
Running advanced AI and computer vision workloads on small, power-efficient devices at the sting is a growing challenge. Robots, smart cameras, and autonomous machines need real-time intelligence to see, understand, and react without depending on the cloud. The NVIDIA Jetson platform meets this need with compact, GPU-accelerated modules and developer kits purpose-built for edge AI and robotics.
The tutorials below show tips on how to bring the most recent open source AI models to life on NVIDIA Jetson, running completely standalone and able to deploy anywhere. Once you have got the fundamentals, you possibly can move quickly from easy demos to constructing anything from a non-public coding assistant to a completely autonomous robot.
Tutorial 1: Your Personal AI Assistant – Local LLMs and Vision Models
An amazing approach to get accustomed to edge AI is to run an LLM or VLM locally. Running models on your individual hardware provides two key benefits: complete privacy and 0 network latency.
Once you depend on external APIs, your data leaves your control. On Jetson, your prompts—whether personal notes, proprietary code, or camera feeds—never leave the device, ensuring you keep complete ownership of your information. This local execution also eliminates network bottlenecks, making interactions feel instantaneous.
The open source community has made this incredibly accessible, and the Jetson you select defines the scale of the assistant you possibly can run:
- NVIDIA Jetson Orin Nano Super Developer Kit (8GB): Great for fast, specialized AI assistance. You may deploy high-speed SLMs like Llama 3.2 3B or Phi-3. These models are incredibly efficient, and the community often releases latest fine-tunes on Hugging Face optimized for specific tasks—from coding to creative writing—that run blazingly fast throughout the 8GB memory footprint.
- NVIDIA Jetson AGX Orin (64GB): Provides the high memory capability and advanced AI compute needed to run larger, more complex models akin to gpt-oss-20b or quantized Llama 3.1 70B for deep reasoning.
- NVIDIA Jetson AGX Thor (128GB): Delivers frontier-level performance, enabling you to run massive 100B+ parameter models and produce data center-class intelligence to the sting.
If you have got an AGX Orin, you possibly can spin up a gpt-oss-20b instance immediately using vLLM because the inference engine and Open WebUI as an attractive friendly UI.
docker run --rm -it
--network host
--shm-size=16g
--ulimit memlock=-1
--ulimit stack=67108864
--runtime=nvidia
--name=vllm
-v $HOME/data/models/huggingface:/root/.cache/huggingface
-v $HOME/data/vllm_cache:/root/.cache/vllm
ghcr.io/nvidia-ai-iot/vllm:latest-jetson-orin
vllm serve openai/gpt-oss-20b
Run the Open WebUI in a separate terminal:
docker run -d
--network=host
-v ${HOME}/open-webui:/app/backend/data
-e OPENAI_API_BASE_URL=http://0.0.0.0:8000/v1
--name open-webui
ghcr.io/open-webui/open-webui:essential
Then, visit this http://localhost:8080 in your browser.
From here, you possibly can interact with the LLM and add tools that provide agentic capabilities, akin to search, data evaluation, and voice output (TTS).
Nonetheless, text alone isn’t enough to construct agents that interact with the physical world; in addition they need multimodal perception. VLMs akin to VILA and Qwen2.5-VL have gotten a standard approach to add this capability because they’ll reason about entire scenes quite than only detect objects. For instance, given a live video feed, they’ll answer questions akin to “Is the 3D print failing?” or “Describe the traffic pattern outside.”
On Jetson Orin Nano Super, you possibly can run efficient VLMs akin to VILA-2.7B for basic monitoring and easy visual queries. For higher-resolution evaluation, multiple camera streams, or scenarios with several agents running concurrently, Jetson AGX Orin provides the extra memory and compute headroom needed to scale these workloads.
To check this out, you possibly can launch the Live VLM WebUI from the Jetson AI Lab. It connects to your laptop’s camera via WebRTC and provides a sandbox that streams live video to AI models for immediate evaluation and outline.
The Live VLM WebUI supports Ollama, vLLM, and most inference engines that expose an OpenAI-compatible server.
To start with VLM WebUI using Ollama, follow the steps below:
# Install ollama (skip if already installed)
curl -fsSL https://ollama.com/install.sh | sh
# Pull a small VLM-compatible model
ollama pull gemma3:4b
# Clone and begin Live VLM WebUI
git clone https://github.com/nvidia-ai-iot/live-vlm-webui.git
cd live-vlm-webui
./scripts/start_container.sh
Next, open https://localhost:8090 in your browser to try it out.
