
how I’ve built a self-hosted, end-to-end platform that provides each user a private, agentic chatbot that may autonomously search through only the files that the user explicitly allows it to access.
In other words: full control, 100% private, all the advantages of LLM without the privacy leaks, token costs, or external dependencies.
Intro
Over the past week, I challenged myself to construct something that has been on my mind for some time:
How can I supercharge an LLM with my personal data without sacrificing privacy to big tech corporations?
That led to this week’s challenge:
Construct an agentic chatbot equipped with tools to access a user’s personal notes securely, without compromising privacy.
As an additional challenge, I wanted the system to support multiple users. Not a shared assistant but a private agent for each user where user has full control over which files their agent can read and reason about.
We’ll construct the system in the next steps:
- Architecture
- How can we create an agent and supply it with tools?
- Flow 1: User file management: What happens after we submit a file?
- Flow 2: How can we embed documents and store files?
- Flow 3: What happens after we chat with our agentic assistant?
- Demonstration
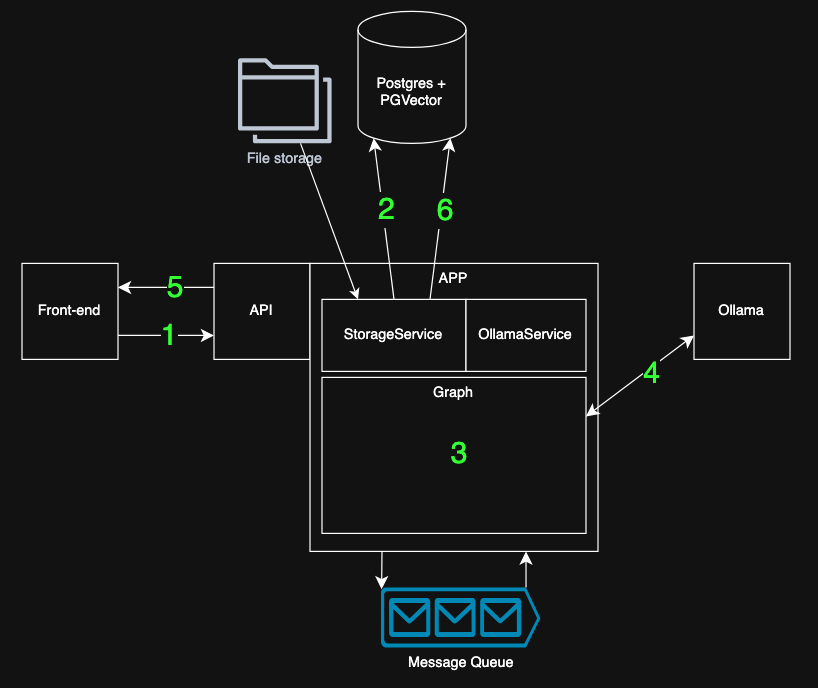
1) Architecture
I’ve defined three most important “flows” that the system must allow:
A) User file management
Users authenticate through the frontend, upload or delete files and assign each file to specific groups that determine which users’ agents may access it.
B) Embedding and storing files
Uploaded files are chunked, embedded and stored within the database in a way that ensures only authorized uses can retrieve or search those embeddings.
C) Chat
A user chats with their very own agent. The agent is provided with tools, including a , and may only search documents the user has permission to access.
To support these flows, the system consists of six key components:
App
A Python application that’s the center of the system. It exposes API endpoints for the front-end and listens for messages coming from the MessageQueue
Front-End
Normally I’d use Angular but for this prototype I went with Streamlit. It was very fast and simple to construct with. This ease-of-use after all got here with the downside of not with the ability to to all the things I wanted. I’m planning on replacing this component with my go-to Angluar but in my view Streamlit was very nice for prototyping
Blob storage
This container runs Minio; a open-source, high-performance, distributed object storage system. Definitely overkill for my prototype but it surely was very easy to make use of and integrates well with Python, so I actually have no regrets.
