
Today, integrating AI-powered features, particularly leveraging Large Language Models (LLMs), has change into increasingly prevalent across various tasks equivalent to text generation, classification, image-to-text, image-to-image transformations, etc.
Developers are increasingly recognizing these applications’ potential advantages, particularly in enhancing core tasks equivalent to scriptwriting, web development, and, now, interfacing with data. Historically, crafting insightful SQL queries for data evaluation was primarily the domain of information analysts, SQL developers, data engineers, or professionals in related fields, all navigating the nuances of SQL dialect syntax. Nevertheless, with the arrival of AI-powered solutions, the landscape is evolving. These advanced models offer latest avenues for interacting with data, potentially streamlining processes and uncovering insights with greater efficiency and depth.
What for those who could unlock fascinating insights out of your dataset without diving deep into coding? To glean precious information, one would wish to craft a specialized SELECT statement, considering which columns to display, the source table, filtering conditions for chosen rows, aggregation methods, and sorting preferences. This traditional approach involves a sequence of commands: SELECT, FROM, WHERE, GROUP, and ORDER.
But what for those who’re not a seasoned developer and still need to harness the ability of your data? In such cases, in search of assistance from SQL specialists becomes obligatory, highlighting a spot in accessibility and usefulness.
That is where groundbreaking advancements in AI and LLM technology step in to bridge the divide. Imagine conversing along with your data effortlessly, simply stating your information needs in plain language and having the model translate your request into a question.
In recent months, significant strides have been made on this arena. MotherDuck and Numbers Station unveiled their latest innovation: DuckDB-NSQL-7B, a state-of-the-art LLM designed specifically for DuckDB SQL. What is that this model’s mission? To empower users with the power to unlock insights from their data effortlessly.
Initially fine-tuned from Meta’s original Llama-2–7b model using a broad dataset covering general SQL queries, DuckDB-NSQL-7B underwent further refinement with DuckDB text-to-SQL pairs. Notably, its capabilities extend beyond crafting SELECT statements; it will probably generate a big selection of valid DuckDB SQL statements, including official documentation and extensions, making it a flexible tool for data exploration and evaluation.
In this text, we are going to learn the right way to take care of text2sql tasks using the DuckDB-NSQL-7B model, the Hugging Face dataset viewer API for parquet files and duckdb for data retrieval.
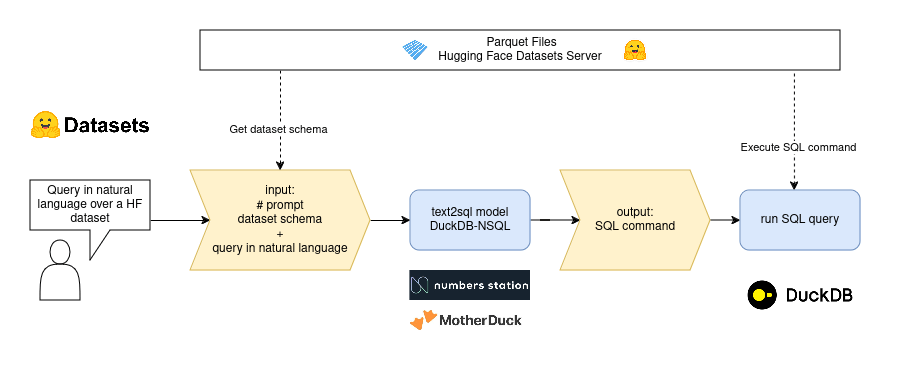
text2sql flow
Easy methods to use the model
- Using Hugging Face
transformerspipeline
from transformers import pipeline
pipe = pipeline("text-generation", model="motherduckdb/DuckDB-NSQL-7B-v0.1")
- Using transformers tokenizer and model
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("motherduckdb/DuckDB-NSQL-7B-v0.1")
model = AutoModelForCausalLM.from_pretrained("motherduckdb/DuckDB-NSQL-7B-v0.1")
- Using
llama.cppto load the model inGGUF
from llama_cpp import Llama
llama = Llama(
model_path="DuckDB-NSQL-7B-v0.1-q8_0.gguf",
n_gpu_layers=-1,
)
The fundamental goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide selection of hardware – locally and within the cloud. We’ll use this approach.
