
![]()
In our previous post, Exploring Quantization Backends in Diffusers, we dived into how various quantization techniques can shrink diffusion models like FLUX.1-dev, making them significantly more accessible for inference without drastically compromising performance. We saw how bitsandbytes, torchao, and others reduce memory footprints for generating images.
Performing inference is cool, but to make these models truly our own, we also have to have the option to fine-tune them. Subsequently, on this post, we tackle efficient fine-tuning of those models with peak memory use under ~10 GB of VRAM on a single GPU. This post will guide you thru fine-tuning FLUX.1-dev using QLoRA with the diffusers library. We’ll showcase results from an NVIDIA RTX 4090. We’ll also highlight how FP8 training with torchao can further optimize speed on compatible hardware.
Table of Contents
Dataset
We aim to fine-tune black-forest-labs/FLUX.1-dev to adopt the artistic variety of Alphonse Mucha, using a small dataset.
FLUX Architecture
The model consists of three major components:
- Text Encoders (CLIP and T5)
- Transformer (Predominant Model – Flux Transformer)
- Variational Auto-Encoder (VAE)
In our QLoRA approach, we focus exclusively on fine-tuning the transformer component. The text encoders and VAE remain frozen throughout training.
QLoRA Positive-tuning FLUX.1-dev with Diffusers
We used a diffusers training script (barely modified from here designed for DreamBooth-style LoRA fine-tuning of FLUX models. Also, a shortened version to breed the leads to this blogpost (and utilized in the Google Colab) is out there here. Let’s examine the crucial parts for QLoRA and memory efficiency:
Key Optimization Techniques
LoRA (Low-Rank Adaptation) Deep Dive: LoRA makes model training more efficient by keeping track of the load updates with low-rank matrices. As an alternative of updating the complete weight matrix , LoRA learns two smaller matrices and . The update to the weights for the model is , where and . The number (called rank) is way smaller than the unique dimensions, which implies less parameters to update. Lastly, is a scaling factor for the LoRA activations. This affects how much LoRA affects the updates, and is usually set to the identical value because the or a multiple of it. It helps balance the influence of the pre-trained model and the LoRA adapter. For a general introduction to the concept, take a look at our previous blog post: Using LoRA for Efficient Stable Diffusion Positive-Tuning.
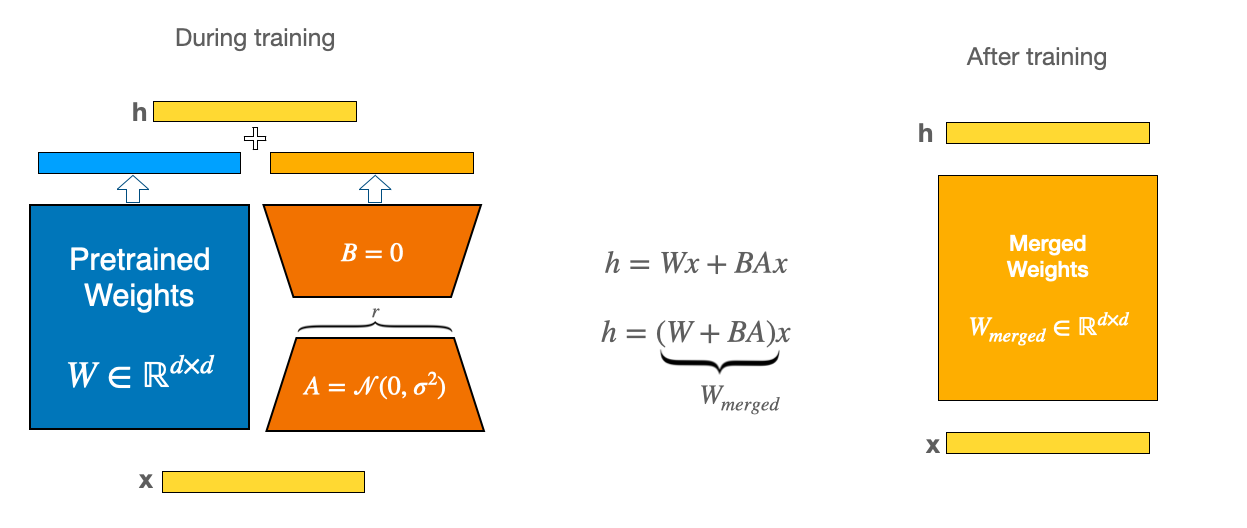
QLoRA: The Efficiency Powerhouse: QLoRA enhances LoRA by first loading the pre-trained base model in a quantized format (typically 4-bit via bitsandbytes), drastically cutting the bottom model’s memory footprint. It then trains LoRA adapters (normally in FP16/BF16) on top of this quantized base. This dramatically lowers the VRAM needed to carry the bottom model.
