
Constructing a sturdy visual inspection pipeline for defect detection and quality control will not be easy. Manufacturers and developers often face challenges equivalent to customizing general-purpose vision AI models for specialised domains, optimizing the model size on compute‑constrained edge devices, and deploying in real time for max inference throughput.
NVIDIA Metropolis is a development platform for vision AI agents and applications that helps to resolve these challenges. Metropolis provides the models and tools to construct visual inspection workflows spanning multiple stages, including:
- Customizing vision foundation models through fine-tuning
- Optimizing the models for real‑time inference
- Deploying the models into production pipelines
NVIDIA Metropolis provides a unified framework and includes NVIDIA TAO 6 for training and optimizing vision AI foundation models, and NVIDIA DeepStream 8, an end-to-end streaming analytics toolkit. NVIDIA TAO 6 and NVIDIA DeepStream 8 are actually available for download. Learn more in regards to the latest feature updates within the NVIDIA TAO documentation and NVIDIA DeepStream documentation.
This post walks you thru find out how to construct an end-to-end real-time visual inspection pipeline using NVIDIA TAO and NVIDIA DeepStream. The steps include:
- Performing self-supervised fine-tuning with TAO to leverage domain-specific unlabeled data.
- Optimizing foundation models using TAO knowledge distillation for higher throughput and efficiency.
- Deploying using DeepStream Inference Builder, a low‑code tool that turns model ideas into production-ready , standalone applications or deployable microservices.
How you can scale custom model development with vision foundation models using NVIDIA TAO
NVIDIA TAO supports the end-to-end workflow for training, adapting, and optimizing large vision foundation models for domain specific use cases. It’s a framework for customizing vision foundation models to attain high accuracy and performance with fine-tuning microservices.
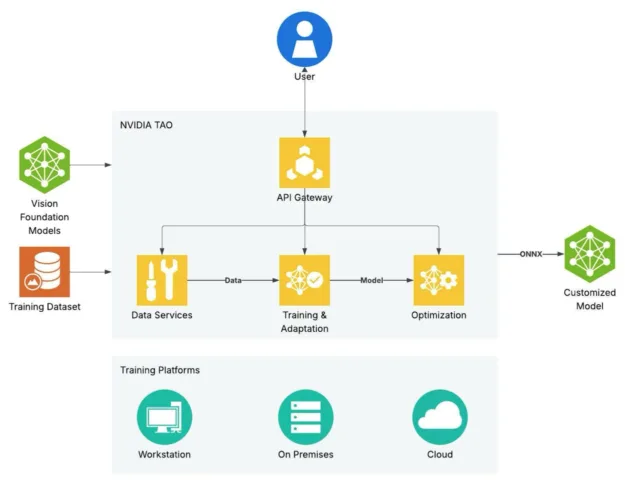
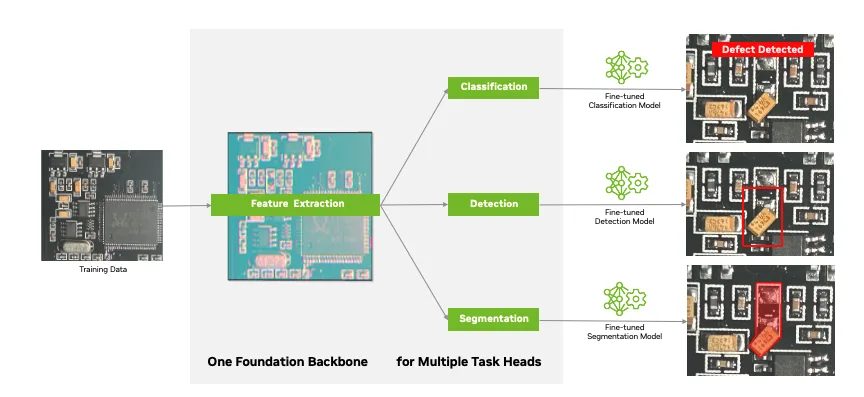
Vision foundation models (VFMs) are large-scale neural networks trained on massively diverse datasets to capture generalized and powerful visual feature representations. This generalization makes them a versatile model backbone for a wide selection of AI perception tasks equivalent to image classification, object detection, and semantic segmentation.
