
As corporations collect more unstructured data and increasingly use large language models (LLMs), they need faster and more scalable systems. Advanced tools for locating information, equivalent to retrieval-augmented generation (RAG), can take hours and even days to process massive amounts of information—sometimes at the size of terabytes or petabytes.
Meanwhile, online search applications like ad suggestion systems struggle to deliver fast results on CPUs. Hundreds of CPUs could be required to fulfill real-time speed requirements, increasing infrastructure costs.
This post explores the best way to solve these challenges using NVIDIA cuVS with the Meta Faiss library for efficient similarity search and clustering of dense vectors. cuVS uses GPU acceleration to dramatically speed up each the creation of search indexes and the actual search process. The result is way faster, lower-cost, and more efficient performance, all while maintaining seamless compatibility between CPUs and GPUs.
Specifically, the post covers:
- The advantages of integrating cuVS and Faiss
- How and where cuVS improves vector search performance
- Performance with GPU-accelerated inverted file index (IVF) and graph-based indexes
- Benchmarks and Python code examples demonstrating the best way to construct and search cuVS-powered indexes with Faiss
What are the advantages of integrating cuVS and Faiss?
Whether you’re querying hundreds of thousands of vectors per second, working with large multi-modal embeddings, or constructing massive indexes with GPUs, the cuVS integration with Faiss unlocks the following level of performance and adaptability.
cuVS allows you to:
- Construct indexes as much as 12x faster on GPU at 95% recall
- Achieve search latencies as much as 8x lower at 95% recall
- Easily move indexes between GPU and CPU environments to match your deployment needs
GPU acceleration in Faiss
Faiss is a preferred library for vector search across research and production environments. It supports standalone usage, integration with PyTorch, and embedding inside vector databases like RocksDB, OpenSearch, and Milvus.
Faiss pioneered GPU support in 2018 and has continued evolving since then. On the NeurIPS 2021 big-ann-benchmarks competition, NVIDIA claimed first place with GPU-accelerated algorithms. These methods were later contributed to Faiss and now live within the open source cuVS library.
Since Faiss v1.10.0, users can opt into cuVS for enhanced versions of inverted file index algorithms IVF-PQ, IVF-Flat, Flat (aka brute-force), and CAGRA (Cuda Anns GRAph-based)—a high-performance graph-based index built from the bottom up for GPUs.
Effortless CPU-GPU interoperability
Accelerating GPU indexes in Faiss with cuVS unlocks latest levels of CPU-GPU interoperability. With Faiss, you may construct indexes on the GPU after which deploy them to the CPU. This offers Faiss users the flexibility to speed up index constructing with GPUs while maintaining their CPU search architectures. It’s all achieved seamlessly within the Faiss library.
To supply an example, Hierarchical Navigable Small-World (HNSW) indexes are notoriously slow to construct on the CPU, especially at scale, taking several hours and even days. CAGRA indexes, then again, could be built as much as 12x faster. These CAGRA graphs could be formatted as HNSW indexes in Faiss after which deployed for search on the CPU.
Benchmarking Faiss with cuVS
Performance benchmarks were performed comparing on the next two datasets comparing Faiss with and without cuVS enabled:
- Deep100M: A 100M-vector subset of the Deep1B dataset (96 dimensions).
- OpenAI Text Embeddings: 5M vectors (1,536 dimensions) from the text-embedding-ada-002 model.
Tests were run on an NVIDIA H100 Tensor Core GPU and an Intel Xeon Platinum 8480CL CPU. Measurements were taken for:
- Index construct time
- Single-query latency (online search)
- Large-batch throughput (offline search)
Because the expansion of unstructured data is going on so quickly, it’s essential that index construct performance continues to extend. Nevertheless, measuring an index construct time alone is meaningless without considering the search performance and quality of the resulting model. For that reason, the team created its own methodology for benchmarking index builds. For more details, see the cuVS documentation.
Along with considering search performance and quality, it’s also essential to check models against one of the best performing parameter settings. This is finished using Pareto curves to make sure that each comparison is fair. Speedups in latency and throughput to check various indexes are done on the 95% recall level.