(Vector) Database
Postgres handles all of the relational data like document meta-data, users, usergroups and text-chunks. Moreover Postgres offers an extension that I take advantage of to save lots of vector-data just like the embeddings we’re aiming to create. This could be very convenient for my use-case since I can allow vector-search on a table, joining that table to the users-table, ensuring that every user can only see their very own data.
Ollama
Ollama hosts two local models: one for and one for . The models are pretty light-weight but will be easily upgraded, depending on available hardware.
Message Queue
RabbitMQ makes the system responsive. Users don’t should wait while large files are chunked and embedded. As a substitute, I return immediately and process the embedding within the background. It also gives me horizontal scalability: multiple staff can process files concurrently.
2) Constructing an agent with a toolbox
LangGraph makes it easy to define an agent: what steps it might probably take, the way it should reason and which tool it’s allowed to make use of. This agent can then autonomously inspect the available tools, read their descriptions and choose whether calling certainly one of them will help answer the user’s query.
The workflow is described as a graph. Consider this a the blueprint for the agent’s behavior. On this prototype the graph is intentionally easy:
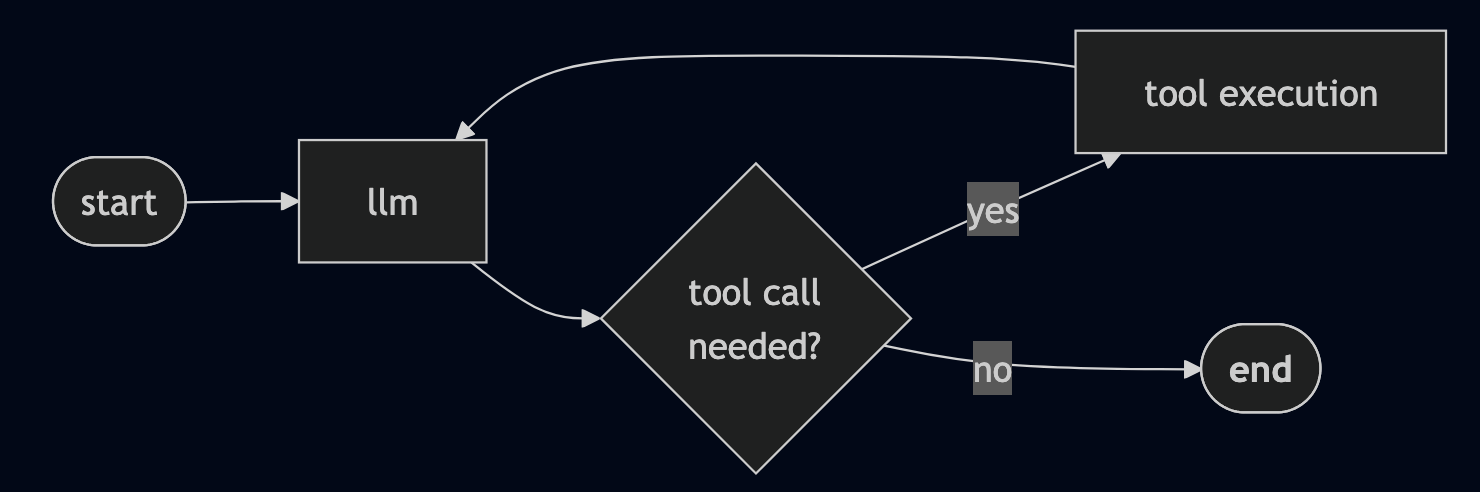
The LLM checks which tools can be found and decides whether a tool-call (like vector search) is needed. and The graph loops through the tool node and back to the LLM node until no more tools are needed and the agent has enough information to reply.
3) Flow 1: Submitting a File
This part describes what happens when a user submits a number of files. First a user has to log in to the front-end, receiving a token that’s used to authenticate API calls.
After that they’ll upload files and assign those files to at least one or more groups. Any user in those groups might be allowed to access the file through their agent.
