million diverse prompts that provide content with only a few duplicates. The figure below shows the clusters present in Cosmopedia, this distribution resembles the clusters in the online data. You may as well discover a clickable map from Nomic here.
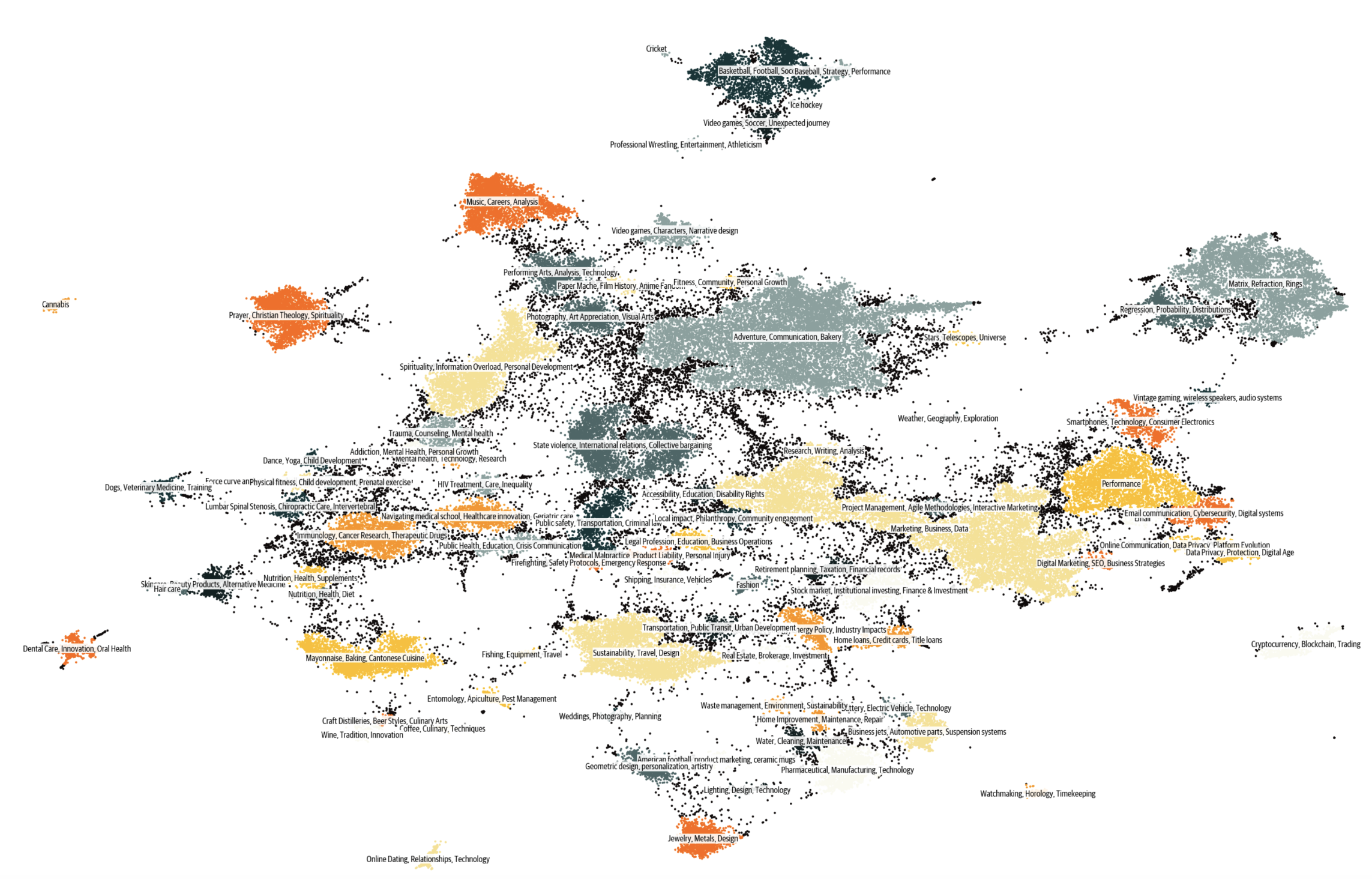
Figure 7. The clusters of Cosmopedia, annotated using Mixtral.
You should use the dataset viewer to analyze the dataset yourself:
Figure 8. Cosmopedia’s dataset viewer.
Technical stack
We release all of the code used to construct Cosmopedia in: https://github.com/huggingface/cosmopedia
On this section we’ll highlight the technical stack used for text clustering, text generation at scale and for training cosmo-1b model.
