
As generative AI advances, organizations need AI agents which can be accurate, reliable, and informed by data specific to their business. The NVIDIA AI-Q Research Assistant and Enterprise RAG Blueprints use retrieval-augmented generation (RAG) and NVIDIA Nemotron reasoning AI models to automate document comprehension, extract insights, and generate high-value evaluation and reports from vast datasets.
Deploying these tools requires secure and scalable AI infrastructure that also maximizes performance and price efficiency. On this blog post, we walk through deploying these blueprints on Amazon Elastic Kubernetes Service (EKS) on Amazon Web Services (AWS), while using services like Amazon OpenSearch Serverless vector database, Amazon Easy Storage Service (S3) for object storage, and Karpenter for dynamic GPU scaling.
Core components of the blueprints
The NVIDIA AI-Q Research Assistant blueprint builds directly upon the NVIDIA Enterprise RAG Blueprint. This RAG blueprint serves because the foundational component for your complete system. Each blueprints covered on this blog are built from a set of NVIDIA NIM microservices. These are optimized inference containers designed for high-throughput, low-latency performance of AI models on GPUs.
The components will be categorized by their role in the answer:
1. Foundational RAG components
These models form the core of the Enterprise RAG blueprint and function the essential foundation for the AI-Q assistant:
- Large language model (LLM) NVIDIA NIM: Llama-3.3-Nemotron-Super-49B-v1.5: That is the first reasoning model used for query decomposition, evaluation, and generating answers for the RAG pipeline.
- NeMo Retriever Models: This can be a suite of models, built with NVIDIA NIM, that gives advanced, multi-modal data ingestion and retrieval. It could extract text, tables, and even graphic elements out of your documents.