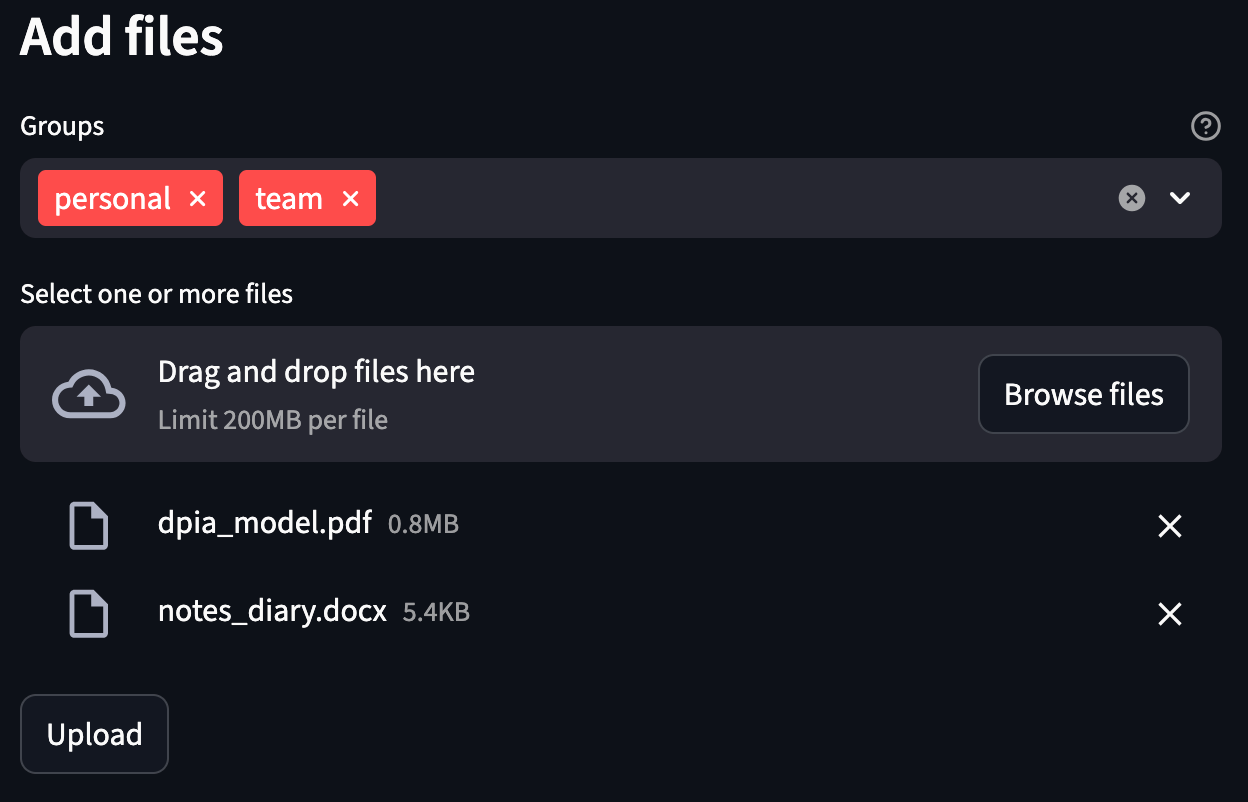
Within the screenshot above the user chosen two files; a PDF and a Word document, and assigns them to 2 groups. Behind the scenes, that is how the system processes an upload like this:
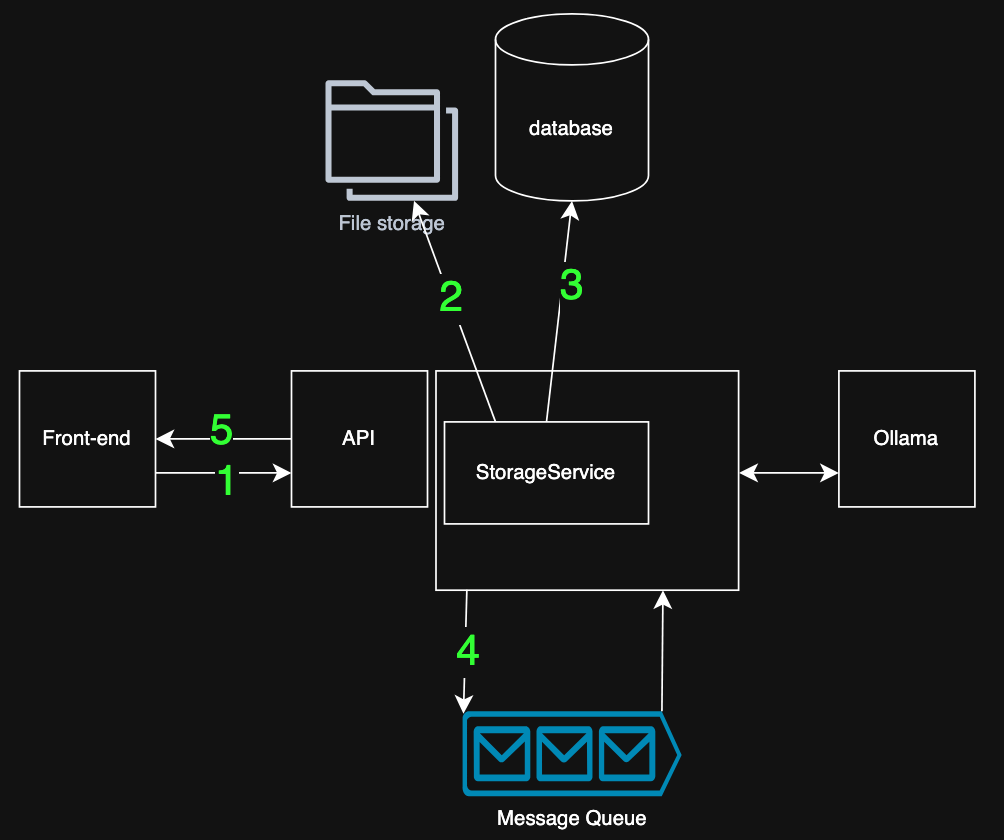
- The file and groups are sent to the API, validating the user with the token.
- The file is saved within the blob storage, returning the storage location
- The file’s metadata and storage location is saved within the database, returning the
file_id - The
file_idis published to a message queue - the request is accomplished; the users can proceed using the front-end. Heavy processes (chunking, embedding) happens later within the background)
This flow ensures the upload experience to remain fast and responsive, even for giant files.
4) Flow 2: Embedding and storing Files
Once a document is submitted, the following step is to make it searchable. In an effort to do that we’d like to our documents. Which means that we convert the text from the document into numerical vectors that may capture semantic meaning.
