
Financial portfolio optimization is a difficult yet essential task that has been consistently challenged by a trade-off between computational speed and model complexity. For the reason that introduction of Markowitz Portfolio Theory 70 years ago, robust evaluation beyond basic mean-variance—similar to large-scale simulations, multistep optimizations, or richer risk measures—was too slow for dynamic decision-making, blocking rapid iteration.
The Quantitative Portfolio Optimization developer example, introduced on this post, is designed to eliminate this trade-off. With high-performance hardware and parallel algorithms, it transforms optimization from a slow, batch process right into a fast, iterative workflow.
The pipeline enables scalable strategy backtesting and interactive evaluation. NVIDIA cuOpt open source solvers enable efficient solutions to scenario-based Mean-CVaR portfolio optimization problems. These consistently outperform state-of-the-art open source CPU-based solvers, with as much as 160x speedups in large-scale problems.
Quantitative Portfolio Optimization also takes advantage of the broader CUDA ecosystem. The CUDA-X Data Science library accelerates pre-optimization data preprocessing and scenario generation, delivering speedups of as much as 100x when learning and sampling from return distributions.
Mathematical foundations of portfolio optimization
An optimal portfolio should maximize expected return while minimizing risk. The classical risk-return trade-off formulation introduced by Markowitz could be written as:
where 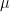
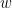
Traditionally, variance of portfolio returns is used because the measure of risk. Here, Conditional Value-at-Risk (CVaR) was chosen instead risk measure since it provides a more robust assessment of potential tail losses. It also allows for a data-driven approach to portfolio optimization without making assumptions on the underlying returns distribution. CVaR measures the typical worst-case lack of a return distribution.
Formally, for a loss random variable 
![CVaR = {E}[L| L geq VaR_alpha (L)]](https://s0.wp.com/latex.php?latex=CVaR+%3D+%7BE%7D%5BL%7C+L+%5Cgeq+VaR_%5Calpha+%28L%29%5D&bg=transparent&fg=000&s=0&c=20201002)
where 

Figure 1 shows the probability distribution of each day log returns. The 95% VaR, marked by the red dashed line at -4.35%, indicates that the portfolio loss isn’t expected to exceed 4.35% with 95% confidence. The 95% CVaR, marked by the blue dashed line at -5.58%, represents the typical loss on the worst 5% of scenarios (the shaded tail region).

CVaR is a more appropriate risk measure for portfolios that will contain assets with asymmetric return distribution and has replaced VaR in Basel III market-risk rules. Mathematically, CVaR is a coherent risk measure—satisfying subadditivity, translation invariance, positive homogeneity, and monotonicity—which aligns with the diversification principles.
Furthermore, it has a computationally tractable transformation as a scenario-based optimization: for confidence level

where 

Intuitively, this expression represents the portfolio’s average loss below the 

num_scenarios, num_assets), the minimization of the CVaR could be transformed right into a linear program by replacing the 

Integrating this right into a risk-return tradeoff formulation leads to the next the mathematical optimization problem of maximizing the CVaR-risk-adjusted return:
Additional constraints were added to model real-world trading limitations including the concentration limits on investment budgets (




Shifting portfolio optimization from CPU to GPU
This mean-CVaR problem is characterised by a linear objective and linear constraints, with complexity scaling linearly with the variety of return scenarios and tradable assets. Tradable assets are sometimes hundreds in practical investment settings, and a complicated scenario generation engine can easily produce tons of of hundreds of various return scenarios.
As the issue size grows, high-performance solvers grow to be increasingly vital for efficient optimization. That is addressed by leveraging the cuOpt Linear Program (LP) solver, which implements the Primal-Dual Hybrid Gradient for Linear Programming (PDLP) algorithm on GPUs. For giant-scale problems (often with over 10K variables and 10K constraints), the complete power of cuOpt is unlocked, drastically reducing the solve time.
Accelerated workflow example
This section showcases the Quantitative Portfolio Optimization developer example on a 397-stock subset of the S&P 500. The aim is to construct a long-short portfolio that maximizes risk-adjusted returns while meeting custom trading constraints. As shown in Figure 2, the workflow unfolds in 4 steps:
- Data preparation: Estimate returns and generate CVaR scenarios from historical prices
- Optimization setup: Construct the Mean–CVaR problem using the preprocessed data
- Solve: Run the cuOpt solver to acquire portfolio weights
- Backtest: Visualize the optimized portfolio and compute performance metrics