Note: The RAG blueprint offers several other optional models that aren’t deployed on this specific solution. Yow will discover more information on the RAG blueprint GitHub.
2. AI-Q Research Assistant Components
The AI-Q blueprint adds the next components on top of the RAG foundation to enable its advanced agentic workflow and automatic report generation:
- LLM NIM: Llama-3.3-70B-Instruct: That is an optional, larger model used specifically by AI-Q to generate its comprehensive, in-depth research reports.
- Web search integration: The AI-Q blueprint uses the Tavily API to complement its research with real-time web search results. This enables its reports to be based on essentially the most current information available.
AWS solution overview
The blueprints can be found on AI-on-EKS and supply a whole environment on AWS, automating the provisioning of all vital infrastructure and security components.
Architecture
The answer deploys all of the NVIDIA NIM microservices and other components as pods on a Kubernetes cluster. The precise GPU instances (e.g., G5, P4, P5 families) required for every workload are dynamically provisioned, optimizing for cost and performance.
NVIDIA AI-Q research assistant on AWS
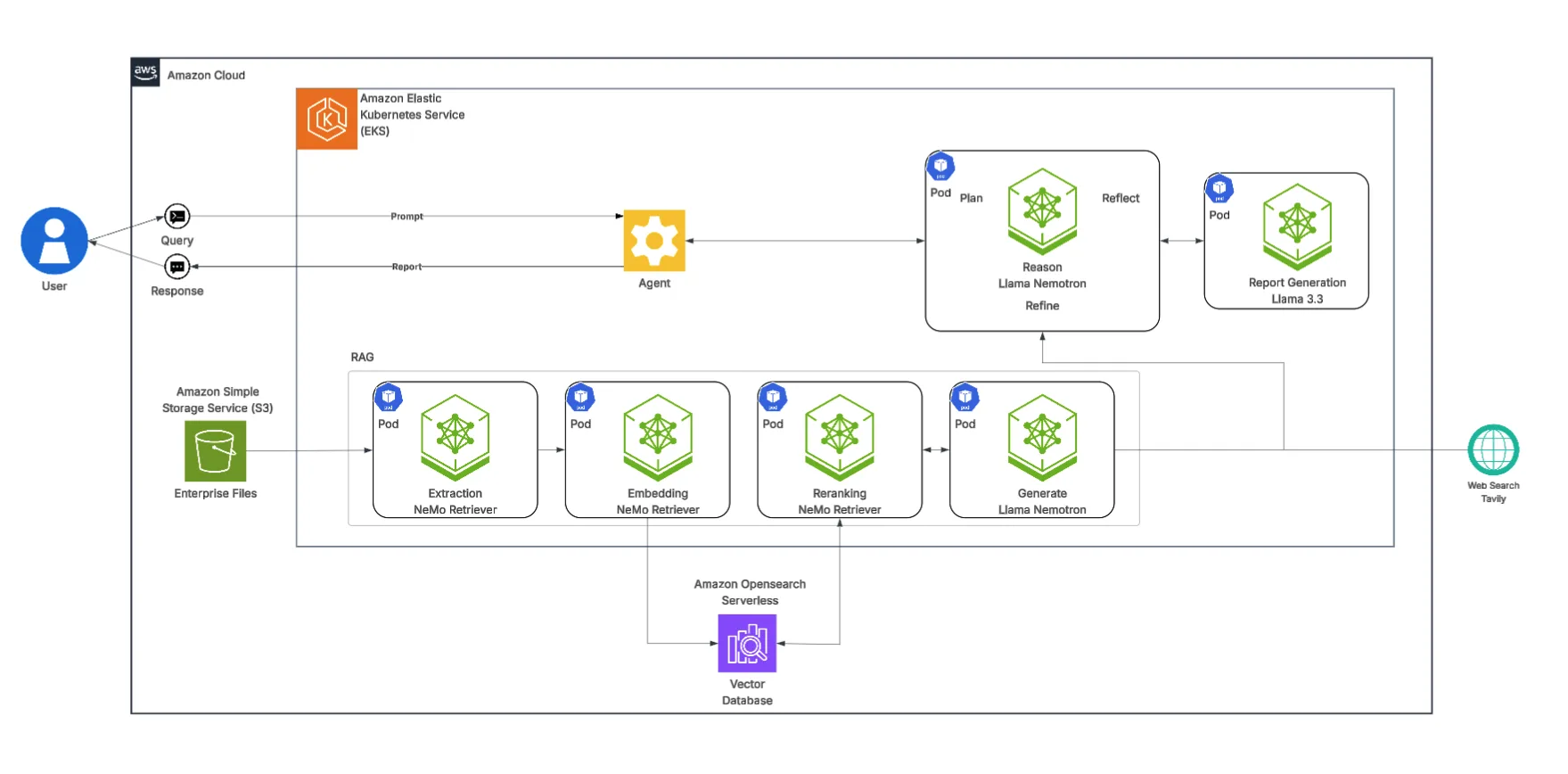
The AI-Q blueprint, shown within the primary diagram, adds an “Agent” layer on top of the RAG foundation. This agent orchestrates a more complex workflow:
- Plan: The Llama Nemotron reasoning agent breaks down a posh research prompt. It decides whether to question the RAG pipeline for internal knowledge or use the Tavily API for real-time web search.
- Refine: It gathers information from these sources and uses the Llama Nemotron model to “Refine” the info.
- Reflect: It passes all of the synthesized information to the “Report Generation” model (Llama 3.3 70B Instruct) to supply a structured, comprehensive report, complete with citations