Within the previous flow we’ve submitted a message to the queue. This message only incorporates a file_id and thus could be very small. Which means that the system stays fast even when a user uploads dozens or lots of of files.
The message queue also gives us two necessary advantages:
- it smooths out load by processing documents on-by-one in stead of
- it future-proofs our system by allowing horizontal scaling; multiple staff can hearken to the identical queue and process files in parallel.
Here’s what happens when the embedding employee receives a message:
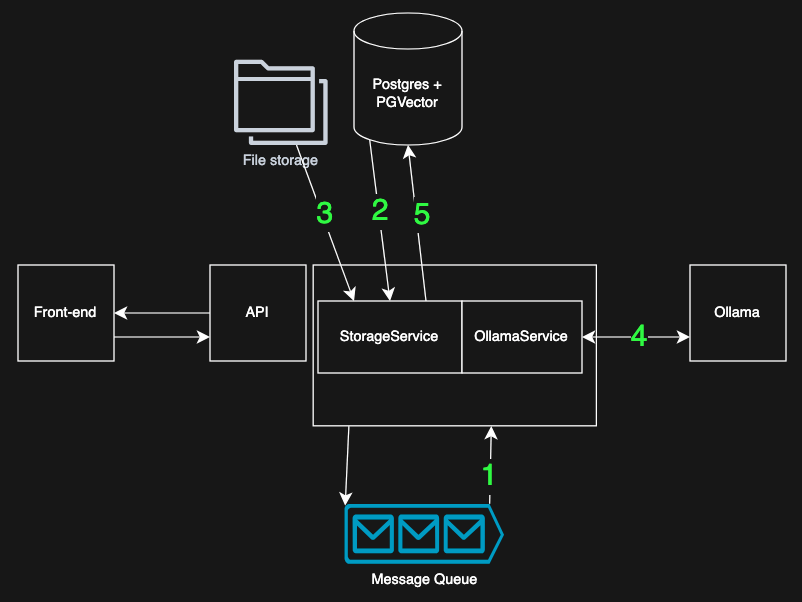
- Take a message from the queue, the message incorporates a
file_id - Use
file_idto retrieve document meta data (filtering by user and allowed groups) - Use the
storage_locationfrom the meta data to download the file - The file is read, text-extracted and split into smaller chuks. Each chunk is embedded: it’s sent to the local Ollama instance to generate an embedding.