TAO provides a group of those powerful foundation backbones and task heads to fine-tune models on your key workloads like industrial visual inspection. The 2 key foundation backbones in TAO 6 are C-RADIOv2 (highest out-of-the-box accuracy) and NV-DINOv2. TAO also supports third-party models, provided their vision backbone and task head architectures are compatible with TAO.
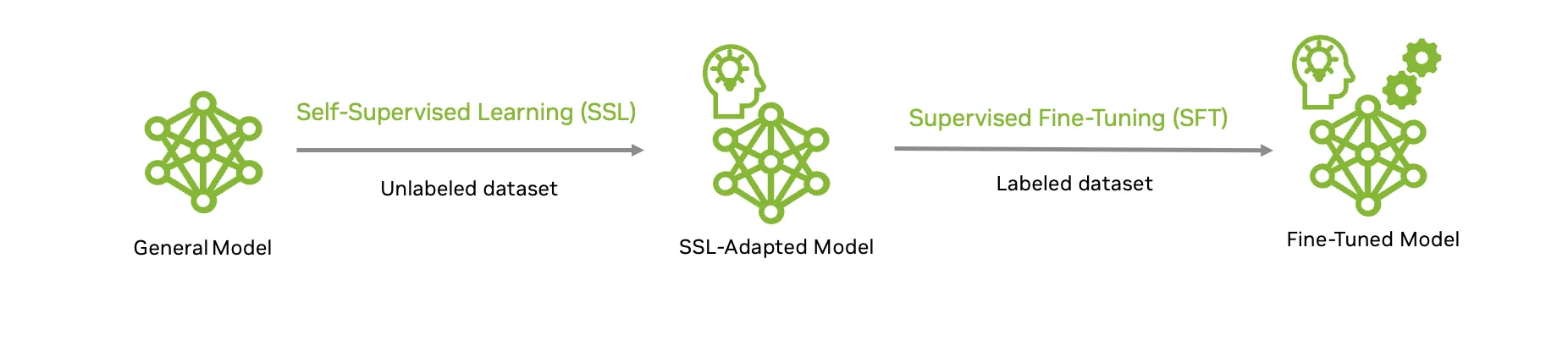
To spice up model accuracy, TAO supports multiple model customization techniques equivalent to supervised fine-tuning (SFT) and self-supervised learning (SSL). SFT requires collecting annotated datasets which are curated for the particular computer vision downstream tasks. Collecting high-quality labeled data is a fancy, manual process that’s time-consuming and expensive.
Second, NVIDIA TAO 6 empowers you to leverage self-supervised learning to tap into the vast potential of unlabeled images to speed up the model customization process where labeled data is scarce or expensive to accumulate.
This approach, also called domain adaption, lets you construct a sturdy foundation model backbone equivalent to NV-DINOv2 with unlabeled data. This will then be combined with a task head and fine-tuned for various downstream inspection tasks with a smaller annotated dataset.
In practical scenarios, this workflow means a model can learn the nuanced characteristics of defects from plentiful unlabeled images, then sharpen its decision-making with targeted supervised fine-tuning, delivering state-of-the-art performance even on customized, real-world datasets.
Boosting PCB defect detection accuracy with foundation model fine-tuning
To offer an example, we applied the TAO foundation model adaptation workflow using large-scale unlabeled printed circuit board (PCB) images to fine-tune a vision foundation model for defect detection. Starting with NV-DINOv2, a general-purpose model trained on 700 million general images, we customized it with SSL for PCB applications with a dataset of ~700,000 unlabeled PCB images. This helped transition the model from broad generalization, to sharp domain-specific proficiency.
Once domain adaptation is complete, we leveraged an annotated PCB dataset, using linear probing to refine the task-specific head for accuracy, and full fine-tuning to further adjust each backbone and a classification head. This primary dataset consisted of around 600 training and 400 testing samples, categorizing images as OK or Defect (including patterns equivalent to missing, shifts, upside-down, poor soldering, and foreign objects).
Feature maps show that the adapted NV-DINOv2 can sharply distinguish components and foreground-background (Figures 4 and 5) even before downstream fine-tuning. It excels in separating complex items like integrated circuit (IC) pins from the background—a task that’s impossible with a general model.


This leads to substantial classification accuracy improvements of 4.7% from 93.8% to 98.5%.