As an example, within the DreamBooth training script for HiDream 4-bit quantization with bitsandbytes reduces the height memory usage of a LoRA fine-tune from ~60GB right down to ~37GB with negligible-to-none quality degradation. The exact same principle is what we apply here to fine-tune FLUX.1 on a consumer-grade hardware.
8-bit Optimizer (AdamW):
Standard AdamW optimizer maintains first and second moment estimates for every parameter in 32-bit (FP32), which consumes lots of memory. The 8-bit AdamW uses block-wise quantization to store optimizer states in 8-bit precision, while maintaining training stability. This system can reduce optimizer memory usage by ~75% compared to plain FP32 AdamW. Enabling it within the script is easy:
if args.use_8bit_adam:
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
optimizer = optimizer_class(
params_to_optimize,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
Gradient Checkpointing:
During forward pass, intermediate activations are typically stored for backward pass gradient computation. Gradient checkpointing trades computation for memory by only storing certain checkpoint activations and recomputing others during backpropagation.
if args.gradient_checkpointing:
transformer.enable_gradient_checkpointing()
Cache Latents:
This optimization technique pre-processes all training images through the VAE encoder before the start of the training. It stores the resulting latent representations in memory. Through the training, as a substitute of encoding images on-the-fly, the cached latents are directly used. This approach offers two major advantages:
- eliminates redundant VAE encoding computations during training, speeding up each training step
- allows the VAE to be completely faraway from GPU memory after caching. The trade-off is increased RAM usage to store all cached latents, but this is usually manageable for small datasets.
if args.cache_latents:
latents_cache = []
for batch in tqdm(train_dataloader, desc="Caching latents"):
with torch.no_grad():
batch["pixel_values"] = batch["pixel_values"].to(
accelerator.device, non_blocking=True, dtype=weight_dtype
)
latents_cache.append(vae.encode(batch["pixel_values"]).latent_dist)
del vae
free_memory()
Establishing 4-bit Quantization (BitsAndBytesConfig):
This section demonstrates the QLoRA configuration for the bottom model:
bnb_4bit_compute_dtype = torch.float32
if args.mixed_precision == "fp16":
bnb_4bit_compute_dtype = torch.float16
elif args.mixed_precision == "bf16":
bnb_4bit_compute_dtype = torch.bfloat16
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=bnb_4bit_compute_dtype,
)
transformer = FluxTransformer2DModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="transformer",
quantization_config=nf4_config,
torch_dtype=bnb_4bit_compute_dtype,
)
transformer = prepare_model_for_kbit_training(transformer, use_gradient_checkpointing=False)
Defining LoRA Configuration (LoraConfig):
Adapters are added to the quantized transformer:
transformer_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
init_lora_weights="gaussian",
target_modules=["to_k", "to_q", "to_v", "to_out.0"],
)
transformer.add_adapter(transformer_lora_config)
print(f"trainable params: {transformer.num_parameters(only_trainable=True)} || all params: {transformer.num_parameters()}")
Only these LoRA parameters change into trainable.
Pre-computing Text Embeddings (CLIP/T5)
Before we launch the QLoRA fine-tune we are able to save an enormous chunk of VRAM and wall-clock time by caching outputs of text encoders once.
At training time the dataloader simply reads the cached embeddings as a substitute of re-encoding the caption, so the CLIP/T5 encoder never has to sit down in GPU memory.
