
Join us in constructing benchmarks that capture early-stage reasoning & scientific knowledge in LLMs!
The event of Large Language Models (LLMs) typically begins with a series of ablation experiments, wherein various model architectures, data mixtures, and training hyperparameters are systematically evaluated. This phase is often known as the early stages of coaching. During this era, researchers primarily monitor two key metrics: the training loss curve and evaluation scores. Nevertheless, existing evaluation benchmarks often fail to supply meaningful or discriminative signals during these initial stages where LLMs are trained on a number of tokens ~200B tokens, making it difficult to derive conclusive insights from ongoing experiments.
On this competition, we would like to construct together recent benchmarks to effectively capture relevant signals in early training stages of LLMs, specifically for scientific knowledge domain.
Easy methods to participate
The competition can be hosted on a dedicated Hugging Face organization – to register to the competition please follow this registration link 👉 https://e2lmc.github.io/registration.
Participants can have to submit their solutions, which can be based on lm-evaluation-harness library through a HuggingFace Space. An lively leaderboard can be maintained through the competition to trace promising submissions.
The dimensions of the models make them easily runnable for everybody, on free-tier Google Colab GPUs. We also provide a comprehensive starting kit including several notebooks to start with the competition.
Evaluation metrics
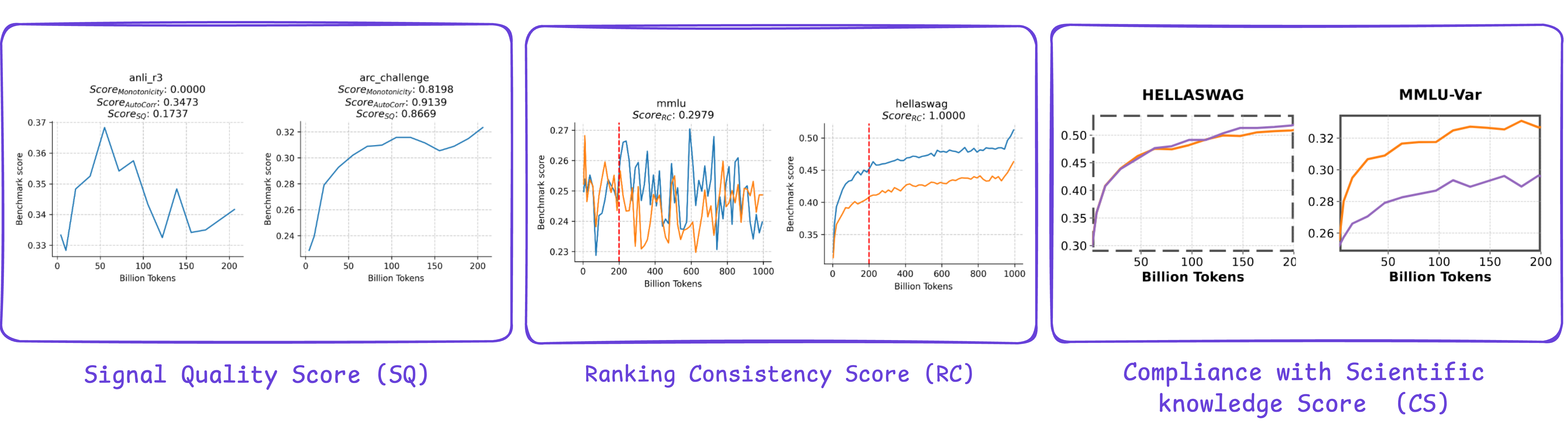
Each submission can be evaluated using three different scores: signal quality rating (RatingSQ), rating consistency rating (RatingRC) amd compliance with scientific knowledge rating (RatingCS). These criteria can be combined into a world rating used for the ultimate rating.
Moreover, two validation procedures can be systematically applied to all submissions: (i) verification of alignment with established scientific knowledge domains, and (ii) detection of potential information leakage, specifically the presence of the reply throughout the query prompt.The general rating is computed as a weighted sum:
Rating = α1 × RatingSQ + α2 × RatingRC + α3 × RatingCS
where, αSQ, αRC and αCS are weighting coefficients that reflect the relative importance of every
criterion. We set the weights as α1 = 0.5, α2 = 0.1 and α3 = 0.4, thereby placing greater emphasis on signal quality and compliance to scientific knowledge, which we consider a very powerful metrics in evaluating submissions.
Participants will give you the option to compute the signal quality subscore locally using the provided model checkpoints of three Small Language Models 0.5B, 1B and 3B (starting from 0 to 200 BT) together with the accompanying scoring algorithm (provided in a notebook within the starting kit). In contrast, the opposite two subscores can’t be computed independently, because the corresponding checkpoints—from 200 GT to 1 T tokens, in addition to the 0.5 billion parameter model trained exclusively on web data—will remain hidden throughout the competition.
Nonetheless, the worldwide rating can be mechanically computed upon submission through the Hugging Face competition space, allowing participants to trace their overall performance. This setup is meant to stop overly customized solutions specifically tailored to the released checkpoints.
Further details about each evaluation metric, together with full scoring results on state-of-the-art benchmarks, can be found in the competition proposal
Competition timeline
| Competition kick-off | 14 July 2025 |
| Warm-up Phase | 14 July 2025 – 17 August 2025 (5 weeks) |
| Development Phase | 18 August 2025 – 26 October 2025 (10 weeks) |
| Final Phase | 27 October 2025 – 03 November 2025 (3 weeks) |
| Results Announcement | 04 November 2025 |
| Winners’ Fact Sheets & Code Release Due | 22 November 2025 |
| NeurIPS Competition Workshop Presentation | 6 or 7 December 2025 |
Prizes
- 🥇 1st Place: 6,000 USD
- 🥈 2nd Place: 4,000 USD
- 🥉 third Place: 2,000 USD
- 🎓 Student Awards: 2x 2,000 USD for the highest 2 solutions submitted by participants justifying a student status
Support and make contact with
For inquiries and support, reach out to the duty coordinators at e2lmc@tii.ae. You can even join our discord channel here to directly interact with us.