Step 1: Data preparation
Assume the return distribution is stationary over the optimization period and use historical returns to approximate future ones. If this assumption doesn’t hold, you might as an alternative optimize over a forecasted return distribution that accounts for potential shifts in market conditions.
For example of the previous approach, load closing prices from 2022-01-01 to 2024-07-01 and compute each day log‐returns. Next, fit a Kernel Density Estimator (KDE) to those returns and simulate 20K return scenarios.
...
# Define the settings for returns computation
returns_compute_settings = {'return_type': 'LOG', 'freq': 1}
# Compute returns from price data
returns_dict = utils.calculate_returns(
data_path,
regime_dict,
returns_compute_settings
)
...
# Define the settings for scenario generation
scenario_generation_settings = {
'num_scen': 20000, # Variety of return scenarios to simulate
'fit_type': 'kde',
'kde_settings': {'bandwidth': 0.01,
'kernel': 'gaussian',
'device': 'GPU'
},
'verbose': False
}
# Generate return scenarios from KDE
sp500_returns_dict = cvar_utils.generate_cvar_data(
returns_dict,
scenario_generation_settings
)
Notably, using GPU acceleration through cuML for KDE fitting and sampling yields significant acceleration in comparison with CPU, especially as dataset sizes and the variety of scenarios to sample increase. Figure 3 shows a direct comparison of cuML GPU speedups, represented by CPU time divided by GPU time, as compute demands rise.