IVF: cuVS versus Faiss GPU classic
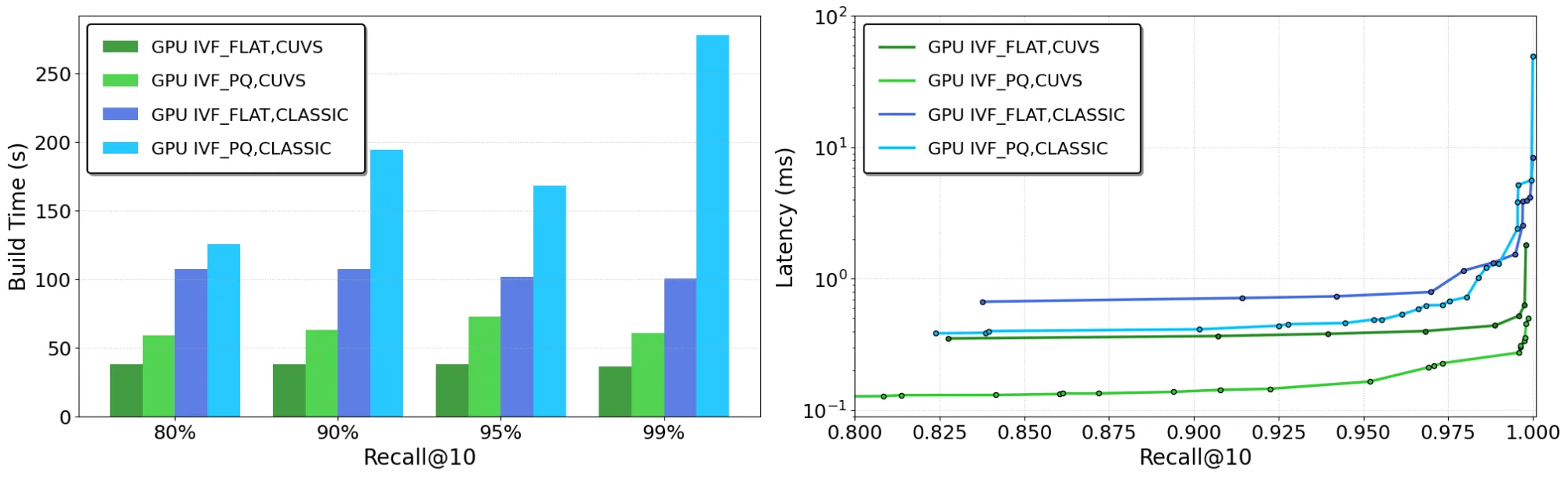
We first benchmarked the IVF indexes IVF-Flat and IVF-PQ to check Faiss classic GPU implementations against the brand new Faiss variants w/ cuVS support:
- Construct time: IVF-PQ and IVF-Flat were built as much as 4.7x faster using cuVS (Figure 1)
- Latency: Search latency was as much as 8x lower for IVF-PQ, and 90% lower for IVF-Flat (Figure 1)
- Throughput: cuVS improved large-batch search throughput as much as 3x for IVF-PQ across each datasets (Figure 2), while maintaining comparable performance for IVF-Flat. This makes it well-suited for high-volume and enormous offline search workloads.
Online latency
Figures 1a and 1b show online search latency and construct time across IVF index variants. cuVS consistently delivers faster index builds and significantly lower search latency across each datasets in comparison with classic Faiss.
Batch (offline) throughput
Figure 2 shows batch throughput across IVF index variants. cuVS improves batch processing performance, serving significantly more queries per second across each image and text embeddings.
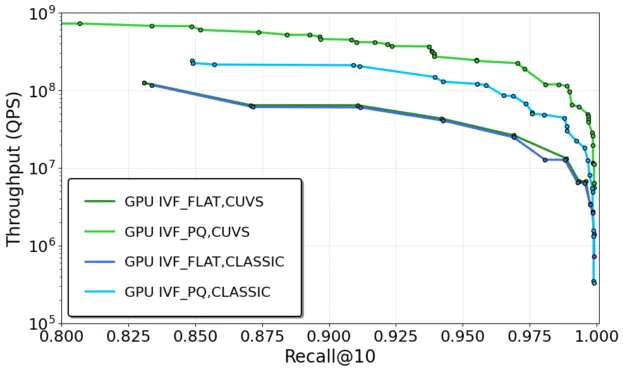
These improvements stem from higher GPU clustering (for instance, balanced k-means), expanded parameter support (for instance, more subquantizers for IVF-PQ), and code-level optimizations.