Code
import argparse
import pandas as pd
import torch
from datasets import load_dataset
from huggingface_hub.utils import insecure_hashlib
from tqdm.auto import tqdm
from transformers import T5EncoderModel
from diffusers import FluxPipeline
MAX_SEQ_LENGTH = 77
OUTPUT_PATH = "embeddings.parquet"
def generate_image_hash(image):
return insecure_hashlib.sha256(image.tobytes()).hexdigest()
def load_flux_dev_pipeline():
id = "black-forest-labs/FLUX.1-dev"
text_encoder = T5EncoderModel.from_pretrained(id, subfolder="text_encoder_2", load_in_8bit=True, device_map="auto")
pipeline = FluxPipeline.from_pretrained(
id, text_encoder_2=text_encoder, transformer=None, vae=None, device_map="balanced"
)
return pipeline
@torch.no_grad()
def compute_embeddings(pipeline, prompts, max_sequence_length):
all_prompt_embeds = []
all_pooled_prompt_embeds = []
all_text_ids = []
for prompt in tqdm(prompts, desc="Encoding prompts."):
(
prompt_embeds,
pooled_prompt_embeds,
text_ids,
) = pipeline.encode_prompt(prompt=prompt, prompt_2=None, max_sequence_length=max_sequence_length)
all_prompt_embeds.append(prompt_embeds)
all_pooled_prompt_embeds.append(pooled_prompt_embeds)
all_text_ids.append(text_ids)
max_memory = torch.cuda.max_memory_allocated() / 1024 / 1024 / 1024
print(f"Max memory allocated: {max_memory:.3f} GB")
return all_prompt_embeds, all_pooled_prompt_embeds, all_text_ids
def run(args):
dataset = load_dataset("Norod78/Yarn-art-style", split="train")
image_prompts = {generate_image_hash(sample["image"]): sample["text"] for sample in dataset}
all_prompts = list(image_prompts.values())
print(f"{len(all_prompts)=}")
pipeline = load_flux_dev_pipeline()
all_prompt_embeds, all_pooled_prompt_embeds, all_text_ids = compute_embeddings(
pipeline, all_prompts, args.max_sequence_length
)
data = []
for i, (image_hash, _) in enumerate(image_prompts.items()):
data.append((image_hash, all_prompt_embeds[i], all_pooled_prompt_embeds[i], all_text_ids[i]))
print(f"{len(data)=}")
embedding_cols = ["prompt_embeds", "pooled_prompt_embeds", "text_ids"]
df = pd.DataFrame(data, columns=["image_hash"] + embedding_cols)
print(f"{len(df)=}")
for col in embedding_cols:
df[col] = df[col].apply(lambda x: x.cpu().numpy().flatten().tolist())
df.to_parquet(args.output_path)
print(f"Data successfully serialized to {args.output_path}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--max_sequence_length",
type=int,
default=MAX_SEQ_LENGTH,
help="Maximum sequence length to make use of for computing the embeddings. The more the upper computational costs.",
)
parser.add_argument("--output_path", type=str, default=OUTPUT_PATH, help="Path to serialize the parquet file.")
args = parser.parse_args()
run(args)
Tips on how to use it
python compute_embeddings.py
--max_sequence_length 77
--output_path embeddings_alphonse_mucha.parquet
By combining this with cached VAE latents (--cache_latents) you whittle the energetic model right down to just the quantized transformer + LoRA adapters, keeping the entire fine-tune comfortably under 10 GB of GPU memory.
Setup & Results
For this demonstration, we leveraged an NVIDIA RTX 4090 (24GB VRAM) to explore its performance. The complete training command using speed up is shown below.
speed up launch --config_file=speed up.yaml
train_dreambooth_lora_flux_miniature.py
--pretrained_model_name_or_path="black-forest-labs/FLUX.1-dev"
--data_df_path="embeddings_alphonse_mucha.parquet"
--output_dir="alphonse_mucha_lora_flux_nf4"
--mixed_precision="bf16"
--use_8bit_adam
--weighting_scheme="none"
--width=512
--height=768
--train_batch_size=1
--repeats=1
--learning_rate=1e-4
--guidance_scale=1
--report_to="wandb"
--gradient_accumulation_steps=4
--gradient_checkpointing
--lr_scheduler="constant"
--lr_warmup_steps=0
--cache_latents
--rank=4
--max_train_steps=700
--seed="0"
Configuration for RTX 4090:
On our RTX 4090, we used a train_batch_size of 1, gradient_accumulation_steps of 4, mixed_precision="bf16", gradient_checkpointing=True, use_8bit_adam=True, a LoRA rank of 4, and backbone of 512×768. Latents were cached with cache_latents=True.