- The chunks and their vectors are written to the database, alongside the file’s access-control information
At this point, the document becomes fully searchable by the agent through vector search, but just for users who’ve been granted access.
5) Flow 3: Chatting with our Agent
With all components in place, we are able to start chatting with the agent.
When a user types a message, the system orchestrates several steps behind the scenes to deliver a quick and context-aware response:
- The user sends a prompt to the API and is authenticated since only authorized users can interact with their private agent.
- The app optionally retrieves previous messages in order that the agent has a “memory” of the present conversation. This ensures that it might probably respond within the context of the continued conversation.
- The compiled LangGraph agent is invoked.
- The LLM, (running in Ollama) reasons and optionally uses tools. If needed, it calls the vector-search tool that we’ve defined within the graph, to seek out relevant document chunks the user is allowed to access.
The agent then incorporates those findings into its reasoning and decides whether it has enough information to offer an adequate response. - The agent’s answer is generated incrementally and streamed back to the user for a smooth, real-time chat experience.
At this point, the user is chatting with their very own private, fully local agent that is provided with the flexibility to semantically search through their personal notes.
6) Demonstration
Let’s see what this looks like in practice.
I’ve uploaded a word document with the next content:
Notes On the twenty first of November I spoke with a man named “Gert Vektorman” that turned out to be a developer at a Groningen company called “super data solutions”. Seems that he was very focused on implementing agentic RAG at his company. We’ve agreed to satisfy a while at the top of december. Edit: I’ve asked Gert what his favorite programming language was; he like using Python Edit: we’ve met and agreed to create a test implementation. We’ll call this project “project greenfield”I’ll go to the front-end and upload this file.

After uploading, I can see within the front-end that:
- the document is stored within the database
- it has been embedded
- my agent has access to it
Now, let’s chat.
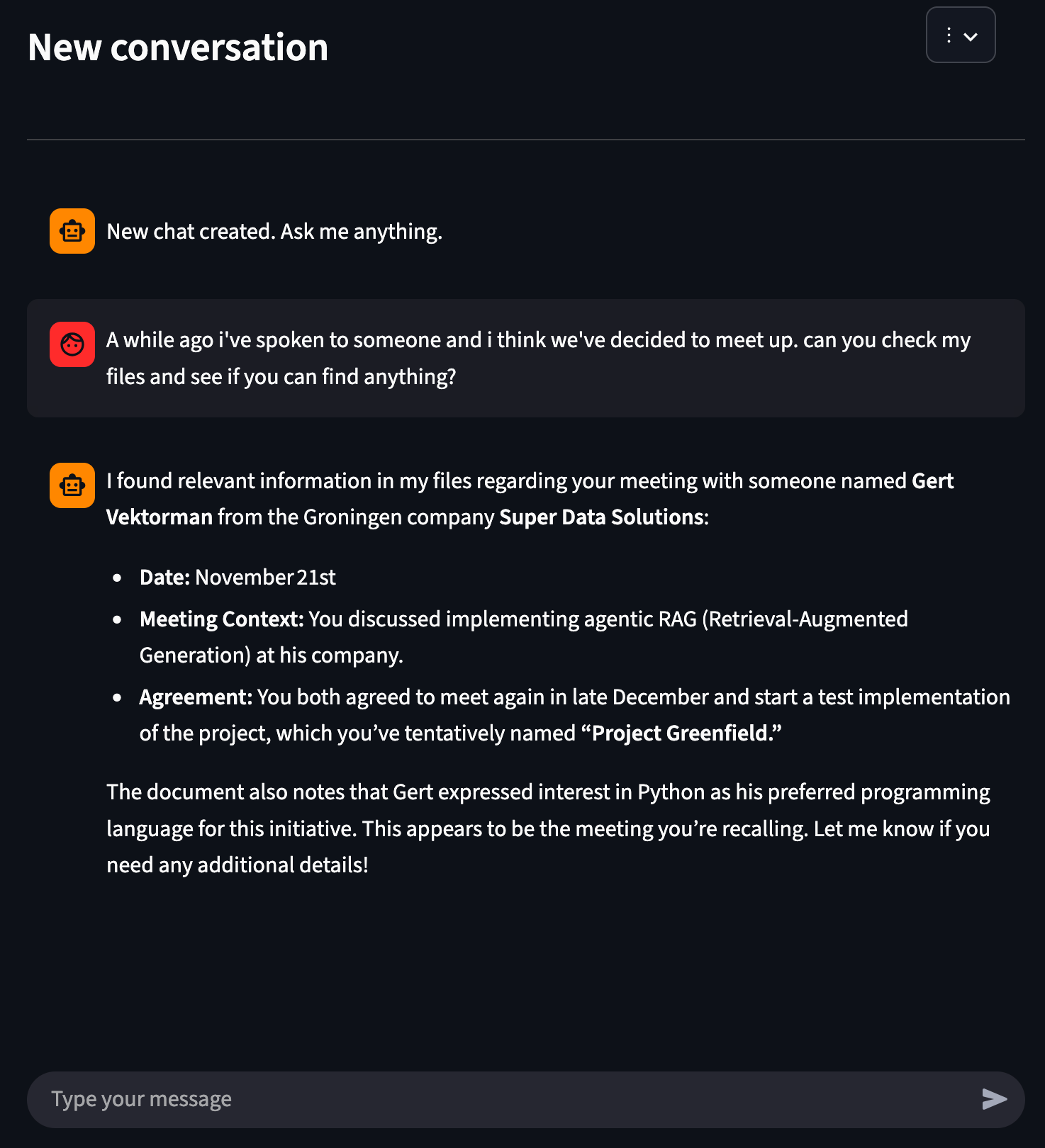