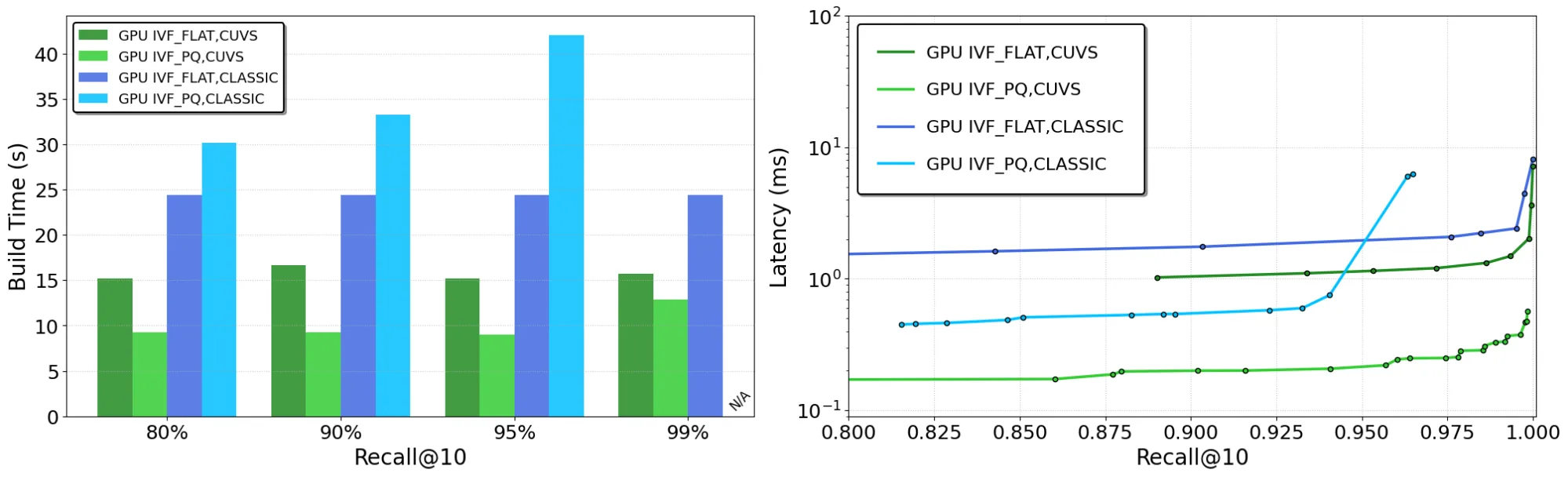
Graph-based indexes: cuVS CAGRA versus Faiss HNSW (CPU)
CAGRA is a GPU-optimized, fixed-degree flat graph index that gives major performance benefits over CPU-based HNSW, including:
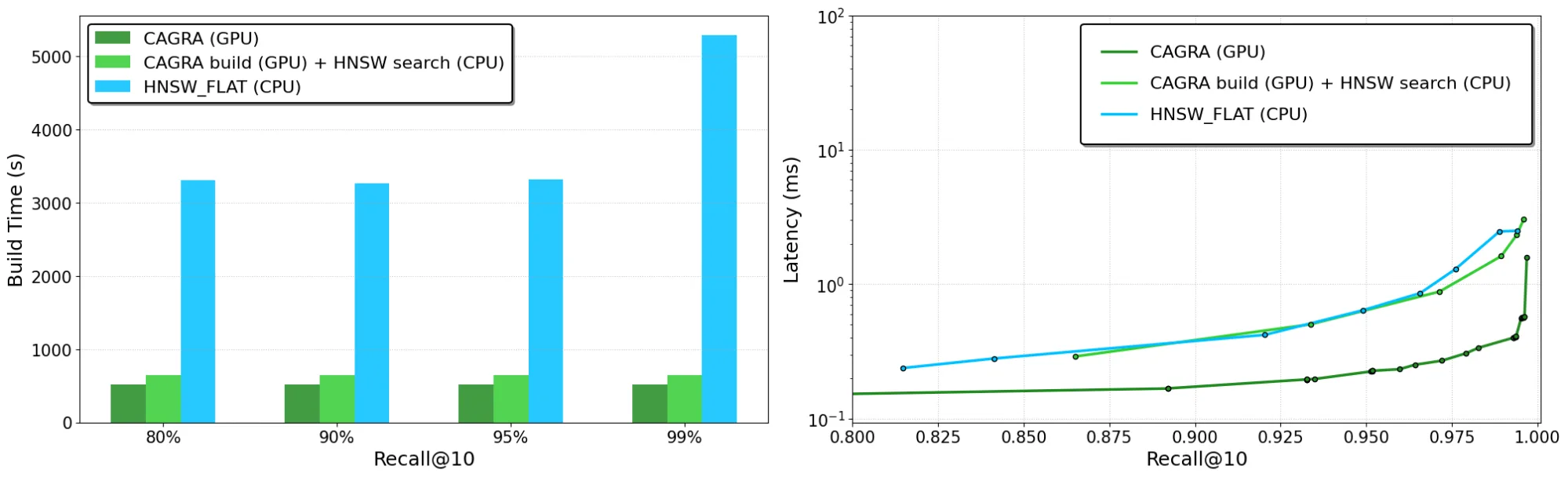
- Construct time: CAGRA builds as much as 12.3x faster (Figure 3)
- Latency: Online search is as much as 4.7x faster (Deep100M) (Figure 3)
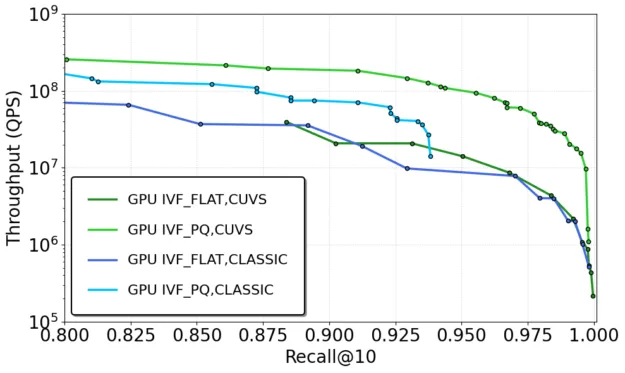
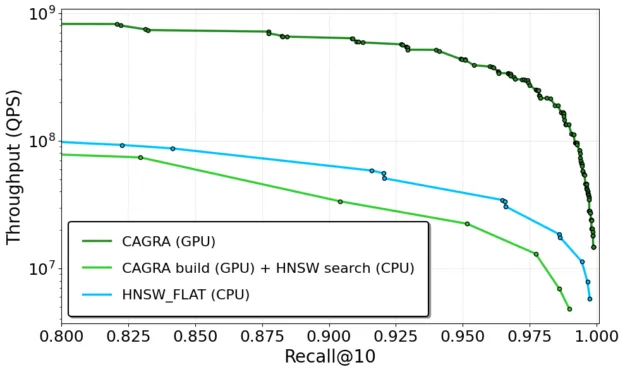
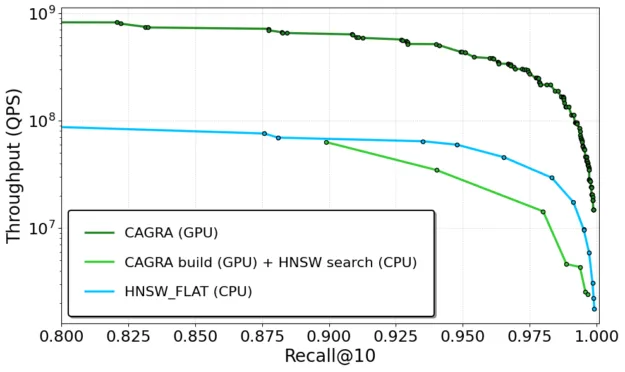
- Throughput: In offline search settings, CAGRA delivers as much as 18x higher throughput for image data and greater than 8x for text embeddings (Figure 4), making it ideal for workloads requiring high-volume inference at low latency.
cuVS enables a CAGRA graph to be converted on to an HNSW graph, which allows the graph to construct much faster on the GPU, while using the CPU for search with comparable speed and quality.
Online latency
Figures 3a and 3b show online latency and construct time for GPU CAGRA versus CPU HNSW. CAGRA dramatically accelerates index builds and lowers online query latency—as much as 4.7x faster search in comparison with HSNW on CPU for Deep100M.

Batch (offline) throughput
Figure 4 shows GPU CAGRA versus CPU HNSW batch throughput. CAGRA achieves high throughput in batch scenarios—serving hundreds of thousands of queries per second and outperforming CPU-based HNSW across each datasets.
start with cuVS in Faiss
This section briefly introduces the method for installing Faiss with cuVS support and provides transient code examples for creating and searching an index with Python.