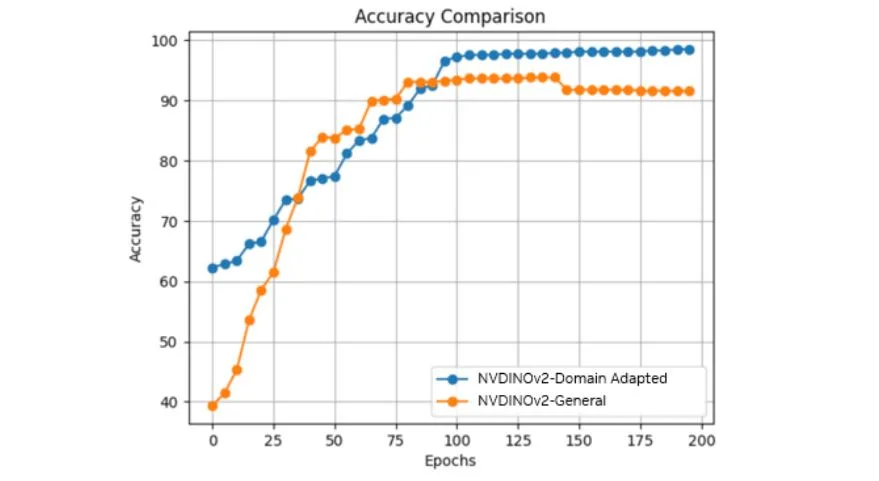
The domain-adapted NV-DINOv2 also shows strong visual understanding and extracting relevant image features throughout the same domain. This means that similar or higher accuracy might be achieved using less labeled data with downstream supervised fine-tuning.
In certain scenarios, gathering such a considerable amount of information with 0.7 million unlabeled images could still be difficult. Nonetheless, you may still profit from NV-DINOv2 domain adaptation even with a smaller dataset.
Figure 7 shows the outcomes of running an experiment adapting NV-DINOv2 with just 100K images, which also outperforms the final NV-DINOv2 model.
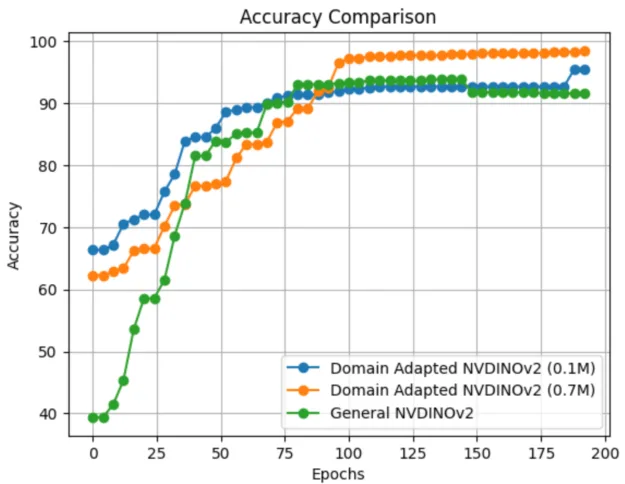
This instance illustrates how leveraging self-supervised learning on unlabeled domain data using NVIDIA TAO with NV-DINOv2 can yield robust, accurate PCB defect inspection while reducing reliance on large amounts of labeled samples.
How you can optimize vision foundation models for higher throughput
Optimization is a vital step in deploying deep learning models. Many generative AI and vision foundation models could have hundred million parameters which make them compute hungry and too big for many edge devices which are utilized in real-time applications equivalent to industrial visual inspection or real-time traffic monitoring systems.
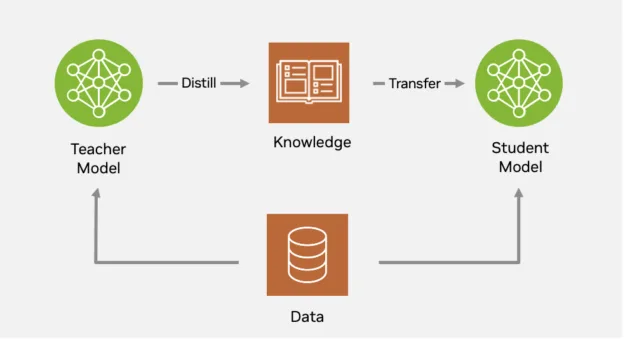
NVIDIA TAO leverages knowledge from these larger foundation models and optimizes them into smaller model sizes using a method called knowledge distillation. Knowledge distillation compresses large, highly-accurate teacher models into smaller, faster student models, often without losing accuracy. This process works by having the scholar mimic not only the ultimate predictions, but in addition the inner feature representations and decision boundaries of the teacher, making deployment practical on resource-constrained hardware and enabling scalable model optimization.