Topics clustering
We used text-clustering repository to implement the subject clustering for the online data utilized in Cosmopedia prompts. The plot below illustrates the pipeline for locating and labeling the clusters. We moreover asked Mixtral to present the cluster an academic rating out of 10 within the labeling step; this helped us within the topics inspection step. You’ll find a demo of the online clusters and their scores on this demo.
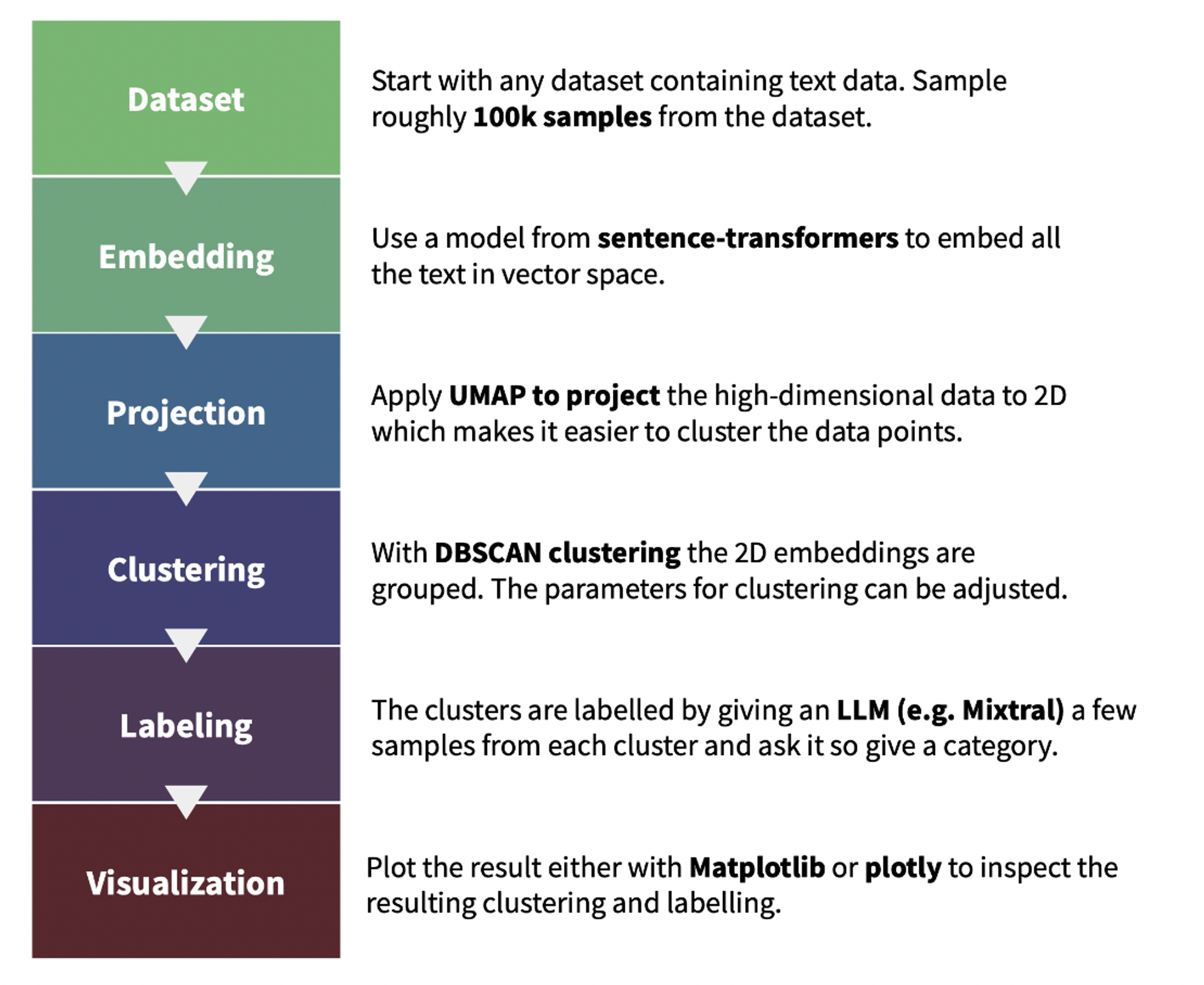
Figure 9. The pipeline of text-clustering.
Textbooks generation at scale
We leverage the llm-swarm library to generate 25 billion tokens of synthetic content using Mixtral-8x7B-Instruct-v0.1. It is a scalable synthetic data generation tool using local LLMs or inference endpoints on the Hugging Face Hub. It supports TGI and vLLM inference libraries. We deployed Mixtral-8x7B locally on H100 GPUs from the Hugging Face Science cluster with TGI. The full compute time for generating Cosmopedia was over 10k GPU hours.