This setup provides a robust start line for constructing smart security systems, wildlife monitors, or visual assistants.
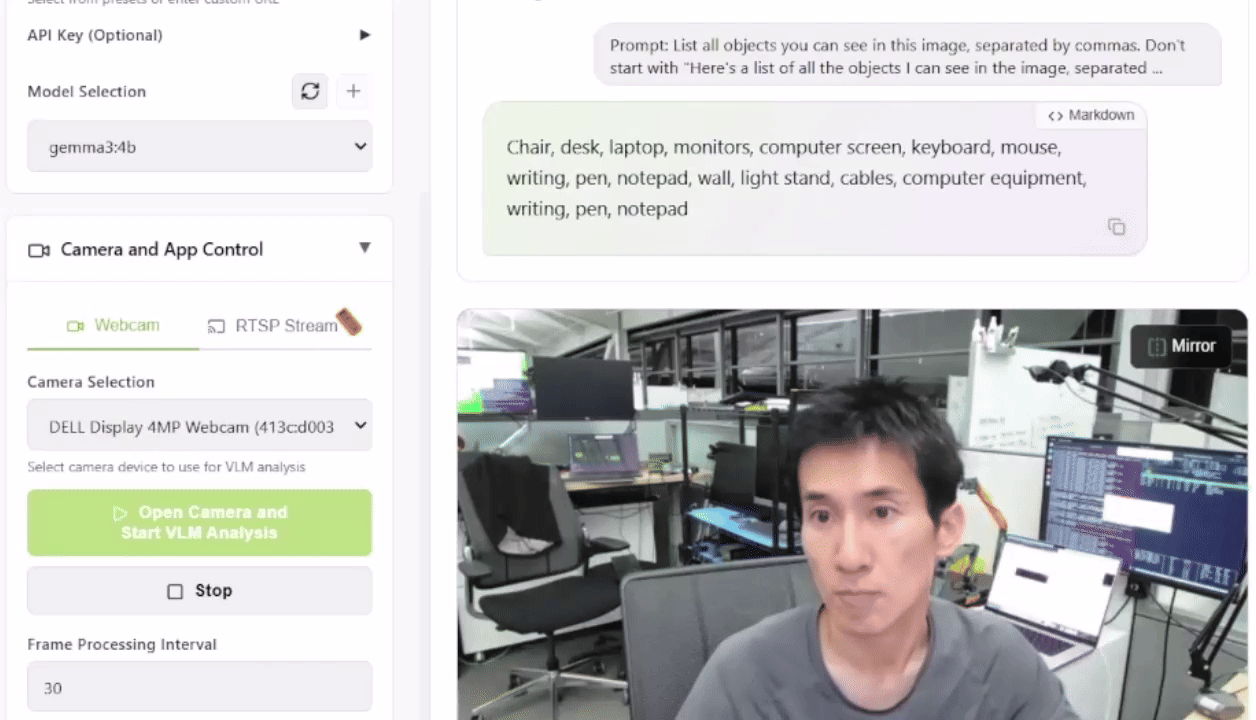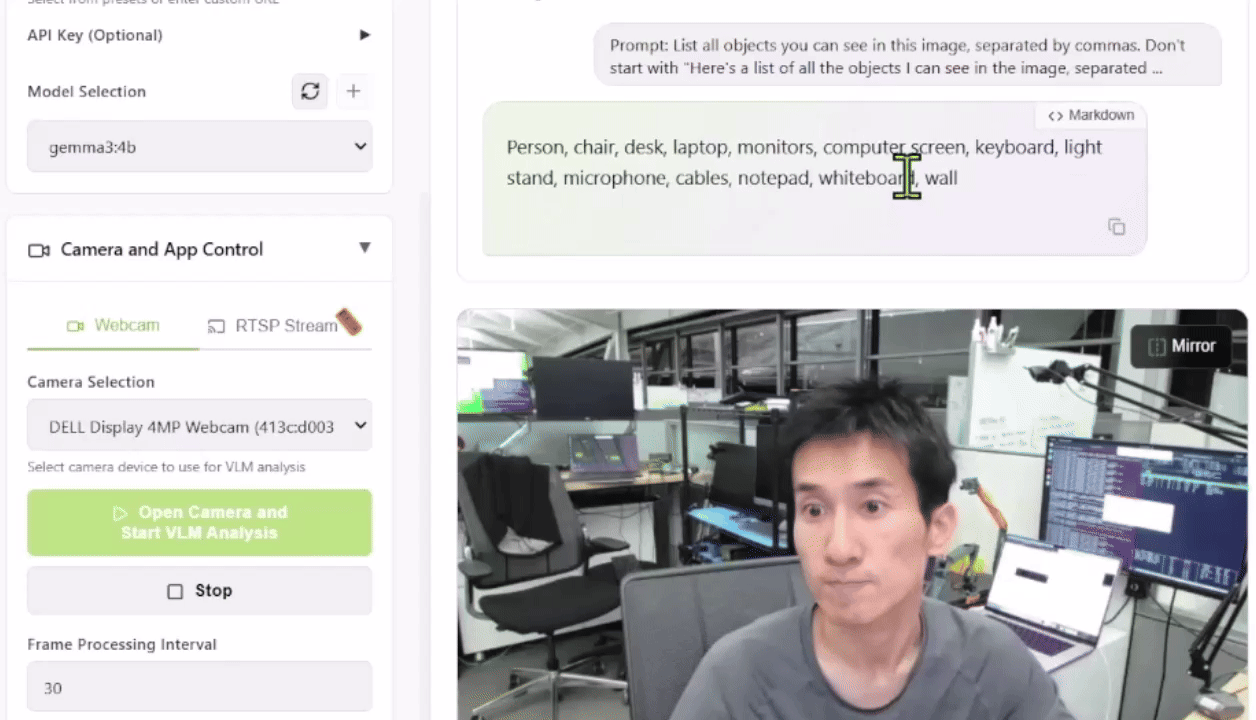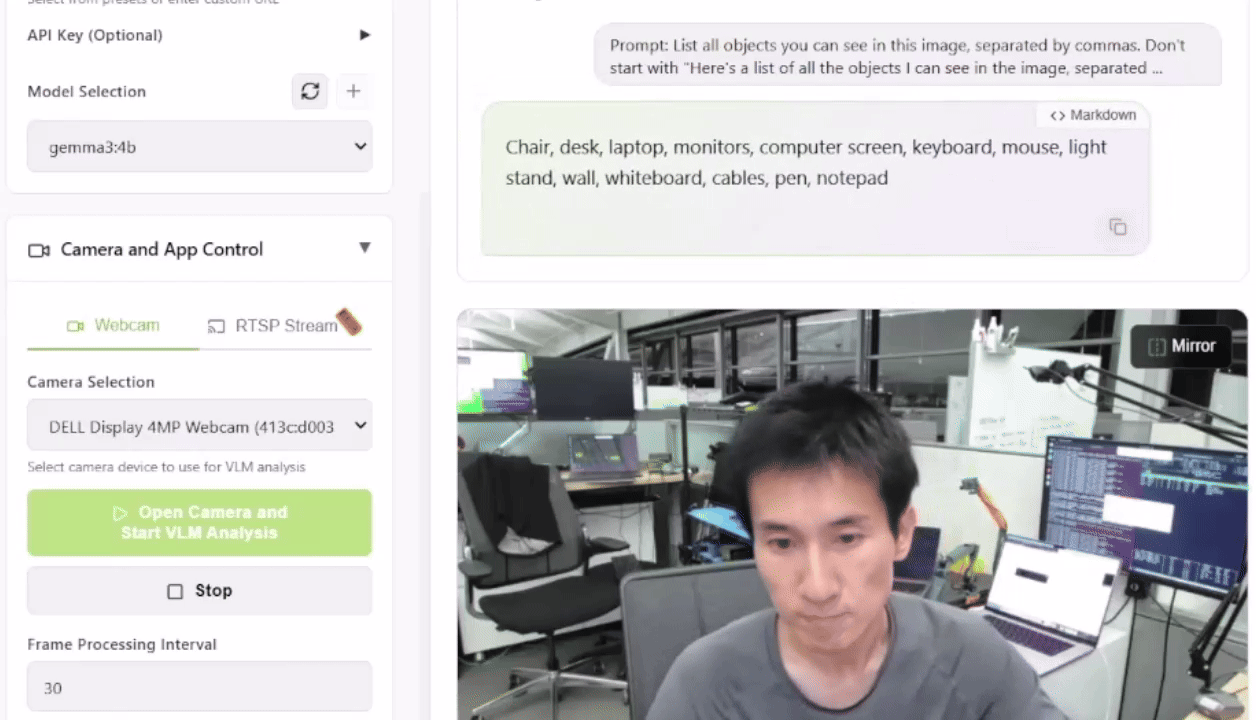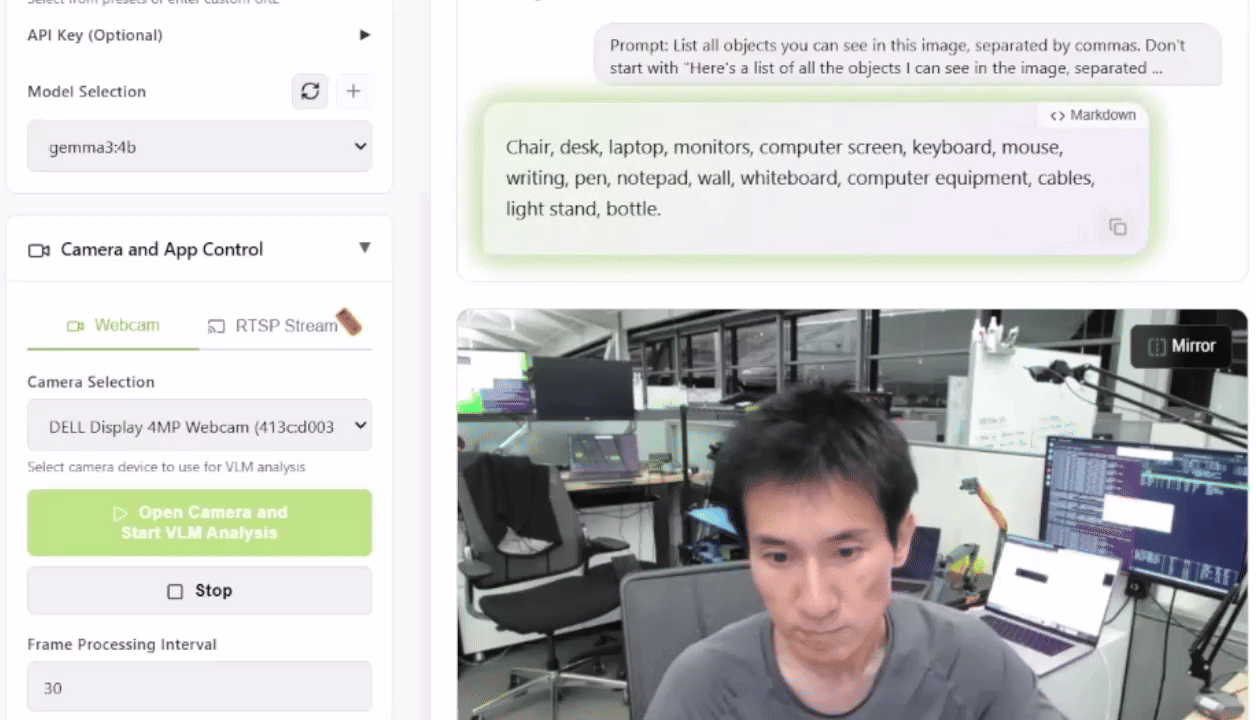
What VLMs Can You Run?
Jetson Orin Nano 8GB is suitable for VLMs and LLMs up to almost 4B parameters, akin to Qwen2.5-VL-3B, VILA 1.5–3B, or Gemma-3/4B. Jetson AGX Orin 64GB targets medium models within the 4B–20B range and may run VLMs like LLaVA-13B, Qwen2.5-VL-7B, or Phi-3.5-Vision. Jetson AGX Thor 128GB is designed for the biggest workloads, supporting multiple concurrent models or single models from about 20B as much as around 120B parameters—for instance, Llama 3.2 Vision 70B or 120B-class models.