NVIDIA TAO takes knowledge distillation further with its robust support for various forms, including backbone, logit, and spatial/feature distillation. A standout feature in TAO is its single-stage distillation approach, designed specifically for object detection. With this streamlined process, a student model—often much smaller and faster—learns each backbone representations and task-specific predictions directly from the teacher in a single unified training phase. This allows dramatic reductions in inference latency and model size, without sacrificing accuracy.
Applying single-stage distillation for a real-time PCB defect detection model
The effectiveness of distillation using TAO was evaluated on a PCB defect detection dataset comprising 9,602 training images and 1,066 test images, covering six difficult defect classes: missing hole, mouse bite, open circuit, short, spur, and spurious copper. Two distinct teacher model candidates were used to judge the distiller. The experiments were performed with backbones that were initialized from the ImageNet-1K pretrained weights, and results were measured based on the usual COCO mean Average Precision (mAP) for object detection.
In our first set of experiments, we ran the identical distillation experiments using the ResNet series of backbones within the teacher-student combination, where the accuracy of student models not only matches but may even exceed their teacher model’s accuracy.
The baseline experiments are run as train actions related to the RT-DETR model in TAO. The next snippet shows a minimum viable experiment spec file that you may use to run a training experiment.
model:
backbone: resnet_50
train_backbone: true
num_queries: 300
num_classes: 7
train:
num_gpus: 1
epochs: 72
batch_size: 4
optim:
lr: 1e-4
lr_backbone: 1.0e-05
dataset:
train_data_sources:
- image_dir: /path/to/dataset/images/train
json_file: /path/to/dataset/annotations/train.json
val_data_sources:
image_dir: /path/to/dataset/images/val
json_file: /path/to/dataset/annotations/val.json
test_data_sources:
image_dir: /path/to/dataset/images/test
json_file: /path/to/dataset/annotations/test.json
batch_size: 4
remap_coco_categories: false
augmentation:
multiscales: [640]
train_spatial_size: [640, 640]
eval_spatial_size: [640, 640]
To run train, use the next command:
tao model rtdetr train -e /path/to/experiment/spec.yaml results_dir=/path/to/results/dir model.backbone=backbone_name model.pretrained_backbone_path=/path/to/the/pretrained/model.pth
You may change the backbone by overriding the model.backbone parameter to the name of the backbone and model.pretrained_backbone_path to the trail to the pretrained checkpoint file for the backbone.
A distillation experiment is run as a distill motion related to the RT-DETR model in TAO. To configure the distill experiment, you may add the next config element to the unique train experiment spec file.
distill:
teacher:
backbone: resnet_50
pretrained_teacher_model_path: /path/to/the/teacher/checkpoint.pth
Run distillation using the next sample command:
tao model rtdetr distill -e /path/to/experiment/spec/yaml results_dir=/path/to/results/dir model.backbone=backbone_namemodel.pretrained_backbone_path=/path/to/pretrained/backbone/checkpoint.pth distill.teacher.backbone=teacher_backbone_name distill.pretrained_teacher_model_path=/path/to/the/teacher/model.pth
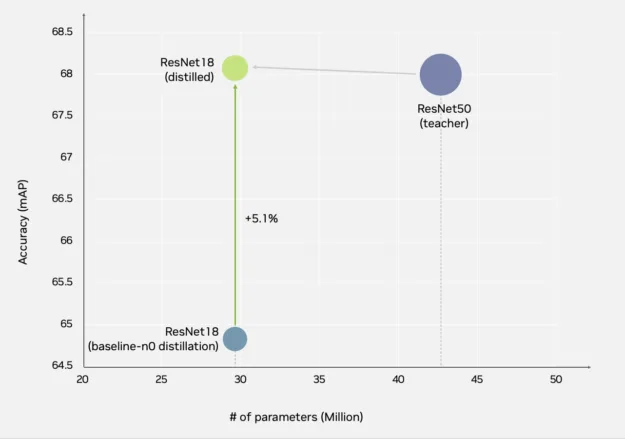
While deploying a model on edge, each inference acceleration and memory limit may very well be of serious consideration. TAO enables distilling detection features not only throughout the same family of backbones, but in addition across backbone families.
