
that linear models will be… well, stiff. Have you ever ever checked out a scatter plot and realized a straight line just isn’t going to chop it? We’ve all been there.
Real-world data is all the time difficult. More often than not, it looks like the exception is the rule. The information you get in your job is nothing like those beautiful linear datasets that we used during years of coaching within the academy.
For instance, you’re something like “Energy Demand vs. Temperature.” It’s not a line; it’s a curve. Often, our first instinct is to succeed in for Polynomial Regression. But that’s a trap!
For those who’ve ever seen a model curve go wild at the perimeters of your graph, you’ve witnessed the “Runge Phenomenon.” High-degree polynomials are like a toddler with a crayon, since they’re too flexible and don’t have any discipline.
That’s why I’m going to point out you this selection called Splines. They’re a neat solution: more flexible than a line, but way more disciplined than a polynomial.
Splines are mathematical functions defined by polynomials, and used to smooth a curve.
As a substitute of attempting to fit one complex equation to your entire dataset, you break the information into segments at points called knots. Each segment gets its own easy polynomial, they usually’re all stitched together so easily you’ll be able to’t even see the seams.
The Problem with Polynomials
Imagine we have now a non-linear trend, and we apply a polynomial or to it. It looks okay locally, but then we take a look at the perimeters of your data, and the curve goes way off. In response to Runge’s Phenomenon [2], high-degree polynomials have this problem where one weird data point at one end can pull all the curve out of whack at the opposite end.
Why Splines are the “Just Right” Alternative
Splines don’t attempt to fit one giant equation to all the things. As a substitute, they divide your data into segments using points called knots. We have now some benefits of using knots.
- Local Control: What happens in a single segment stays in that segment. Because these chunks are local, a weird data point at one end of your graph won’t damage the fit at the opposite end.
- Smoothness: They use “B-splines” (Basis splines) to make sure that where segments meet, the curve is perfectly smooth.
- Stability: Unlike polynomials, they don’t go wild on the boundaries.
Okay. Enough talk, now let’s implement this solution.
Implementing it with Scikit-Learn
Scikit-Learn’s SplineTransformer is the go-to selection for this. It turns a single numeric feature into multiple that a straightforward linear model can then use to learn complex, non-linear shapes.
Let’s import some modules.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import SplineTransformer
from sklearn.linear_model import Ridge
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCVNext, we create some curved oscillating data.
# 1. Create some 'wiggly' synthetic data (e.g., seasonal sales)
rng = np.random.RandomState(42)
X = np.sort(rng.rand(100, 1) * 10, axis=0)
y = np.sin(X).ravel() + rng.normal(0, 0.1, X.shape[0])
# Plot the information
plt.figure(figsize=(12, 5))
plt.scatter(X, y, color='gray', alpha=0.5, label='Data')
plt.legend()
plt.title("Data")
plt.show()
Okay. Now we’ll create a pipeline that runs the SplineTranformer with the default settings, followed by a Ridge Regression.
# 2. Construct a pipeline: Splines + Linear Model
# n_knots=5 (default) creates 4 segments; degree=3 makes it a cubic spline
model = make_pipeline(
SplineTransformer(n_knots=5, degree=3),
Ridge(alpha=0.1)
)Next, we’ll tune the variety of knots for our model. We use GridSearchCV to run multiple versions of the model, testing different knot counts until it finds the one which performs best on our data.
# We tune 'n_knots' to search out the very best tune
param_grid = {'splinetransformer__n_knots': range(3, 12)}
grid = GridSearchCV(model, param_grid, cv=5)
grid.fit(X, y)
print(f"Best knot count: {grid.best_params_['splinetransformer__n_knots']}")Best knot count: 8Then, we retrain our spline model with the predict, and plot the information. Also, allow us to understand what we’re doing here with this quick breakdown of the SplineTransformer class arguments:
n_knots: variety of joints within the curve. The more you might have, the more flexible the curve gets.degree: This defines the “smoothness” of the segments. It refers back to the degree of the polynomial used between knots (1 is a line; 2 is smoother; 3 is the default).knots: This one tells the model to put the joints. For instance,uniformseparates the curve into equal spaces, while quantile allocates more knots where the information is denser.- Tip: Use
'quantile'in case your data is clustered.
- Tip: Use
extrapolation: Tells the model what it should do when it encounters data the range it saw during training.- Tip: use
'periodic'for cyclic data, reminiscent of calendar or clock.
