
It is a guest blog post authored by Digital Green. Digital green is participating in a CGIAR-led collaboration to bring agricultural support to smallholder farmers.
There are an estimated 500 million smallholder farmers globally: they play a critical role in global food security. Timely access to accurate information is crucial for these farmers to make informed decisions and improve their yields.
An “agricultural extension service” offers technical advice on agriculture to farmers, and in addition supplies them with the obligatory inputs and services to support their agricultural production.
Agriculture extension agents are 300K in India alone, they supply obligatory details about improved agriculture practice and assist in decision making for the smallholder farmers.
But although their number is impressive, extension employees usually are not in large enough numbers to address all of the demand: they interact with farmers at typically within the ratio of 1:1000. Reaching the agriculture extension employees and farmers through partnership and technology stays the important thing.
Enter project GAIA, a collaborative initiative pioneered by CGIAR.
It brought together Hugging Face as mentor through the Expert Support program, and Digital Green as project partner.
GAIA has a lofty goal to bring years of agriculture knowledge in the shape of research papers meticulously maintained in GARDIAN portal within the hands of the farmers. There are near 46000 research papers and reports which have agricultural knowledge globally carried over multiple many years across different crops.
Digital Green immediately saw the potential of developing intelligent chatbots powered by Retrieval-Augmented Generation (RAG) on approved, curated information. Thus they decided to develop Farmer.chat, a chatbot that leverages the capabilities of enormous language models (LLMs) to deliver personalized and reliable agricultural advice to the farmers and front line extension employees.
Creating such a chatbot for an enormous number of languages, geographies, crops, and use cases, is a huge challenge: information disseminated needs to be contextual to the local level details in regards to the farm, within the language and tone that farmers can understand and accurate (grounded in trustworthy sources) for farmers to act on it. To guage the performance of the system, the CGIAR team and HF expert collaborated to establish a robust evaluation suite, in the shape of an LLM-as-a-judge system.
Let’s take a take a look at how they tackled this challenge!
System architecture
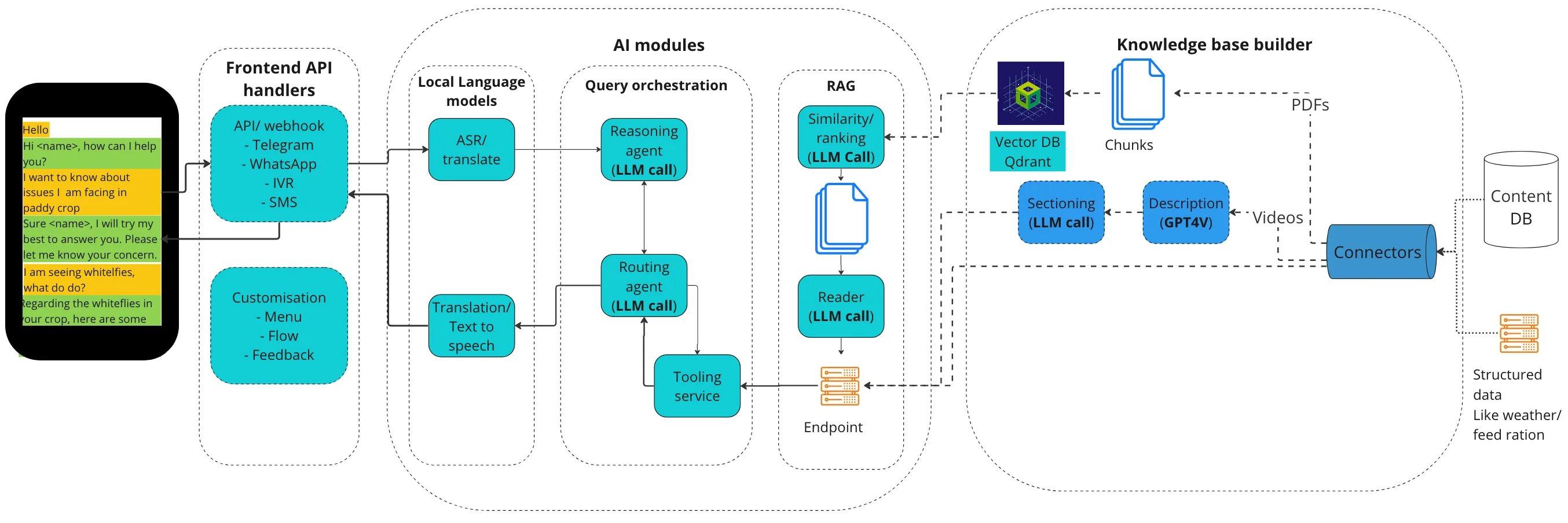
The total system uses many components with a view to provide chatbot answers grounded in several tools and external knowledge. It has several key elements:
- Knowledge base:
- Preprocessing: Step one was to ingest the pdf documents into the Farmer.chat pipeline with the assistance of APIs maintained by Scio. The within the knowledge base, topics were auto categorized for relevant geographic areas and semantically grouped together.