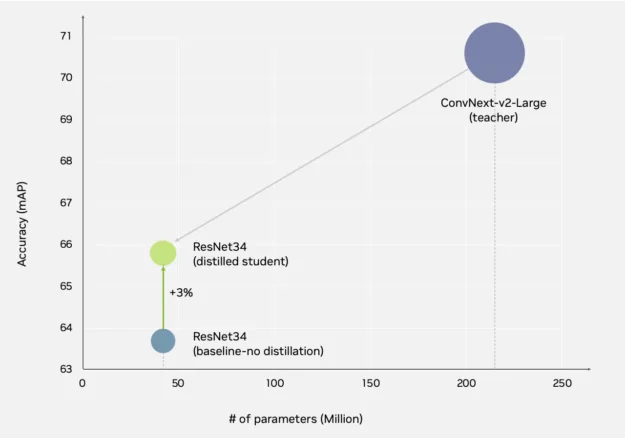
In this instance, we used a ConvNeXt based RT-DETR model because the teacher and distilled it to a lighter ResNet34-based model. Through single-stage distillation, TAO improved accuracy by 3%, reducing the model size by 81% for higher throughput, low-latency inference.
How you can package and deploy models with DeepStream 8 Inference Builder
Now with a trained and distilled RT-DETR model from TAO, the subsequent step is to deploy it as an inference microservice. The brand new NVIDIA DeepStream 8 Inference Builder is a low‑code tool that turns model ideas into standalone applications or deployable microservices.
To make use of the Inference Builder, provide a YAML configuration, a Dockerfile and an optional OpenAPI definition. The Inference Builder then generates Python code that connects the info loading, GPU‑accelerated preprocessing, inference, and post‑processing stages, and may expose REST endpoints for microservice deployments.
It’s designed to automate the generation of inference service code, API layers, and deployment artifacts from a user-provided model and configuration files. This eliminates the necessity for manual development of boilerplate code pertaining to servers, request handling, and data flow, as a straightforward configuration suffices for Inference Builder to administer these complexities.
Step 1: Define the configuration
- Create a
config.yamlfile to delineate your model and inference pipeline - (Optional) Incorporate an
openapi.yamlfile if explicit API schema definition is desired
Step 2: Execute the DeepStream Inference Builder
- Submit the configuration to Inference Builder
- This utility leverages inference templates, server templates, and utilities (codec, for instance) to autonomously generate project code
- The output constitutes a comprehensive package, encompassing inference logic, server code, and auxiliary utilities
- Output
infer.tgz, a packaged inference service
Step 3: Examine the generated code
The package expands right into a meticulously organized project, featuring:
- Configuration:
config/ - Server logic:
server/ - Inference library:
lib/ - Utilities: asset manager, codec, responders, and so forth
Step 4: Construct a Docker image
- Use the reference Dockerfile to containerize the service
- Execute
docker construct -t my-infer-service
Step 5: Deploy with Docker Compose
- Initiate the service using Docker Compose:
docker-compose up - The service will subsequently load your models throughout the container
Step 6: Serve to users
- Your inference microservice is now operational
- End users or applications can dispatch requests to the exposed API endpoints and receive predictions directly out of your model
To learn more in regards to the NVIDIA DeepStream Inference Builder, visit NVIDIA-AI-IOT/deepstream_tools on GitHub.
Additional applications for real-time visual inspection
Along with identifying PCB defects you may as well apply TAO and DeepStream to identify anomalies in industries equivalent to automotive and logistics. To examine a particular use case, see Slash Manufacturing AI Deployment Time with Synthetic Data and NVIDIA TAO.
Start constructing a real-time visual inspection pipeline
With NVIDIA DeepStream and NVIDIA TAO, developers are pushing the boundaries of what’s possible in vision AI—from rapid prototyping to large-scale deployment.
DeepStream 8.0 equips developers with powerful tools just like the Inference Builder to streamline pipeline creation and improve tracking accuracy across complex environments. TAO 6 unlocks the potential of foundation models through domain adaptation, self-supervised fine-tuning, and knowledge distillation.
This translates into faster iteration cycles, higher use of unlabeled data, and production-ready inference services.
Able to start?
Download NVIDIA TAO 6 and explore the newest features. Ask questions and join the conversation within the NVIDIA TAO Developer Forum.
Download NVIDIA DeepStream 8 and explore the newest features. Ask questions and join the conversation within the NVIDIA DeepStream Developer Forum.