Memory Footprint (RTX 4090):
- QLoRA: Peak VRAM usage for QLoRA fine-tuning was roughly 9GB.
- BF16 LoRA: Running standard LoRA (with the bottom FLUX.1-dev in FP16) on the identical setup consumed 26 GB VRAM.
- BF16 full finetuning: An estimate can be ~120 GB VRAM with no memory optimizations.
Training Time (RTX 4090):
Positive-tuning for 700 steps on the Alphonse Mucha dataset took roughly 41 minutes on the RTX 4090 with train_batch_size of 1 and backbone of 512×768.
Output Quality:
The final word measure is the generated art. Listed below are samples from our QLoRA fine-tuned model on the derekl35/alphonse-mucha-style dataset:
This table compares the first bf16 precision results. The goal of the fine-tuning was to show the model the distinct variety of Alphonse Mucha.
The fine-tuned model nicely captured Mucha’s iconic art nouveau style, evident in the ornamental motifs and distinct color palette. The QLoRA process maintained excellent fidelity while learning the brand new style.
Click to see the fp16 comparison
The outcomes are nearly equivalent, showing that QLoRA performs effectively with each fp16 and bf16 mixed precision.
Model Comparison: Base vs. QLoRA Positive-tuned (fp16)
FP8 Positive-tuning with TorchAO
For users with NVIDIA GPUs possessing compute capability 8.9 or greater (reminiscent of the H100, RTX 4090), even greater speed efficiencies may be achieved by leveraging FP8 training via the torchao library.
We fine-tuned FLUX.1-dev LoRA on an H100 SXM GPU barely modifieddiffusers-torchao training scripts. The next command was used:
speed up launch train_dreambooth_lora_flux.py
--pretrained_model_name_or_path=black-forest-labs/FLUX.1-dev
--dataset_name=derekl35/alphonse-mucha-style --instance_prompt="a girl, alphonse mucha style" --caption_column="text"
--output_dir=alphonse_mucha_fp8_lora_flux
--mixed_precision=bf16 --use_8bit_adam
--weighting_scheme=none
--height=768 --width=512 --train_batch_size=1 --repeats=1
--learning_rate=1e-4 --guidance_scale=1 --report_to=wandb
--gradient_accumulation_steps=1 --gradient_checkpointing
--lr_scheduler=constant --lr_warmup_steps=0 --rank=4
--max_train_steps=700 --checkpointing_steps=600 --seed=0
--do_fp8_training --push_to_hub
The training run had a peak memory usage of 36.57 GB and accomplished in roughly 20 minutes.
Qualitative results from this FP8 fine-tuned model are also available:

Key steps to enable FP8 training with torchao involve:
- Injecting FP8 layers into the model using
convert_to_float8_trainingfromtorchao.float8. - Defining a
module_filter_fnto specify which modules should and mustn’t be converted to FP8.
For a more detailed guide and code snippets, please discuss with this gist and the diffusers-torchao repository.
Inference with Trained LoRA Adapters
After training your LoRA adapters, you’ve gotten two major approaches for inference.
Option 1: Loading LoRA Adapters
One approach is to load your trained LoRA adapters on top of the bottom model.