- Semantic chunking: the organized files with metadata are processed with sentences similar in meaning grouped together in text chunks. The function uses small-text embedding currently for cosine similarity
- Conversion into VectorDB format: each text chunk is converted into vector representation using an embedding model using which the vector representation is stored in QdrantDB.
- RAG pipeline: It’s what ensures that the data delivered is grounded within the content and never outside. It consists in two parts:
- Information retrieval: Searching the knowledge base for relevant information that matches the user’s query. This involves calling the vector database API created in knowledge base builder to get obligatory text chunks.
- Generation: Using the retrieved information within the text chunks and the user query, the generator calls LLM and generates a human-like response that addresses the user’s needs.
- User-facing Agent: The planning agent leverages GPT-4o under the hood.
- Its task is to:
- Understand the user intent
- Based on the user intent and tools description resolve what more information is required
- Ask that information from the user till the ask is obvious
- Once the ask is obvious, call the execution agent
- Get the response form the execution agent and generate response
- The agent runs a ReAct based prompt to think in step-by-step manner and call the respective tools and analyze the responses. Then it may well leverage its tools to reply: Currently, the agent uses the next set of tools:
- Converse more
- RAG QA endpoint
- Video retrieval endpoint
- Weather endpoint
- Crop table
- Its task is to:
Now this technique has many moving parts, and every part has a radical impart on some facets of performance. So we’d like to rigorously run performance evaluation.
Within the last one yr, the usage of Farmer.chat has grown to service greater than 20k farmers handling over 340k queries. How can we evaluate the performance of the system at this scale?
During weekly brainstorming sessions, Hugging Face hinted to LLM as a judge and provided a link to their notebook LLM as a Judge. This resource was discussed intimately, and what followed became a practice that has helped navigating Farmer.chat’s development.
The Power of LLMs-as-Judges
Farmer.Chat employs a classy Retrieval-Augmented Generation (RAG) pipeline to deliver accurate and relevant information to farmers that’s grounded within the knowledge base.
The RAG pipeline uses an LLM to retrieve information from an enormous knowledge base after which generate a concise and informative response.
But how will we measure the effectiveness of this pipeline?
The problem here is that there isn’t any deterministic metric that one could use to rate the standard of a solution, its conciseness, its precision…
That’s where LLM-as-a-judge technique steps in. The thought is straightforward: ask an LLM to rate the output on any metric.
The immense advantage is that the metric might be anything: LLM-as-a-Judge is incredibly versatile.
For instance, you should use it to guage the clarity of a prompt as follows:
You can be given a user input about agriculture, and your task is to attain it on various facets.
Think step-by-step and rate the user input on all three following criteria and provides a rating for every:
1) The intent and ask is obvious.
2) The subject is well-specified.
3) The goal entity is well-specified, in addition to its attributes, as an illustration "disease resistant" or "high yield".
You must give your scores on an integer scale of 1 to three, 1 being the worst and three one of the best rating.
After making a rating for every three, take the common and round it off to the closest integer which becomes the ultimate rating.
Example:
User input: "tell the advantages of batian coffee variety"
Criterion 1: scores 3, because the intent is obvious (about knowing about batian number of coffee) and the ask is obvious (need to summarize the advantages).
Criterion 2: scores 3, the subject is well specified (coffee varieties)
Criterion 3: scores 2, because the entity is obvious (batian variety) but not the attributes.
As mentioned in this text that we referred to earlier, the important thing to make use of LLM-as-a-judge is to obviously define the duty, the factors and the integer rating scale.
The research team behind Farmer.Chat leverages the capabilities of LLMs to guage several crucial metrics:
- Prompt Clarity: This metric evaluates how well users can articulate their questions. LLMs are trained to evaluate the clarity of user intent, topic specificity, and entity-attribute identification, providing insights into how effectively users can communicate their needs.
- Query Type: This metric classifies user questions into different categories based on their cognitive complexity. LLMs analyze the user’s query and assign it to one in all six categories, similar to “remember,” “understand,” “apply,” “analyze,” “evaluate,” and “create,” helping us understand the cognitive demands of user interactions.
