
For machine learning engineers deploying LLMs at scale, the equation is familiar and unforgiving: as context length increases, attention computation costs explode. Whether you’re coping with retrieval-augmented generation (RAG) pipelines, agentic AI workflows, or long-form content generation, the 
This post explains a method often called Skip Softmax, a hardware-friendly, drop-in sparse attention method that accelerates inference with none retraining. Read on to learn the way Skip Softmax delivers as much as 1.4x faster time-to-first-token (TTFT), and as much as 1.4x faster time-per-output-token (TPOT), and how one can start with the technique in NVIDIA TensorRT-LLM.
How does Skip Softmax work?
At its core, Skip Softmax provides a dynamic approach to prune attention blocks. This is feasible because it exploits a fundamental property of the Softmax function: 
In standard FlashAttention, the GPU computes attention scores (logits) for blocks of queries (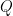

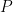
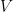
Nonetheless, attention is intrinsically sparse. For a lot of blocks, the eye scores are so low in comparison with the dominant tokens that their contribution to the ultimate output is statistically negligible. Skip Softmax modifies the FlashAttention loop to detect these blocks early and easily skips them.
The Skip Softmax algorithm
Implemented directly throughout the FlashAttention kernel, the logic follows this heuristic:
- Compute local max: Calculate the utmost logit for the present block (
).
- Compare to running max: Check if the difference between the present block’s local max (
) and the running global max (
) exceeds a calibrated threshold (
).
- Skip: If the condition is met, the kernel skips the softmax and BMM2 calculation for that block and, crucially, skips loading the
What are the advantages of using Skip Softmax?
Skip Softmax offers drop-in compatibility, hardware efficiency, flexibility, and flexibility.
Unlike approaches that need specific architectural modifications (comparable to Linear Attention), Skip Softmax is compatible with existing pretrained models that use standard attention mechanisms like MHA, GQA, or MLA. It’s optimized to leverage the precise tensor core and memory hierarchy of NVIDIA Hopper and NVIDIA Blackwell GPUs. It may well even be integrated with other optimization methods. As an example, combining XAttention during prefill with Skip Softmax during decoding has been shown to deliver substantial speed improvements without compromising accuracy.
Skip Softmax is flexible since it addresses bottlenecks in each the prefill and decode phases. Based on performance data on Hopper and Blackwell architectures, Skip Softmax is helpful during bandwidth-bound decoding and compute-bound prefilling, especially in long-context scenarios.
Bandwidth-bound decoding
In the course of the generation (decode) phase, LLM inference is often sure by memory bandwidth. The GPU spends more time moving KV cache data than computing.
- Profit: By identifying unimportant blocks early, Skip Softmax avoids loading the associated
- Data: On Llama 3.3 70B (NVIDIA GB200 NVL72), Skip Softmax achieves a projected 1.36x end-to-end speedup during decoding.
Compute-bound prefilling
In the course of the prefill phase (processing the input prompt), the system is compute-bound.
- Profit: Skipping the softmax and the second matrix multiplication (BMM2) saves significant FLOPs.
- Data: For a similar Llama 3.3 70B model (NVIDIA GB200 NVL72), prefill sees an estimated 1.4x end-to-end speedup at 128K context length.
Long-context scenarios
The efficacy of Skip Softmax increases with sequence length. The brink for skipping is mathematically related to the context length (

The tradeoff between accuracy and sparsity
The plain query for any approximation technique is, “How does this approach impact accuracy?”
Extensive testing on the RULER (synthetic long-context) and LongBench (realistic long-context) benchmarks suggests a transparent “protected zone” for sparsity.
- Protected zone: A 50% sparsity ratio (skipping half the blocks) is observed to be the protected zone. In tests with Llama 3.1 8B and Qwen3-8B, running at ~50% sparsity resulted in near-lossless accuracy across most tasks.
- Danger zone: Pushing sparsity beyond 60% often results in sharp accuracy drops, particularly in complex “needle-in-a-haystack” multikey tasks.
- Long generation: For tasks requiring long output generation comparable to MATH-500, Skip Softmax maintains accuracy parity with dense attention, unlike some static KV cache compression methods.
| Model | Dataset | Sparsity | Accuracy delta versus baseline |
| Llama 3.1 8B | RULER-16K | ~50% at prefill stage | -0.19% |
| Qwen-3-8B | MATH500 | ~50% at decode stage | 0.36% |
| Scenario | Threshold | Speedup (BF16) | Baseline accuracy | Sparse accuracy | Accuracy delta |
| Context only | 0.2 | 130.63% | 37.21% | 36.74% | -0.47% |
| Context plus generation | 0.6 | 138.37% | 35.81% | 34.42% | -1.39% |
Additional optimizations while deploying include the next:
- Automated calibration procedures to find out the optimal thresholds for goal sparsity levels.
- Sparsity-aware training makes models more robust to sparse attention patterns.
Start with Skip Softmax in NVIDIA TensorRT-LLM
Skip Softmax Attention is integrated directly into NVIDIA TensorRT-LLM and supported on NVIDIA Hopper and NVIDIA Blackwell data center GPUs. This lets you further speed up the eye computation, on the idea of the state-of-the-art LLM inference performance powered by TensorRT-LLM.
Skip Softmax Attention could be enabled through the sparse attention configuration of the LLM API:
from tensorrt_llm import LLM
from tensorrt_llm.llmapi import SkipSoftmaxAttentionConfig
sparse_attention_config = SkipSoftmaxAttentionConfig(threshold_scale_factor=1000.0)
# Moreover, the threshold_scale_factor for prefill and decode could possibly be individually configured.
sparse_attention_config = SkipSoftmaxAttentionConfig(threshold_scale_factor={"prefill": 1000.0, "decode": 500.0})
llm = LLM(
model="Qwen/Qwen3-30B-A3B-Instruct-2507",
sparse_attention_config=sparse_attention_config,
# Other LLM arguments...
)
The actual threshold value equals the threshold_scale_factor divided by the context length.
The configuration may be specified through the additional LLM API options YAML file. An example to launch an OpenAI-compatible endpoint is shown below:
cat >extra_llm_api_options.yaml <extra_llm_api_options.yaml <
Learn more
To learn more, see BLASST: Dynamic Blocked Attention Sparsity via Softmax Thresholding, in addition to the TensorRT-LLM documentation for LLM API and CLI. The calibration might be supported by NVIDIA Model Optimizer, which enables users to specify the goal sparsity and get the specified threshold scale aspects.
The Skip Softmax sparse attention kernel will even be available through the FlashInfer Python API. Stay tuned for the official release within the upcoming TensorRT-LLM, Model Optimizer, and FlashInfer release update.