Hugging Face Dataset Viewer API for greater than 120K datasets
Data is a vital component in any Machine Learning endeavor. Hugging Face is a precious resource, offering access to over 120,000 free and open datasets spanning various formats, including CSV, Parquet, JSON, audio, and image files.
Each dataset hosted by Hugging Face comes equipped with a comprehensive dataset viewer. This viewer provides users essential functionalities equivalent to statistical insights, data size assessment, full-text search capabilities, and efficient filtering options. This feature-rich interface empowers users to simply explore and evaluate datasets, facilitating informed decision-making throughout the machine learning workflow.
For this demo, we will likely be using the world-cities-geo dataset.
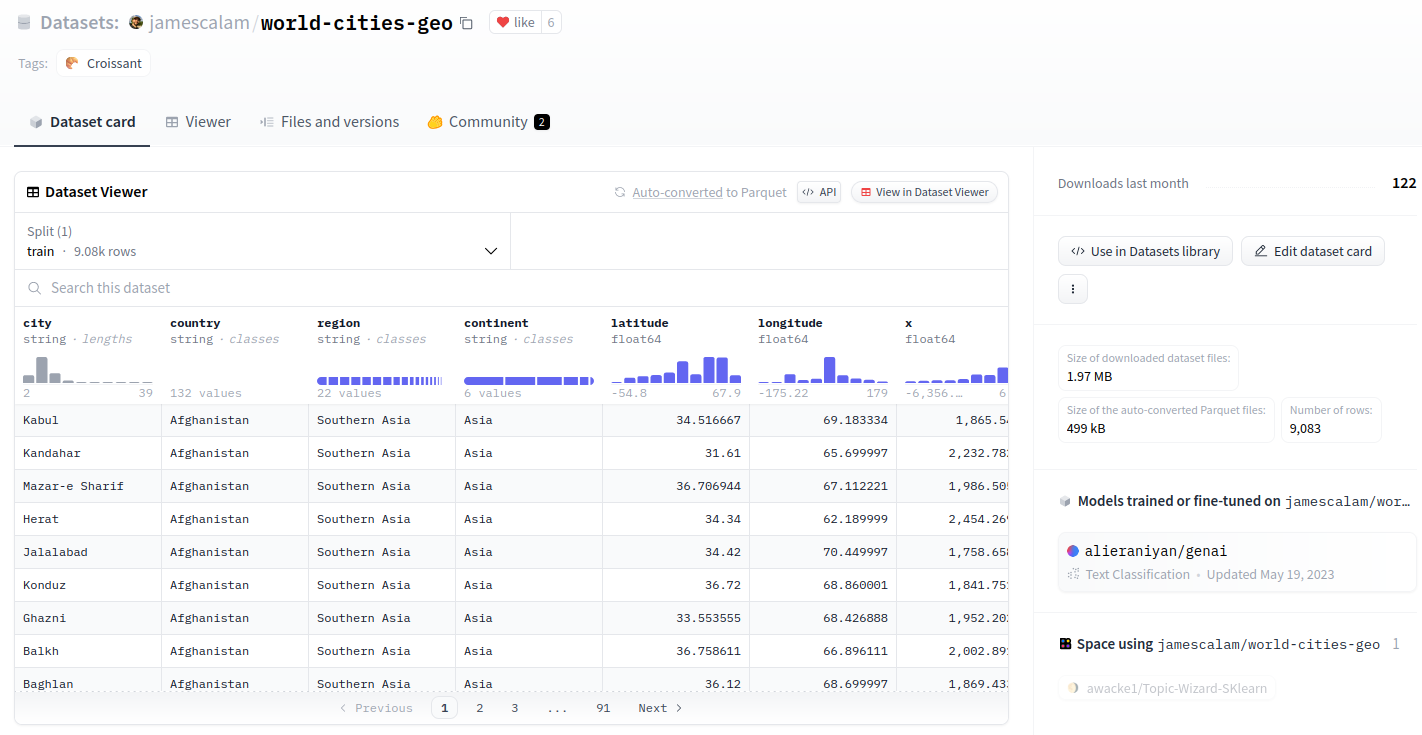
Dataset viewer of world-cities-geo dataset
Behind the scenes, each dataset within the Hub is processed by the Hugging Face dataset viewer API, which gets useful information and serves functionalities like:
- List the dataset splits, column names and data types
- Get the dataset size (in variety of rows or bytes)
- Download and look at rows at any index within the dataset
- Search a word within the dataset
- Filter rows based on a question string
- Get insightful statistics in regards to the data
- Access the dataset as parquet files to make use of in your favorite processing or analytics framework
On this demo, we are going to use the last functionality, auto-converted parquet files.