As you see, the agent is capable of respond with the knowledge from our file. It’s also surprisingly fast; this query was answered in a number of seconds.
Conclusion
I really like challenges that allow me to experiment with recent tech and work across the entire stack, from database to agent graphs and front-end to the docker images. Designing the system and selecting a working architecture is something I at all times enjoy. It allows me to convert our goals into requirements, flows, architecture, components, code and eventually a working product.
This week’s challenge was exactly that: exploring and experimenting with private, multi-user, agentic RAG. I’ve built a working, expandable, reusable, scalable prototype that will be improved upon in the long run. Most I’ve found that local, 100% private, agentic LLM’s are possible.
Technical learnings
- Postgres + pgvector is powerful. Storing embeddings alongside relational metadata kept all the things clean, consistent and simple to question since there was no need for an additional vector database.
- LangGraph makes it surprisingly easy to define an agent workflow, equip it with tools and let the agent determine when to make use of them
- Private, local, self-hosted agents are feasible. With Ollama running two lightweight models (one for chat, one for embeddings), all the things runs on my MacBook with impressive speed
- Constructing a multi-tenant system with strict data isolation was quite a bit easier once architecture was clean and responsibilities were separated across components
- Loose coupling makes it easier to exchange and scale components
Next steps
This method is prepared for upgrades:
- Incremental re-embedding for documents that change over time
(so I can plug in my Obsidian vault seamlessly). - Citations that time the user to the precise files/pages/chunks the LLM used to reply my query used, improving trust and explainability.
- More tools for the agent — from structured summarizers to SQL access. Perhaps even ontologies or user profiles?
- A richer frontend with higher file management and user experience
I hope this text was as clear as I intended it to be but when this is just not the case please let me know what I can do to make clear further. Within the meantime, try my other articles on all types of programming-related topics.
Completely satisfied coding!
— Mike
P.s: like what I’m doing? Follow me!