- Answered Queries: This metric tracks the proportion of questions answered by the chatbot, providing insights into the breadth of the knowledge base and the platform’s ability to deal with a wide selection of queries.
- RAG Accuracy: This metric assesses the faithfulness and relevance of the data retrieved by the RAG pipeline. The LLM acts as a judge, comparing the retrieved information to the user’s query and evaluating whether the response is accurate and relevant.
It empowers us to transcend simply measuring what number of questions a chatbot can answer or how quickly it responds.
As a substitute, we are able to delve deeper into the standard of the responses and understand the user experience in a more nuanced way.
For RAG accuracy we use LLM-as-a-judge to guage on a binary scale: zero or one.
But the way in which the duty is broken down results in a well established process that comes up with a rating that we tested with human evaluators on roughly 360 questions: LLM answers are found to truly do an amazing job and have high correlation with human evaluations!
Here is the prompt, which was inspired from the RAGAS library.
You're a natural language inference engine. You can be presented with a set of factual statements and context. You're alleged to analyze if each statement is factually correct given the context. You possibly can give you the scores of 'Yes' (1) and 'No' (0) as verdict.
Use the next rules:
If the statement might be derived from the context, give a rating of 1.
If there isn't any statement and there isn't any context, give a rating of 1.
If the statement can’t be derived from the context, give a rating of 0.
If there isn't any context but there's an announcement, give a rating of 0.
#### Input :
Context : {context}
Statements : {statements}
The context variable above is the input chunks given for generating the answers while statements are the atomic factual statements generated by one other LLM call.
This was a vital step because it enables evaluation at scale which is significant when coping with large numbers of documents and queries.
The LLM-as-a-judge at core results in metrics that act as a compass navigating the varied options available for our AI pipeline.
Results: benchmarking LLMs for RAG
We created a sample dataset of > 700 user queries randomized across different value chains (crops) and date (months). While this upgrade itself had 11 different versions that evaluated using RAG accuracy and percentage answered, the identical approach was used to measure performance of the leading LLMs with none prompt changes in each LLM call. For this experiment, we chosen GPT-4-Turbo by OpenAI, Gemini-1.5 in Pro and Flash versions, and Llama-3-70B-Instruct.
| LLM | Faithful | Relevant | Answered * Relevant | Answered * Faithful | Unanswered |
|---|---|---|---|---|---|
| GPT-4-turbo | 88% | 75% | 59% | 69% | 21.9% |
| Llama-3-70B | 78% | 76% | 76% | 78% | 0.3% |
| Gemini-1.5-Pro | 91% | 88% | 71% | 73% | 19.4% |
| Gemini-1.5-Flash | 89% | 78% | 74 % | 85% | 4.5% |
What we see is that amongst the 4 models, the best level of factually correct answers (“Faithful” column) is obtained with Gemini-1.5-pro, followed very closely by Gemini-1.5-Flash and GPT-4-turbo.
What we found was that purely on the premise of faithfulness, Gemini-1.5-Pro beats the opposite models. But when we also take into consideration which percentage of questions the model accepted to reply, Llama-3-70B and Gemini-1.5-Flash perform higher.
Ultimately, we picked Gemini-1.5-Flash on account of the superior trade-off of a low percentage of unanswered questions and really high faithfulness.
Conclusion
By leveraging LLMs as judges, we gain a deeper understanding of user behavior and the effectiveness of AI-powered tools within the agricultural context. This data-driven approach is crucial for:
- Improving user experience: By identifying areas where users struggle to articulate their needs or where the RAG pipeline will not be performing as expected, we are able to improve the design and functionality of the platform.
- Optimizing the knowledge base: The evaluation of unanswered queries helps us discover gaps within the knowledge base and prioritize content development.
- Choosing the best LLMs: By benchmarking different LLMs on key metrics, we are able to make informed decisions about which models are best fitted to specific tasks and contexts.
The flexibility of LLMs to act as judges in evaluating the performance of AI systems is a game-changer. It allows us to measure the impact of those systems in a more objective and data-driven way, ultimately resulting in the event of more robust, effective, and user-friendly AI tools for agriculture.
Within the span of over a yr, now we have repeatedly evolved our product. On this small timeframe now we have been capable of:
- Reach greater than 20k farmers
- Answer > 340k questions
- Serve > 6 languages, for 50 value chain crops
- Maintain near zero biases or toxic responses
The outcomes were published recently in this scientific article, specializing in the quantitative study of user research.
.gif)
Should you are excited by the Hugging Face Expert Support program in your company, don’t hesitate to contact us here – our sales team will get in contact to debate your needs!