- Tip: use
include_bias: Whether to incorporate a “bias” column (a column of all ones). For those who are using aLinearRegressionorRidgemodel later in your pipeline, those models normally have their very ownfit_intercept=True, so you’ll be able to often set this toFalseto avoid redundancy.
# 2. Construct the optimized Spline
model = make_pipeline(
SplineTransformer(n_knots=8,
degree=3,
knots= 'uniform',
extrapolation='constant',
include_bias=False),
Ridge(alpha=0.1)
).fit(X, y)
# 3. Predict and Visualize
y_plot = model.predict(X)
# Plot
plt.figure(figsize=(12, 5))
plt.scatter(X, y, color='gray', alpha=0.5, label='Data')
plt.plot(X, y_plot, color='teal', linewidth=3, label='Spline Model')
plt.plot(X, y_plot_10, color='purple', linewidth=2, label='Polynomial Fit (Degree 20)')
plt.legend()
plt.title("Splines: Flexible yet Disciplined")
plt.show()Here is the result. With splines, we have now higher control and a smoother model, escaping the issue on the ends.
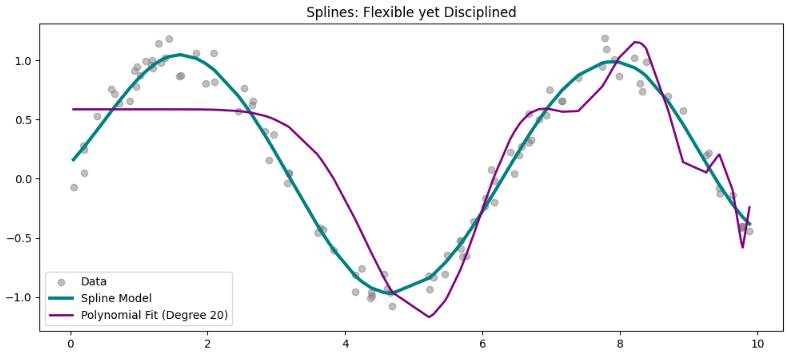
We’re comparing a polynomial model of degree=20 with the spline model. One can argue that lower degrees can do a significantly better modeling of this data, and they might be correct. I even have tested as much as the thirteenth degree, and it matches well with this dataset.
Nonetheless, that is strictly the purpose of this text. When the model isn’t fitting too well to the information, and we want to maintain increasing the polynomial degree, we actually will fall into the problem.
Real-Life Applications
Where would you really use this in business?
- Time-Series Cycles: Use
extrapolation='periodic'for features like “hour of day” or “month of yr.” It ensures the model knows that 11:59 PM is correct next to 12:01 AM. With this argument, we tell theSplineTransformerthat the tip of our cycle (hour 23) should wrap around and meet the start (hour 0). Thus, the spline ensures that the slope and value at the tip of the day perfectly match the beginning of the subsequent day. - Dose-Response in Medicine: Modeling how a drug affects a patient. Most drugs follow a non-linear curve where the profit eventually levels off (saturation) or, worse, turns into toxicity. Splines are the “gold standard” here because they’ll map these complex biological shifts without forcing the information right into a rigid shape.
- Income vs. Experience: Salary often grows quickly early on after which plateaus; splines capture this “bend” perfectly.
Before You Go
We’ve covered loads here, from why polynomials is usually a “wild” selection to how periodic splines solve the midnight gap. Here’s a fast wrap-up to maintain in your back pocket:
- The Golden Rule: Use Splines when a straight line is simply too easy, but a high-degree polynomial starts oscillating and overfitting.
- Knots are Key: Knots are the “joints” of your model. Finding the precise number via
GridSearchCVis the difference between a smooth curve and a jagged mess. - Periodic Power: For any feature that cycles (hours, days, months), use
extrapolation='periodic'. It ensures the model understands that the tip of the cycle flows perfectly back into the start. - Feature Engineering > Complex Models: Often, a straightforward
Ridgeregression combined withSplineTransformerwill outperform a posh “Black Box” model while remaining much easier to clarify to your boss.
For those who liked this content, find more about my work and my contacts on my website.
GitHub Repository
Here is the whole code of this exercise, and a few extras.
https://github.com/gurezende/Studying/blob/master/Python/sklearn/SplineTransformer.ipynb
References
[1. SplineTransformer Documentation] https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.SplineTransformer.html
[2. Runge’s Phenomenon] https://en.wikipedia.org/wiki/Runge%27s_phenomenon
[3. Make Pipeline Docs] https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.make_pipeline.html