GPU: NVIDIA H200; CPU: Intel Xeon Platinum 8480+ processor
Step 2: Optimization setup
The next parameters are used to establish a Mean-CVaR portfolio optimization problem:
# Define CVaR optimization parameters for the S&P 500 example
sp500_cvar_params = CvarParameters(
#Asset weight allocation bounds
w_min={'NVDA':0.1, 'others': -0.3}, w_max={'NVDA':0.6, 'others':0.4},
c_min=0.0, c_max=0.2, # Money holdings bounds
L_tar=1.6, # Leverage
T_tar=None, # Turnover (None for this instance)
cvar_limit=None, # Hard limit on CVaR (None = unconstrained)
cardinality = None, # Max variety of assets allowed within the portfolio
risk_aversion=1.0, # Risk aversion level
confidence=0.95, # CVaR confidence level
)
All of the optimization parameters could be customized. For instance, you’ll be able to adjust per-asset concentration limits by specifying the ticker and the specified weights constraints in a dictionary. It’s also possible to adjust the danger aversion level (higher risk averseness generally results in more diversification). Finally, you’ll be able to restrict the variety of assets within the optimal portfolio by adding a cardinality constraint.
Then, use the returns data from Step 1 and the issue parameters to formulate the issue:
# Instantiate CVaR optimization problem for the S&P 500 example
sp500_cvar_problem = cvar_optimizer.CVaR(
returns_dict=sp500_returns_dict,
cvar_params=sp500_cvar_params
)
Step 3: Solve
Next, call the cuOpt LP solver and acquire the optimized portfolio. It’s also possible to provide customized configurations to the cuOpt LP solver, including solver mode, accuracy, and so forth. For more details, see the cuOpt documentation.
For this instance, use the cuOpt PDLP default tolerance of 1e-4, and by default, cuOpt runs PDLP, barrier, and dual simplex methods in parallel. It returns the answer from whichever method completes first.
# GPU solver settings
gpu_solver_settings = {"solver": cp.CUOPT,
"verbose": False,
"solver_method": "Concurrent",
"time_limit":15,
"optimality": 1e-4
}
# Solve on GPU
gpu_results, gpu_portfolio = cvar_problem.solve_optimization_problem(solver_settings=gpu_solver_settings)
The optimized portfolio—under the desired constraints and risk‐aversion level—chooses long positions in 12 stocks and short positions in 2 stocks out of the 397 stocks. Also confirm from the outcomes that the optimized portfolio satisfies all of the constraints.
============================================================
CVaR OPTIMIZATION RESULTS
============================================================
PROBLEM CONFIGURATION
------------------------------
Solver: CUOPT
Regime: recent
Time Period: 2021-01-01 to 2024-01-01
Scenarios: 20,000
Assets: 397
Confidence Level: 95.0%
PERFORMANCE METRICS
------------------------------
Expected Return: 0.002537 (0.2537%)
CVaR (95%): 0.025700 (2.5700%)
Objective Value: -0.001396
SOLVING PERFORMANCE
------------------------------
Setup Time: 0.4921 seconds
Solve Time: 0.3685 seconds
OPTIMAL PORTFOLIO ALLOCATION
------------------------------
PORTFOLIO: CUOPT_OPTIMAL
----------------------------------------
Period: 2021-01-01 to 2024-01-01
LONG POSITIONS (12 assets)
-------------------------
LLY 0.326 ( 32.64%)
NVDA 0.151 ( 15.11%)
MCK 0.136 ( 13.60%)
IT 0.101 ( 10.13%)
IRM 0.098 ( 9.84%)
JBL 0.097 ( 9.71%)
PWR 0.083 ( 8.25%)
STLD 0.070 ( 6.96%)
COP 0.056 ( 5.64%)
FICO 0.043 ( 4.28%)
MRO 0.021 ( 2.07%)
NUE 0.018 ( 1.78%)
Total Long 1.200 (120.01%)
SHORT POSITIONS (2 assets)
--------------------------
MTCH -0.248 (-24.85%)
ILMN -0.148 (-14.82%)
Total Short -0.397 (-39.67%)
CASH & SUMMARY
--------------------
Money 0.200 ( 20.00%)
Residual 0.000 ( 0.01%)
Net Equity 0.803 ( 80.33%)
Total Portfolio 1.003 (100.35%)
Gross Exposure 1.597 (159.68%)
----------------------------------------
============================================================
The developer example streamlines the solver calls, making it very easy to make use of any solver. With zero code changes, you’ll be able to call a special solver by changing the solver settings. For instance, to check performance against a CPU solver, simply declare a brand new solver:
solver_settings = {'solver': "CUSTOM_SOLVER", 'verbose': False}
#solve the optimization problem using an open-source CPU solver
cpu_results, cpu_portfolio = cvar_problem.solve_optimization_problem(solver_settings)
Table 1 compares the performance of the cuOpt solver against a state-of-the-art open source CPU solver, solving problems with 20,796 variables and 20,796 constraints with roughly 8 million nonzero entries within the constraint matrix. Set each solvers with an optimality tolerance of 1e-4, and for cuOpt, select the PDLP solve method.
The cuOpt solver was run on the NVIDIA H200 GPU, and the CPU solver was using the Intel Xeon Platinum 8480+ processor. The cuOpt LP solver consistently outperforms the CPU solver, reducing solve time from minutes to the subsecond range.
| CPU Solver | cuOpt GPU Solver | Speedup versus CPU |
|
| Regime | Solver time (s) | Solver time (s) | X |
| Pre-crisis (‘2005-01-01’, ‘2007-10-01’) |
70.36 | 0.53 | 131.7 |
| Crisis (‘2007-10-01’, ‘2009-04-01’) |
42.19 | 0.92 | 45.8 |
| Post-crisis (‘2009-06-30’, ‘2014-06-30’) |
75.50 | 0.45 | 167.4 |
| Oil price crash (‘2014-06-01’, ‘2016-03-01’) |
53.43 | 0.51 | 105.6 |
| FAANG surge (‘2015-01-01’, ‘2021-01-01’) |
49.89 | 0.73 | 68.0 |
| Covid (‘2020-01-01’, ‘2023-01-01’) |
57.43 | 0.66 | 86.5 |
| Recent (‘2022-01-01’, ‘2024-07-01’) |
56.32 | 0.56 | 99.5 |
20K scenario; 397 assets; GPU: NVIDIA H200; CPU: Intel Xeon Platinum 8480+
The efficient frontier is a set of optimal investment portfolios that provide the very best expected return for a given level of risk or the bottom risk for a specified expected return. To compute the efficient frontier, it’s vital to resolve a sequence of optimization problems for various risk aversion levels.
For instance, in Figure 4, an efficient frontier of fifty optimal portfolios with different risk-aversion levels is generated. The video in 4x speed shows that the cuOpt GPU solver enables generating the efficient frontier much faster than using a CPU solver in real time.