Here’s an example to run generations with Mixtral on 100k Cosmopedia prompts using 2 TGI instances on a Slurm cluster:
cd llm-swarm
python ./examples/textbooks/generate_synthetic_textbooks.py
--model mistralai/Mixtral-8x7B-Instruct-v0.1
--instances 2
--prompts_dataset "HuggingFaceTB/cosmopedia-100k"
--prompt_column prompt
--max_samples -1
--checkpoint_path "./tests_data"
--repo_id "HuggingFaceTB/generations_cosmopedia_100k"
--checkpoint_interval 500
You’ll be able to even track the generations with wandb to watch the throughput and variety of generated tokens.
Figure 10. Wandb plots for an llm-swarm run.
Note:
We used HuggingChat for the initial iterations on the prompts. Then, we generated just a few hundred samples for every prompt using llm-swarm to identify unusual patterns. For example, the model used very similar introductory phrases for textbooks and continuously began stories with the identical phrases, like “Once upon a time” and “The sun hung low within the sky”. Explicitly asking the model to avoid these introductory statements and to be creative fixed the difficulty; they were still used but less continuously.
Benchmark decontamination
On condition that we generate synthetic data, there’s a possibility of benchmark contamination inside the seed samples or the model’s training data. To deal with this, we implement a decontamination pipeline to make sure our dataset is freed from any samples from the test benchmarks.
Just like Phi-1, we discover potentially contaminated samples using a 10-gram overlap. After retrieving the candidates, we employ difflib.SequenceMatcher to check the dataset sample against the benchmark sample. If the ratio of len(matched_substrings) to len(benchmark_sample) exceeds 0.5, we discard the sample. This decontamination process is applied across all benchmarks evaluated with the Cosmo-1B model, including MMLU, HellaSwag, PIQA, SIQA, Winogrande, OpenBookQA, ARC-Easy, and ARC-Challenge.
We report the variety of contaminated samples faraway from each dataset split, in addition to the variety of unique benchmark samples that they correspond to (in brackets):
| Dataset group | ARC | BoolQ | HellaSwag | PIQA |
|---|---|---|---|---|
| web data + stanford + openstax | 49 (16) | 386 (41) | 6 (5) | 5 (3) |
| auto_math_text + khanacademy | 17 (6) | 34 (7) | 1 (1) | 0 (0) |
| stories | 53 (32) | 27 (21) | 3 (3) | 6 (4) |
We discover lower than 4 contaminated samples for MMLU, OpenBookQA and WinoGrande.
Training stack
We trained a 1B LLM using Llama2 architecture on Cosmopedia to evaluate its quality: https://huggingface.co/HuggingFaceTB/cosmo-1b.
We used datatrove library for data deduplication and tokenization, nanotron for model training, and lighteval for evaluation.