Generate SQL queries from text instructions
First, download the quantized models version of DuckDB-NSQL-7B-v0.1
Downloading the model
Alternatively, you may execute the next code:
huggingface-cli download motherduckdb/DuckDB-NSQL-7B-v0.1-GGUF DuckDB-NSQL-7B-v0.1-q8_0.gguf --local-dir . --local-dir-use-symlinks False
Now, lets install the needed dependencies:
pip install llama-cpp-python
pip install duckdb
For the text-to-SQL model, we are going to use a prompt with the next structure:
### Instruction:
Your task is to generate valid duckdb SQL to reply the next query.
### Input:
Here is the database schema that the SQL query will run on:
{ddl_create}
### Query:
{query_input}
### Response (use duckdb shorthand if possible):
- ddl_create will likely be the dataset schema as a SQL
CREATEcommand - query_input will likely be the user instructions, expressed with natural language
So, we want to inform to the model in regards to the schema of the Hugging Face dataset. For that, we’re going to get the primary parquet file for jamescalam/world-cities-geo dataset:
GET https://huggingface.co/api/datasets/jamescalam/world-cities-geo/parquet
{
"default":{
"train":[
"https://huggingface.co/api/datasets/jamescalam/world-cities-geo/parquet/default/train/0.parquet"
]
}
}
The parquet file is hosted in Hugging Face viewer under refs/convert/parquet revision:
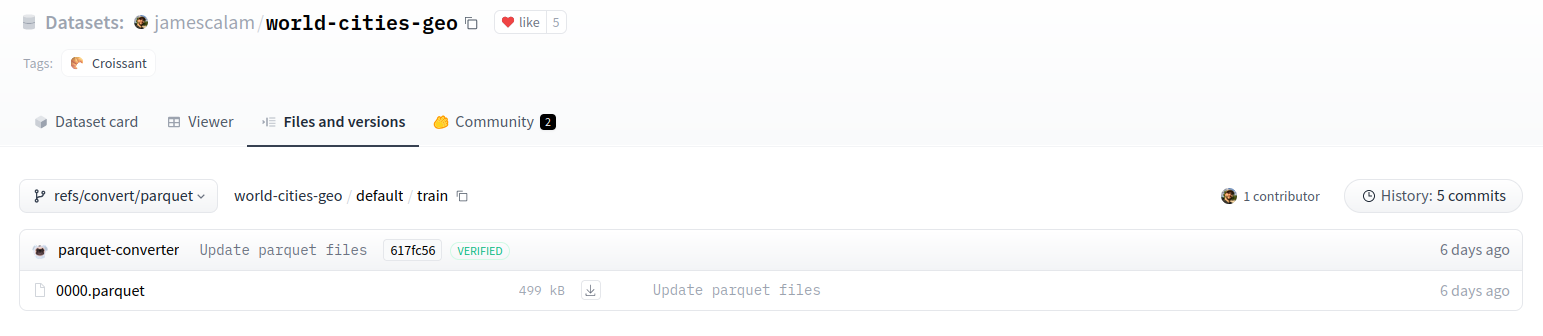
Parquet file
- Simulate a DuckDB table creation from the primary row of the parquet file
import duckdb
con = duckdb.connect()
con.execute(f"CREATE TABLE data as SELECT * FROM '{first_parquet_url}' LIMIT 1;")
result = con.sql("SELECT sql FROM duckdb_tables() where table_name="data";").df()
ddl_create = result.iloc[0,0]
con.close()
The CREATE schema DDL is:
CREATE TABLE "data"(
city VARCHAR,
country VARCHAR,
region VARCHAR,
continent VARCHAR,
latitude DOUBLE,
longitude DOUBLE,
x DOUBLE,
y DOUBLE,
z DOUBLE
);
And, as you may see, it matches the columns within the dataset viewer:

Dataset columns
- Now, we will construct the prompt with the ddl_create and the query input
prompt = """### Instruction:
Your task is to generate valid duckdb SQL to reply the next query.