Advantages of Loading LoRA:
- Flexibility: Easily switch between different LoRA adapters without reloading the bottom model
- Experimentation: Test multiple artistic styles or concepts by swapping adapters
- Modularity: Mix multiple LoRA adapters using
set_adapters()for creative mixing - Storage efficiency: Keep a single base model and multiple small adapter files
Code
from diffusers import FluxPipeline, FluxTransformer2DModel, BitsAndBytesConfig
import torch
ckpt_id = "black-forest-labs/FLUX.1-dev"
pipeline = FluxPipeline.from_pretrained(
ckpt_id, torch_dtype=torch.float16
)
pipeline.load_lora_weights("derekl35/alphonse_mucha_qlora_flux", weight_name="pytorch_lora_weights.safetensors")
pipeline.enable_model_cpu_offload()
image = pipeline(
"a puppy in a pond, alphonse mucha style", num_inference_steps=28, guidance_scale=3.5, height=768, width=512, generator=torch.manual_seed(0)
).images[0]
image.save("alphonse_mucha.png")
Option 2: Merging LoRA into Base Model
For once you want maximum efficiency with a single style, you may merge the LoRA weights into the bottom model.
Advantages of Merging LoRA:
- VRAM efficiency: No additional memory overhead from adapter weights during inference
- Speed: Barely faster inference as there isn’t any have to apply adapter computations
- Quantization compatibility: Can re-quantize the merged model for max memory efficiency
Code
from diffusers import FluxPipeline, AutoPipelineForText2Image, FluxTransformer2DModel, BitsAndBytesConfig
import torch
ckpt_id = "black-forest-labs/FLUX.1-dev"
pipeline = FluxPipeline.from_pretrained(
ckpt_id, text_encoder=None, text_encoder_2=None, torch_dtype=torch.float16
)
pipeline.load_lora_weights("derekl35/alphonse_mucha_qlora_flux", weight_name="pytorch_lora_weights.safetensors")
pipeline.fuse_lora()
pipeline.unload_lora_weights()
pipeline.transformer.save_pretrained("fused_transformer")
bnb_4bit_compute_dtype = torch.bfloat16
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=bnb_4bit_compute_dtype,
)
transformer = FluxTransformer2DModel.from_pretrained(
"fused_transformer",
quantization_config=nf4_config,
torch_dtype=bnb_4bit_compute_dtype,
)
pipeline = AutoPipelineForText2Image.from_pretrained(
ckpt_id, transformer=transformer, torch_dtype=bnb_4bit_compute_dtype
)
pipeline.enable_model_cpu_offload()
image = pipeline(
"a puppy in a pond, alphonse mucha style", num_inference_steps=28, guidance_scale=3.5, height=768, width=512, generator=torch.manual_seed(0)
).images[0]
image.save("alphonse_mucha_merged.png")
Running on Google Colab
While we showcased results on an RTX 4090, the identical code may be run on more accessible hardware just like the T4 GPU available in Google Colab free of charge.
On a T4, you may expect the fine-tuning process to take significantly longer around 4 hours for a similar variety of steps. This can be a trade-off for accessibility, however it makes custom fine-tuning possible without high-end hardware. Be mindful of usage limits if running on Colab, as a 4-hour training run might push them.
Conclusion
QLoRA, coupled with the diffusers library, significantly democratizes the power to customize state-of-the-art models like FLUX.1-dev. As demonstrated on an RTX 4090, efficient fine-tuning is well nearby, yielding high-quality stylistic adaptations. Moreover, for users with the most recent NVIDIA hardware, torchao enables even faster training through FP8 precision.
Share your creations on the Hub!
Sharing your fine-tuned LoRA adapters is a unbelievable option to contribute to the open-source community. It allows others to simply check out your styles, construct in your work, and helps create a vibrant ecosystem of creative AI tools.
In case you’ve trained a LoRA for FLUX.1-dev, we encourage you to share it. The simplest way is so as to add the –push_to_hub flag to the training script. Alternatively, if you’ve gotten already trained a model and wish to upload it, you should use the next snippet.
from huggingface_hub import create_repo, upload_folder
repo_id = "your-username/alphonse_mucha_qlora_flux"
create_repo(repo_id, exist_ok=True)
upload_folder(
repo_id=repo_id,
folder_path="alphonse_mucha_qlora_flux",
commit_message="Add Alphonse Mucha LoRA adapter"
)
Try our Mucha LoRA and the TorchAO FP8 LoRA. Yow will discover each, plus other adapters, in this collection.
We will not wait to see what you create!