



We gave Claude the power to fine-tune language models using a brand new tool called Hugging Face Skills. Not only write training scripts, but to really submit jobs to cloud GPUs, monitor progress, and push finished models to the Hugging Face Hub. This tutorial shows you ways it really works and methods to use it yourself.
Claude Code can use “skills”—packaged instructions, scripts, and domain knowledge—to perform specialized tasks. The
hf-llm-trainerskill teaches Claude every thing it must find out about training: which GPU to choose on your model size, methods to configure Hub authentication, when to make use of LoRA versus full fine-tuning, and methods to handle the handfuls of other decisions that go right into a successful training run.
With this skill, you may tell Claude things like:
Nice-tune Qwen3-0.6B on the dataset open-r1/codeforces-cots
And Claude will:
- Validate your dataset format
- Select appropriate hardware (t4-small for a 0.6B model)
- Use and update a training script with Trackio monitoring
- Submit the job to Hugging Face Jobs
- Report the job ID and estimated cost
- Check on progress once you ask
- Assist you debug if something goes improper
The model trains on Hugging Face GPUs when you do other things. When it’s done, your fine-tuned model appears on the Hub, able to use.
This is not a toy demo. The skill supports the identical training methods utilized in production: supervised fine-tuning, direct preference optimization, and reinforcement learning with verifiable rewards. You may train models from 0.5B to 70B parameters, convert them to GGUF for local deployment, and run multi-stage pipelines that mix different techniques.
Setup and Install
Before starting, you will need:
- A Hugging Face account with a Pro or Team plan (Jobs require a paid plan)
- A write-access token from huggingface.co/settings/tokens
- A coding agent like Claude Code, OpenAI Codex, or Google’s Gemini CLI
Hugging Face skills are compatible with Claude Code, Codex, and Gemini CLI. With integrations Cursor, Windsurf, and Proceed, on the best way.
Claude Code
- Register the repository as a plugin marketplace:
/plugin marketplace add huggingface/skills
- To put in a skill, run:
/plugin install @huggingface-skills
For instance:
/plugin install hf-llm-trainer@huggingface-skills
Codex
- Codex will discover the talents via the
AGENTS.mdfile. You may confirm the instructions are loaded with:
codex --ask-for-approval never "Summarize the present instructions."
- For more details, see the Codex AGENTS guide.
Gemini CLI
-
This repo includes
gemini-extension.jsonto integrate with the Gemini CLI. -
Install locally:
gemini extensions install . --consent
or use the GitHub URL:
gemini extensions install https://github.com/huggingface/skills.git --consent
- See Gemini CLI extensions docs for more help.
Hook up with Hugging Face
You’ll to authenticate you Hugging Face account with a write-access token in order that the job can create a model repo.
Arrange your token:
hf auth login
export HF_TOKEN=hf_your_write_access_token_here
![NOTE]
Configure Hugging Face MCP Server to make use of your write token by sending it in either theHF_TOKENorAuthorization: BearerHTTP Headers.
Your First Training Run
Let’s walk through an entire example. We’ll fine-tune a small model to see the complete workflow, then explore more advanced capabilities.
Instruct the coding agent to fantastic tune
Start with an easy and clear instruction to fantastic tune a selected model
Nice-tune Qwen3-0.6B on the open-r1/codeforces-cots dataset for instruction following.
The coding agent analyzes your request and prepares a training configuration. For a 0.6B model on a demo dataset, it selects t4-small—enough GPU for this model size and the most affordable option available.
The
open-r1/codeforces-cotsdataset is a dataset of codeforces problems and solutions. It’s dataset for instruction tuning a model to resolve hard coding problems.
Review Before Submitting
Before your coding agent submits anything, you will see the configuration:
I'll fine-tune Qwen/Qwen3-0.6B on open-r1/codeforces-cots using SFT.
Configuration:
- Hardware: t4-small (~$0.75/hour)
- Estimated time: ~20 minutes
- Estimated cost: ~$0.30
- Output: username/qwen-codeforces-cots-sft
The model shall be pushed to Hub mechanically. Should I submit?
That is your likelihood to regulate anything. Change the output repo name, pick different hardware, or ask Claude to change training parameters. When you approve, the agent submits the job.
For instance, you may ask the agent to try a test run:
Do a fast test run on 100 examples.
Track Progress
After submission, you get job details:
✅ Job submitted successfully!