NVIDIA Enterprise RAG Blueprint architecture
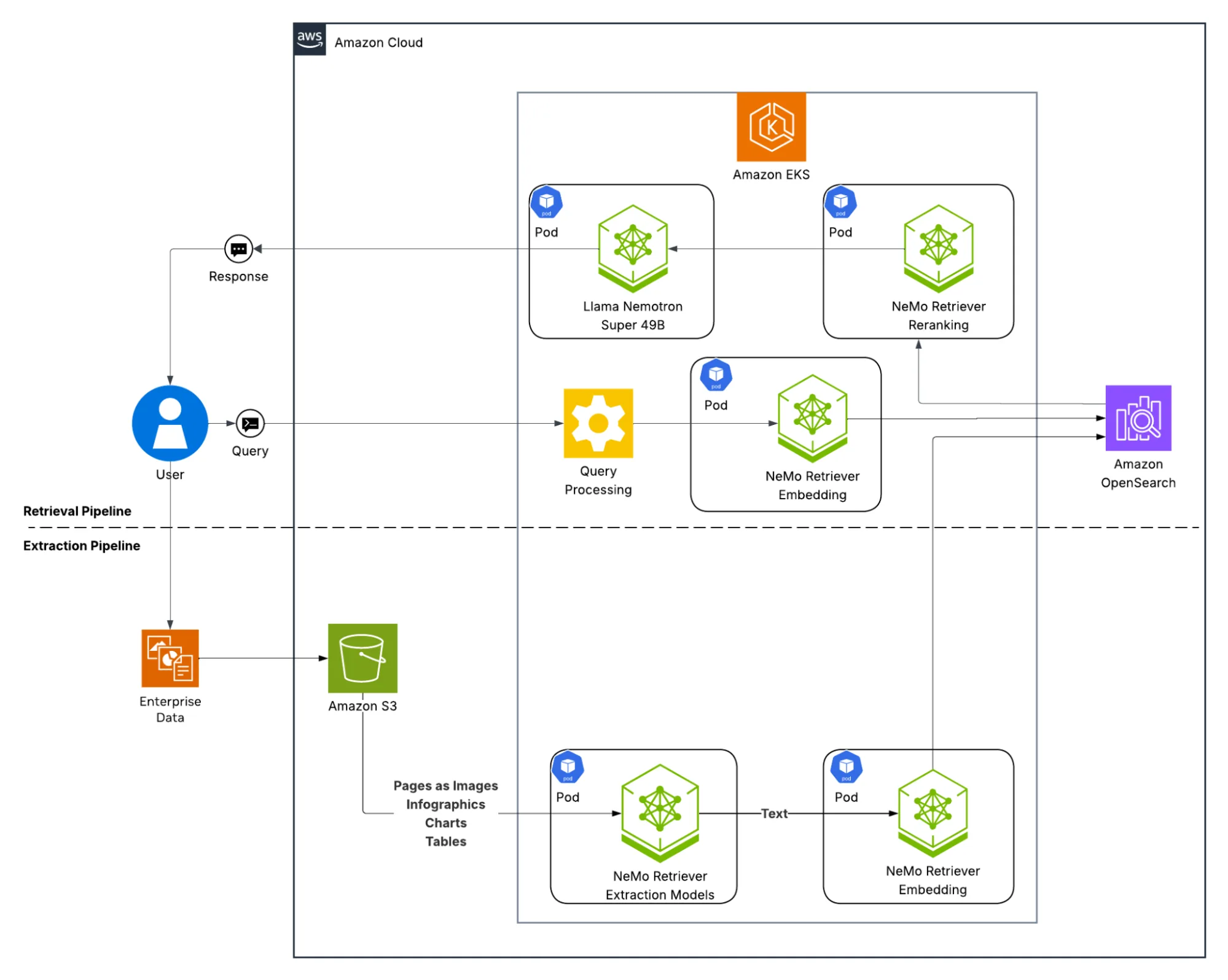
As shown in Figure 2, the answer consists of two parallel pipelines:
- Extraction pipeline: Enterprise files from Amazon S3 are processed by the NeMo Retriever extraction and embedding models. This extracts text, tables, and other data, converts them into vector embeddings, and stores them within the Amazon OpenSearch Serverless vector database.
- Retrieval pipeline: When a user sends a question, it’s processed, and the NeMo Retriever embedding and reranking models are used with OpenSearch for the context retrieval. This context is then passed to the NVIDIA Llama Nemotron Super 49B model, which generates the ultimate, context-aware answer
AWS components for deployment
This solution provisions a whole, secure environment on AWS using the next key services:
- Amazon EKS: This can be a managed Kubernetes service liable for running, scaling, and managing all of the containerized NVIDIA NIM microservices as pods.
- Amazon Easy Storage Service (S3): S3 acts as the first data lake, storing the enterprise files (like PDFs, reports, and other documents) that the RAG pipeline will ingest, process, and make searchable.
- Amazon OpenSearch Serverless: This fully managed, serverless vector database stores the documents once they’re processed into numerical representations (embeddings).
- Karpenter: A Kubernetes node autoscaler that runs in your cluster and monitors the resource requests of the AI pods and dynamically provisions the optimal GPU nodes (e.g., G5, P4, P5 families) to satisfy demand.
- EKS Pod Identity: This allows the pods running on EKS to securely access other AWS services, just like the Amazon OpenSearch Serverless collection, without managing static credentials.
Deployment steps
This solution uses a set of automated scripts to deploy your complete stack, from the AWS infrastructure to the blueprints.