Installation
You may construct Faiss with cuVS or with prebuilt Conda packages:
# Conda install (CUDA 12.4)
conda install -c rapidsai -c conda-forge -c nvidia pytorch::faiss-gpu-cuvs
'cuda-version>=12.0,<=12.9'
Alternatively, you may install the most recent nightly construct of the cuVS-enabled Faiss package using the next command:
conda install -c rapidsai -c rapidsai-nightly -c conda-forge -c nvidia
pytorch/label/nightly::faiss-gpu-cuvs 'cuda-version>=12.0,<=12.9'
Memory management
Use the next snippet to enable GPU memory pooling with RMM (really useful). This approach can improve performance.
import rmm
pool = rmm.mr.PoolMemoryResource(
rmm.mr.CudaMemoryResource(),
initial_pool_size=2**30
)
rmm.mr.set_current_device_resource(pool)
Construct an IVFPQ Index with cuVS
With the faiss-gpu-cuvs package, cuVS is routinely used for supported index types—requiring no code changes to learn from its performance improvements. An example of making an IVFPQ index using the cuVS backend is shown below:
import faiss
import numpy as np
np.random.seed(1234)
xb = np.random.random((1000000, 96)).astype('float32')
xq = np.random.random((10000, 96)).astype('float32')
xt = np.random.random((100000, 96)).astype('float32')
res = faiss.StandardGpuResources()
# Disable the default temporary memory allocation since an RMM pool resource has already been set.
res.noTempMemory()
# Case 1: Creating cuVS GPU index
config = faiss.GpuIndexIVFPQConfig()
config.interleavedLayout = True
index_gpu = faiss.GpuIndexIVFPQ(res, 96, 1024, 96, 6, faiss.METRIC_L2, config) # expanded parameter set with cuVS (bits per code = 6).
index_gpu.train(xt)
index_gpu.add(xb)
# Case 2: Cloning a CPU index to a cuVS GPU index
quantizer = faiss.IndexFlatL2(96)
index_cpu = faiss.IndexIVFPQ(quantizer,96, 1024, 96, 8, faiss.METRIC_L2)
index_cpu.train(xt)
co = faiss.GpuClonerOptions()
index_gpu = faiss.index_cpu_to_gpu(res, 0, index_cpu, co)
# The cuVS index now uses the trained quantizer because it's IVF centroids.
assert(index_gpu.is_trained)
index_gpu.add(xb)
k = 10
D, I = index_gpu.search(xq, k)
Construct a cuVS CAGRA index
The next example demonstrates the best way to construct and query a CAGRA index using Faiss with cuVS acceleration.
import faiss
import numpy as np
# Step 1: Create the CAGRA index config
config = faiss.GpuIndexCagraConfig()
config.graph_degree = 32
config.intermediate_graph_degree = 64
# Step 2: Initialize the CAGRA index
res = faiss.StandardGpuResources()
gpu_cagra_index = faiss.GpuIndexCagra(res, 96, faiss.METRIC_L2, config)
# Step 3: Add the 1M vectors to the index
n = 1000000
data = np.random.random((n, 96)).astype('float32')
gpu_cagra_index.train(data)
# Step 4: Search the index for top 10 neighbors for every query.
xq = np.random.random((10000, 96)).astype('float32')
D, I = gpu_cagra_index.search(xq,10)
Convert CAGRA to HNSW (for CPU search)
CAGRA indexes could be routinely converted to HNSW format through the brand new faiss.IndexHNSWCagra CPU class, enabling GPU-accelerated index builds followed by CPU-based search:
# Create the HNSW index object for vectors with 96 dimensions.
M = 16
cpu_hnsw_index = faiss.IndexHNSWCagra(96, M, faiss.METRIC_L2)
cpu_hnsw_index.base_level_only=False
# Initializes the HNSW base layer with the CAGRA graph.
gpu_cagra_index.copyTo(cpu_hnsw_index)
# Add latest vectors to the hierarchy.
newVecs = np.random.random((100000, 96)).astype('float32')
cpu_hnsw_index.add(newVecs)
For full code examples, see the Faiss cuVS notebook.
Get more out of your vectors
The mixing of NVIDIA cuVS into Faiss delivers substantial improvements in each speed and scalability for approximate nearest neighbors (ANN) search. Whether you’re working with inverted file (IVF) indexes or graph-based methods, Faiss integration of cuVS offers:
- Faster index builds: As much as 12x acceleration on GPU
- Lower search latency: As much as 4.7x improvement in real-time search
- Effortless CPU-GPU interoperability: Construct on GPU, search on CPU, and vice versa
The team has also introduced CAGRA, a high-performance, graph-based index purpose-built for GPUs, which outperforms classical CPU-based HNSW in each construct time and throughput. Higher still, CAGRA graphs could be converted to HNSW for efficient CPU-based inference—offering one of the best of each for hybrid deployments.
Whether you’re scaling search infrastructure to handle hundreds of thousands of queries per second or rapidly experimenting with latest embedding models, integrating Faiss with cuVS gives you the tools to maneuver faster, iterate smarter, and deploy confidently.
Able to start? Install the faiss-gpu-cuvs package and explore the example notebook.