Job ID: abc123xyz
Monitor: https://huggingface.co/jobs/username/abc123xyz
Expected time: ~20 minutes
Estimated cost: ~$0.30
View real-time metrics at: https://huggingface.co/spaces/username/trackio
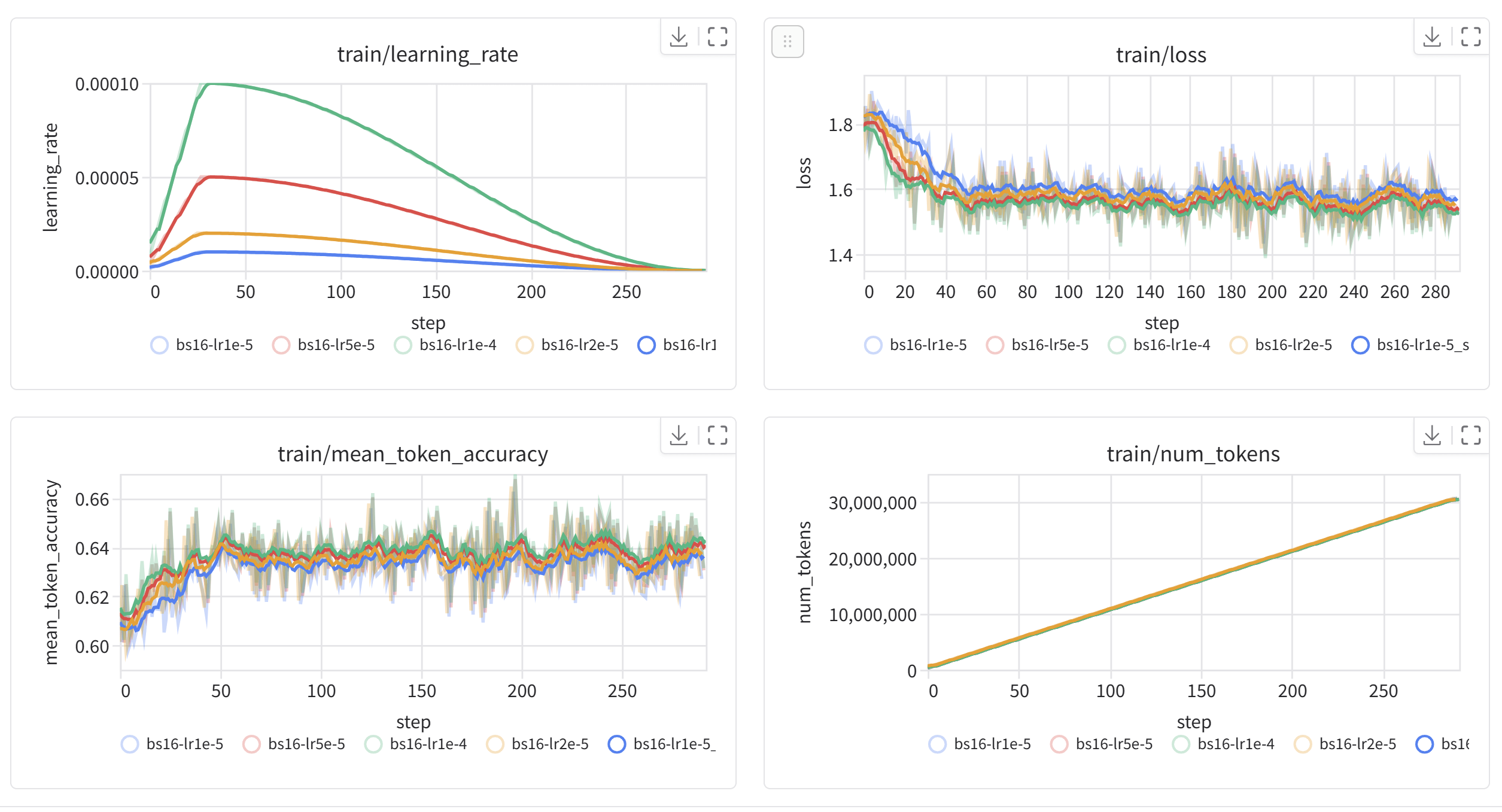
The skill includes Trackio integration, so you may watch training loss decrease in real-time. Jobs run asynchronously so you may close your terminal and are available back later. Once you want an update:
How's my training job doing?
Then the agent fetches the logs and summarizes progress.
Use Your Model
When training completes, your model is on the Hub:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("username/qwen-codeforces-cots-sft")
tokenizer = AutoTokenizer.from_pretrained("username/qwen-codeforces-cots-sft")
That is the complete loop. You described what you wanted in plain English, and the agent handled GPU selection, script generation, job submission, authentication, and persistence. The entire thing cost about thirty cents.
Training Methods
The skill supports three training approaches. Understanding when to make use of each helps you get well results.
Supervised Nice-Tuning (SFT)
SFT is where most projects start. You provide demonstration data—examples of inputs and desired outputs—and training adjusts the model to match those patterns.
Use SFT when you might have high-quality examples of the behavior you would like. Customer support conversations, code generation pairs, domain-specific Q&A—anything where you may show the model what beauty like.
Nice-tune Qwen3-0.6B on my-org/support-conversations for 3 epochs.
The agent validates the dataset, selects hardware (a10g-large with LoRA for a 7B model), and configures training with checkpoints and monitoring.