### Input:
Here is the database schema that the SQL query will run on:
{ddl_create}
### Query:
{query_input}
### Response (use duckdb shorthand if possible):
"""
If the user desires to know the Cities from Albania country, the prompt will appear like this:
query = "Cities from Albania country"
prompt = prompt.format(ddl_create=ddl_create, query_input=query)
So the expanded prompt that will likely be sent to the LLM looks like this:
### Instruction:
Your task is to generate valid duckdb SQL to reply the next query.
### Input:
Here is the database schema that the SQL query will run on:
CREATE TABLE "data"(city VARCHAR, country VARCHAR, region VARCHAR, continent VARCHAR, latitude DOUBLE, longitude DOUBLE, x DOUBLE, y DOUBLE, z DOUBLE);
### Query:
Cities from Albania country
### Response (use duckdb shorthand if possible):
- It’s time to send the prompt to the model
from llama_cpp import Llama
llm = Llama(
model_path="DuckDB-NSQL-7B-v0.1-q8_0.gguf",
n_ctx=2048,
n_gpu_layers=50
)
pred = llm(prompt, temperature=0.1, max_tokens=1000)
sql_output = pred["choices"][0]["text"]
The output SQL command will point to a data table, but since we haven’t got an actual table but only a reference to the parquet file, we are going to replace all data occurrences by the first_parquet_url:
sql_output = sql_output.replace("FROM data", f"FROM '{first_parquet_url}'")
And the ultimate output will likely be:
SELECT city FROM 'https://huggingface.co/api/datasets/jamescalam/world-cities-geo/parquet/default/train/0.parquet' WHERE country = 'Albania'
- Now, it’s time to finally execute our generated SQL directly within the dataset, so, lets use once more DuckDB powers:
con = duckdb.connect()
try:
query_result = con.sql(sql_output).df()
except Exception as error:
print(f"❌ Couldn't execute SQL query {error=}")
finally:
con.close()
And here now we have the outcomes (100 rows):

Execution result (100 rows)
Let’s compare this result with the dataset viewer using the “search function” for Albania country, it must be the identical:
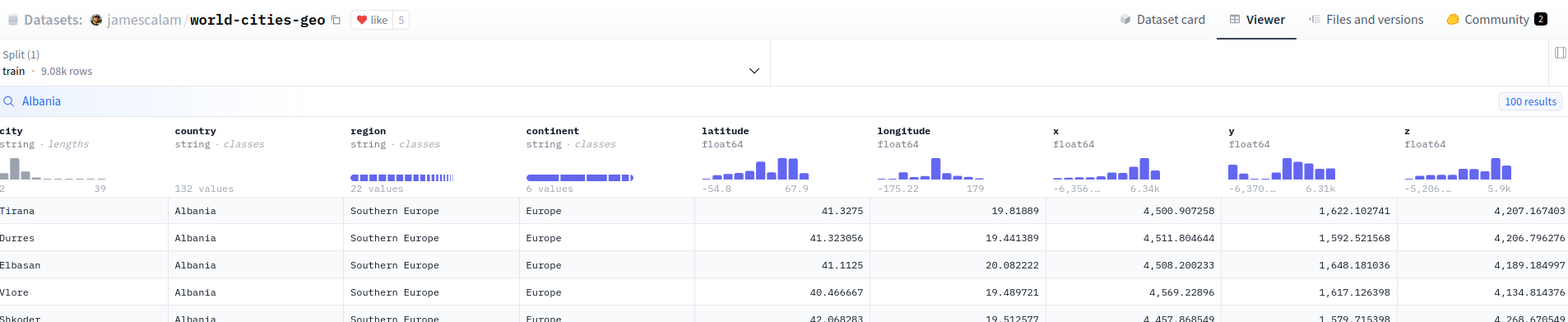
Search result for Albania country
You can even get the identical result calling on to the search or filter API:
import requests
API_URL = "https://datasets-server.huggingface.co/search?dataset=jamescalam/world-cities-geo&config=default&split=train&query=Albania"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
import requests
API_URL = "https://datasets-server.huggingface.co/filter?dataset=jamescalam/world-cities-geo&config=default&split=train&where=country='Albania'"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
Our final demo will likely be a Hugging Face space that appears like this:
You possibly can see the notebook with the code here.
And the Hugging Face Space here