Need to go deeper? Vision Search and Summarization (VSS) lets you construct intelligent archival systems. You may search videos by content quite than filenames and routinely generate summaries of long recordings. It’s a natural extension of the VLM workflow for anyone looking to arrange and interpret large volumes of visual data.
Tutorial 2: Robotics with Foundation Models
Robotics is undergoing a fundamental architectural shift. For many years, robot control relied on rigid, hard-coded logic and separate perception pipelines: detect an object, calculate a trajectory, execute a motion. This approach requires extensive manual tuning and explicit coding for each edge case, making it difficult to automate at scale.
The industry is now moving toward end-to-end imitation learning. As a substitute of programming explicit rules, we’re using foundation models like NVIDIA Isaac GR00T N1 to learn policies directly from demonstration. These are Vision-Language-Motion (VLA) models that fundamentally change the input-output relationship of robot control. On this architecture, the model ingests a continuous stream of visual data from the robot’s cameras along together with your natural language commands (e.g., “Open the drawer”). It processes this multimodal context to directly predict the crucial joint positions or motor velocities for the subsequent timestep.
Nonetheless, training these models presents a major challenge: the info bottleneck. Unlike language models that train on the web’s text, robots require physical interaction data, which is pricey and slow to amass. The answer lies in simulation. By utilizing NVIDIA Isaac Sim, you possibly can generate synthetic training data and validate policies in a physics-accurate virtual environment. You may even perform hardware-in-the-loop (HIL) testing, where the Jetson runs the control policy while connected to the simulator powered by an NVIDIA RTX GPU. This means that you can validate your entire end-to-end system, from perception to actuation, before you put money into physical hardware or attempt a deployment.
Once validated, the workflow transitions seamlessly to the actual world. You may deploy the optimized policy to the sting, where optimizations akin to TensorRT enable heavy transformer-based policies to run with the low latency (sub-30 ms) required for real-time control loops. Whether you’re constructing an easy manipulator or exploring humanoid form aspects, this paradigm—learning behaviors in simulation and deploying them to the physical edge—is now the usual for contemporary robotics development.
You may begin experimenting with these workflows today. The Isaac Lab Evaluation Tasks repo on GitHub provides pre-built industrial manipulation benchmarks, akin to nut pouring and exhaust pipe sorting, you could use to check policies in simulation before deploying to hardware. Once validated, the GR00T Jetson deployment guide walks you thru the means of converting and running these policies on Jetson with optimized TensorRT inference. For those seeking to post-train or fine-tune GR00T models on custom tasks, the LeRobot integration lets you leverage community datasets and tools for imitation learning, bridging the gap between data collection and deployment
Join the Community: The robotics ecosystem is vibrant and growing. From open-source robot designs to shared learning resources, you’re not alone on this journey. Forums, GitHub repositories, and community showcases offer each inspiration and practical guidance. Join the LeRobot Discord community to attach with others constructing the longer term of robotics.
Yes, constructing a physical robot takes work: mechanical design, assembly, and integration with existing platforms. However the intelligence layer is different. That’s what Jetson delivers: real time, powerful, and able to deploy.
Which Jetson is Right for You?
Use Jetson Orin Nano Super (8GB) in case you’re just getting began with local AI, running small LLMs or VLMs, or constructing early-stage robotics and edge prototypes. It’s especially well-suited for hobbyist robotics and embedded projects where cost, simplicity, and compact size matter greater than maximum model capability.
Select Jetson AGX Orin (64GB) in case you’re a hobbyist or independent developer seeking to run a capable local assistant, experiment with agent-style workflows, or construct deployable personal pipelines. The 64GB of memory makes it far easier to mix vision, language, and speech (ASR and TTS) models on a single device without consistently running into memory limits.
Go to Jetson AGX Thor (128GB) in case your use case involves very large models, multiple concurrent models, or strict real-time requirements at the sting.
Next Steps: Getting Began
Able to dive in? Here’s tips on how to begin:
- Select your Jetson: Based in your ambitions and budget, select the developer kit that most closely fits your needs.
- Flash and setup: Our Getting Began Guides make setup straightforward and also you’ll be up and running in under an hour.
- Explore the resources:
- Start constructing: Pick a project, dive into the tutorial project on GitHub, see what’s possible after which push further.
The NVIDIA Jetson family gives developers the tools to design, construct, and deploy the subsequent generation of intelligent machines.