For models larger than 3B parameters, the agent mechanically uses LoRA (Low-Rank Adaptation) to scale back memory requirements. This makes training 7B or 13B models feasible on single GPUs while preserving a lot of the quality of full fine-tuning.
Direct Preference Optimization (DPO)
DPO trains on preference pairs—responses where one is “chosen” and one other is “rejected.” This aligns model outputs with human preferences, typically after an initial SFT stage.
Use DPO when you might have preference annotations from human labelers or automated comparisons. DPO optimizes directly for the popular response while not having a separate reward model.
Run DPO on my-org/preference-data to align the SFT model I just trained.
The dataset has 'chosen' and 'rejected' columns.
DPO is sensitive to dataset format. It requires columns named exactly
chosenandrejected, or apromptcolumn with the input. The agent validates this primary and shows you methods to map columns in case your dataset uses different names.
Group Relative Policy Optimization (GRPO)
GRPO is a reinforcement learning task that’s proven to be effective on verifiable tasks like solving math problems, writing code, or any task with a programmatic success criterion.
Train a math reasoning model using GRPO on the openai/gsm8k dataset based on Qwen3-0.6B.
The model generates responses, receives rewards based on correctness, and learns from the outcomes. That is more complex than SFT or DPO, however the configuration is analogous.
Hardware and Cost
The agent selects hardware based in your model size, but understanding the tradeoffs helps you make higher decisions.
Model Size to GPU Mapping
For tiny models under 1B parameters, t4-small works well. These models train quickly—expect $1-2 for a full run. This is ideal for educational or experimental runs.
For small models (1-3B), step as much as t4-medium or a10g-small. Training takes a number of hours and costs $5-15.
For medium models (3-7B), you would like a10g-large or a100-large with LoRA. Full fine-tuning doesn’t fit, but LoRA makes these very trainable. Budget $15-40 for production.
For large models (7B+), this HF skills job isn’t suitable.
Demo vs Production
When testing a workflow, start small:
Do a fast test run to SFT Qwen-0.6B with 100 examples of my-org/support-conversations.
Th coding agent configures minimal training—enough to confirm your pipeline works without real cost.
For production, be explicit:
SFT Qwen-0.6B for production on the complete my-org/support-conversations.
Checkpoints every 500 steps, 3 epochs, cosine learning rate.
At all times run a demo before committing to a multi-hour production job. A $0.50 demo that catches a format error saves a $30 failed run.
Dataset Validation
Dataset format is probably the most common source of coaching failures. The agent can validate datasets before you spend GPU time.
Check if my-org/conversation-data works for SFT training.
The agent runs a fast inspection on CPU (fractions of a penny) and reports:
Dataset validation for my-org/conversation-data:
SFT: ✓ READY
Found 'messages' column with conversation format
DPO: ✗ INCOMPATIBLE
Missing 'chosen' and 'rejected' columns
In case your dataset needs transformation, the agent can show you ways:
My DPO dataset uses 'good_response' and 'bad_response' as a substitute
of 'chosen' and 'rejected'. How do I fix this?
The agent provides mapping code and might incorporate it directly into your training script.
Monitoring Training
Real-time monitoring helps you catch problems early. The skill configures Trackio by default—after submitting a job, you may watch metrics at:
https://huggingface.co/spaces/username/trackio
This shows training loss, learning rate, and validation metrics. A healthy run shows steadily decreasing loss.
Ask the agent about status anytime:
What is the status of my training job?
Job abc123xyz is running (45 minutes elapsed)
Current step: 850/1200
Training loss: 1.23 (↓ from 2.41 at start)
Learning rate: 1.2e-5
Estimated completion: ~20 minutes
If something goes improper, the agent helps diagnose. Out of memory? the agent suggests reducing batch size or upgrading hardware. Dataset error? The agent identifies the mismatch. Timeout? The agent recommends longer duration or faster training settings.
Converting to GGUF
After training, it is advisable to run your model locally. The GGUF format works with llama.cpp and dependent tools like LM Studio, Ollama, etc.
Convert my fine-tuned model to GGUF with Q4_K_M quantization.
Push to username/my-model-gguf.
The agent submits a conversion job that merges LoRA adapters, converts to GGUF, applies quantization, and pushes to Hub.
Then use it locally:
llama-server -hf /:
llama-server -hf unsloth/Qwen3-1.7B-GGUF:Q4_K_M
What’s Next
We have shown that coding agents like Claude Code, Codex, or Gemini CLI can handle the complete lifecycle of model fine-tuning: validating data, choosing hardware, generating scripts, submitting jobs, monitoring progress, and converting outputs. This turns what was once a specialized skill into something you may do through conversation.
Some things to try:
- Nice-tune a model on your individual dataset
- Construct a preference-aligned model with SFT → DPO
- Train a reasoning model with GRPO on math or code
- Convert a model to GGUF and run it with Ollama
The skill is open source. You may extend it, customize it on your workflows, or use it as a place to begin for other training scenarios.