Step 4: Backtest
Finally, you’ll be able to backtest the optimized portfolio and evaluate some key metrics similar to cumulative returns, Sharpe Ratio, and max drawdown. In the next example, the backtester is initiated and in comparison with the performance of the optimized portfolio against an equal-weight portfolio (allocate equal weights in every available asset):
from src import backtest
# Create backtester and run backtest
backtester = backtest.portfolio_backtester(gpu_portfolio, test_returns_dict, risk_free, test_method, benchmark_portfolios = None)
backtest_result,_ = backtester.backtest_against_benchmarks(plot_returns=True, cut_off_date=cut_off_date)
Through the backtest period, with the dashed line indicating the beginning of out-of-sample testing, the optimized portfolio consistently outperformed the equal-weight benchmark and generated substantially greater value.

Dynamic rebalancing
Dynamic rebalancing is critical because a once‑optimal portfolio drifts as market conditions evolve—the estimated returns distribution is nonstationary. Fairly than holding a static allocation, trigger‑based rebalancing (for instance, portfolio value moves or weight deviations) adjusts exposures to guard against downside risk and keep the portfolio aligned with the danger budget in real time.
This requires repeated re‑optimization. Exploring different rebalancing strategies often means tons of of iterations, so optimization time scales with the variety of repetitions. A quick, accurate solver is crucial: the Quantitative Portfolio Optimization developer example can complete these tasks in minutes as an alternative of hours or days on a conventional CPU solver.
For instance, compare two strategies—value‑percentage change and allocation drift—against buy‑and‑hold from 2022‑07‑01 to 2024‑05‑01. The portfolio is backtested every three months (63 trading days), and if the monitored metric exceeds a user‑defined threshold, re‑optimization is triggered.
In Figure 6, rebalancing occurs when the portfolio value experiences a cumulative 0.5% drop for the reason that last positive change. Over the period, the rule triggered 4 times, producing a 15.6% total return and outperforming buy‑and‑hold.


Figure 8 shows testing a special strategy, where rebalancing is triggered when the present portfolio composition shifts away from the unique allocation. As prices move, weights drift and the portfolio may not meet required constraints, justifying a re‑optimization with latest market data. Again, the rebalancing strategy stays on top of the market and yields a positive return.


Portfolio optimization is a repeated core task fairly than a one‑time effort—the acceleration cuOpt delivers for a single optimization problem will likely be magnified in energetic trading environments. There are more sophisticated strategies with more hyperparameters, and trying to find the optimal strategy would require repeating the above process countless times. In other words, these example strategies highlight GPU acceleration and usually are not optimized for deployment. To seek out the optimal strategies, many more iterations of optimization are needed.
Start with portfolio optimization
Optimization workflows are only as fast as their slowest step. By moving data preparation, scenario generation, and solving to GPUs, the Quantitative Portfolio Optimization developer example eliminates common bottlenecks and reduces solve times from minutes and hours to seconds. The payoff grows in repeated workflows—reallocation, sweeping parameter spaces, stress tests, and backtests—where tons of of re-optimizations are routine.
With cuOpt for LP solving and CUDA-X DS for preprocessing and simulation, you’ll be able to iterate more incessantly, test richer constraints, and reply to market changes in near real-time. The result is quicker time‑to‑insight, higher use of CVaR‑based models at scale, and a practical path to dynamic rebalancing. The Quantitative Portfolio Optimization developer example makes large‑scale, risk‑aware portfolio optimization an interactive capability fairly than a batch chore.
Transform portfolio optimization with GPU acceleration and run complex risk models and allocations in real time. Achieve faster insights, scalable performance, and smarter, data-driven investment strategies.
Visit construct.nvidia.com to deploy the notebook in a GPU-accelerated environment with either NVIDIA Brev or your personal cloud infrastructure using the Quantitative Portfolio Optimization notebook on GitHub.