The model performs higher than TinyLlama 1.1B on ARC-easy, ARC-challenge, OpenBookQA, and MMLU and is comparable to Qwen-1.5-1B on ARC-challenge and OpenBookQA. Nevertheless, we notice some performance gaps in comparison with Phi-1.5, suggesting a greater synthetic generation quality, which may be related to the LLM used for generation, topic coverage, or prompts.
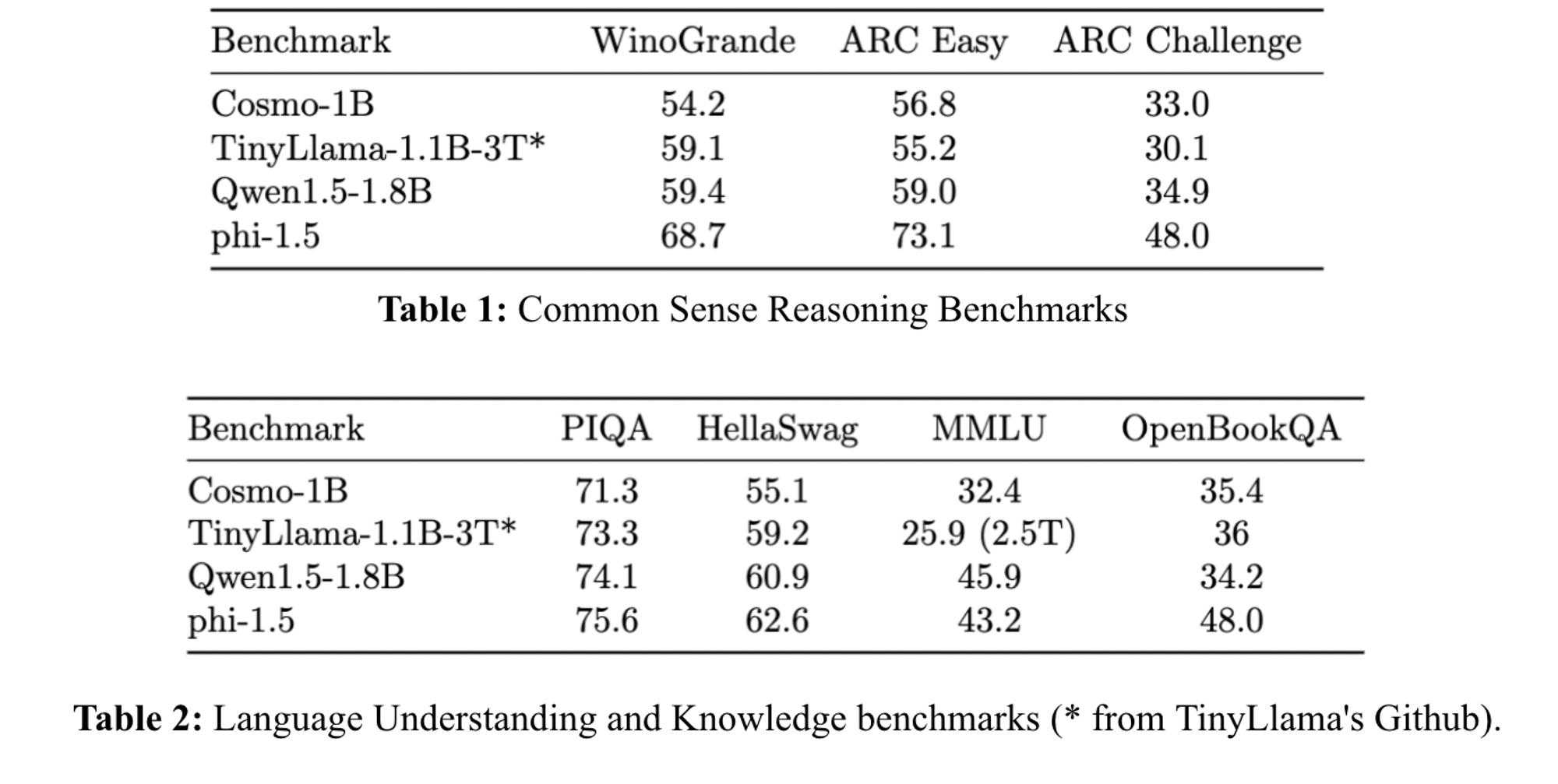
Figure 10. Evaluation results of Cosmo-1B.
Conclusion & next steps
On this blog post, we outlined our approach for creating Cosmopedia, a big synthetic dataset designed for pre-training models, with the goal of replicating the Phi datasets. We highlighted the importance of meticulously crafting prompts to cover a wide selection of topics, ensuring the generation of diverse content. Moreover, now we have shared and open-sourced our technical stack, which allows for scaling the generation process across lots of of GPUs.
Nevertheless, that is just the initial version of Cosmopedia, and we’re actively working on enhancing the standard of the generated content. The accuracy and reliability of the generations largely depends upon the model utilized in the generation. Specifically, Mixtral may sometimes hallucinate and produce misinformation, for instance with regards to historical facts or mathematical reasoning inside the AutoMathText and KhanAcademy subsets. One technique to mitigate the difficulty of hallucinations is using retrieval augmented generation (RAG). This involves retrieving information related to the seed sample, for instance from Wikipedia, and incorporating it into the context. Hallucination measurement methods could also help assess which topics or domains suffer essentially the most from it [9]. It will even be interesting to check Mixtral’s generations to other open models.
The potential for synthetic data is immense, and we’re desperate to see what the community will construct on top of Cosmopedia.
References
[1] Ding et al. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. URL https://arxiv.org/abs/2305.14233
[2] Wei et al. Magicoder: Source Code Is All You Need. URL https://arxiv.org/abs/2312.02120
[3] Toshniwal et al. OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset. URL https://arxiv.org/abs/2402.10176
[4] Xu et al. WizardLM: Empowering Large Language Models to Follow Complex Instructions. URL https://arxiv.org/abs/2304.12244
[5] Moritz Laurer. Synthetic data: get monetary savings, time and carbon with open source. URL https://huggingface.co/blog/synthetic-data-save-cost
[6] Gunasekar et al. Textbooks Are All You Need. URL https://arxiv.org/abs/2306.11644
[7] Li et al. Textbooks are all you wish ii: phi-1.5 technical report. URL https://arxiv.org/abs/2309.05463
[8] Phi-2 blog post. URL https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
[9] Manakul, Potsawee and Liusie, Adian and Gales, Mark JF. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. URL https://arxiv.org/abs/2303.08896