Prerequisites
This deployment requires GPU instances (akin to G5, P4, or P5 families), which may incur significant costs. Please ensure you’ve got the vital service quotas for these instances in your AWS account and browse about cost considerations. Before you start, ensure you’ve got the next tools installed:
You’ll also need API keys from:
Authenticate AWS CLI
Before proceeding, ensure your environment (terminal of AWS CloudShell) is authenticated together with your AWS account. The deployment below uses your default AWS CLI credentials. You may configure this by running:
aws configureStep 1: Deploy infrastructure
Clone the repository and navigate to the infrastructure directory. Then, run the installation script:
# Clone the repository
git clone https://github.com/awslabs/ai-on-eks.git
cd ai-on-eks/infra/nvidia-deep-research
# Run the install script
./install.shThis script uses Terraform to provision your complete environment, including the VPC, EKS Cluster, OpenSearch Serverless collection, and Karpenter NodePools for GPU instances (G5, P4, P5, etc). This process typically takes 15-20 minutes.
Step 2: Arrange the environment
Once the infrastructure is prepared, run the setup script. It will configure kubectl to access your recent cluster and prompt you on your NVIDIA NGC and Tavily API keys.
./deploy.sh setupStep 3: Construct OpenSearch images
This step builds custom Docker images that integrate the RAG blueprint with the OpenSearch Serverless vector database.
./deploy.sh constructStep 4: Deploy applications
You now have two options for deployment.
Option 1: Deploy enterprise RAG only for document Q&A, knowledge base search, and custom RAG applications:
./deploy.sh ragIt will deploy the RAG server, the multi-modal ingestion pipeline, and the Llama Nemotron Super 49B v1.5 reasoning NIM.
Option 2: Deploy a full AI-Q research assistant to deploy every part from Option 1, plus the AI-Q components, including the Llama 3.3 70B Instruct NIM for report generation and the online search backend.
./deploy.sh allThis process will take 25-Half-hour because it involves Karpenter provisioning the GPU nodes (e.g., g5.48xlarge) to host the NIM microservices and the startup of the NIM microservices
Accessing the blueprints
The services are securely exposed via kubectl port-forward. The repository includes helper scripts to administer this.
- Navigate to the blueprints directory:
cd ../../blueprints/inference/nvidia-deep-research- To access the enterprise RAG UI:
./app.sh port start rag- You may now access the RAG frontend at http://localhost:3001 to upload documents and ask questions.
- To access the AI-Q research assistant UI (if deployed):
./app.sh port start aira- Access the AI-Q frontend at http://localhost:3000 to generate full research reports.
Accessing monitoring
The answer features a pre-built observability stack. It features Prometheus and Grafana for RAG metrics, Zipkin for distributed tracing of the RAG pipeline, Phoenix for tracing the complex agent workflows of the AI-Q assistant, and NVIDIA DCGM for comprehensive GPU monitoring.
You may access the dashboards using the identical port-forwarding script.
- Start the observability port-forward:
./app.sh port start observability - Access the monitoring UIs in your browser:
Cleanup
GPU instances can incur significant costs, so it’s critical to wash up resources if you end up finished.
1. Uninstall applications
To remove the RAG and AI-Q applications (which is able to cause Karpenter to terminate the expensive GPU nodes) but keep the EKS cluster and other infrastructure:
# From blueprints/inference/nvidia-deep-research
./app.sh cleanupThis script stops port-forwarding and uninstalls the Helm releases for RAG and AI-Q.
2. Clean up infrastructure
To permanently delete your complete EKS cluster, OpenSearch collection, VPC, and all other associated AWS resources:
# From infra/nvidia-deep-research
./cleanup.shIt will run terraform destroy to tear down all resources created by the install.sh script.
Conclusion
The NVIDIA AI-Q deep research assistant and enterprise RAG blueprints are customizable reference examples built on secure, scalable AWS AI foundations. They use key AWS services, like Amazon EKS for orchestration, Karpenter for cost-effective GPU autoscaling, Amazon OpenSearch Serverless for a managed, secure vector database, and Amazon S3 for object storage.
These integrated solutions enable you to deploy scalable research assistants and generative AI applications that may process and synthesize insights from vast amounts of enterprise data while maximizing performance and price efficiencies.
Deploy the NVIDIA Enterprise RAG or AI-Q Deep Research Blueprints on Amazon EKS today and begin transforming your enterprise data into secure, actionable intelligence.