
says that “”. That’s exactly how a variety of today’s AI frameworks feel. Tools like GitHub Copilot, Claude Desktop, OpenAI Operator, and Perplexity Comet are automating on a regular basis tasks that will’ve seemed unattainable to automate just five years ago. What’s much more remarkable is that with just just a few lines of code, we are able to construct our own sophisticated AI tools: ones that search through files, browse the net, click links, and even make purchases. It really does feel like magic.
Regardless that I genuinely imagine in data wizards, I don’t imagine in magic. I find it exciting (and infrequently helpful) to know how things are literally built and what’s happening under the hood. That’s why I’ve decided to share a series of posts on agentic AI design concepts that’ll show you how to understand how all these magical tools actually work.
To achieve a deep understanding, we’ll construct a multi-AI agent system from scratch. We’ll avoid using frameworks like CrewAI or smolagents and as a substitute work directly with the inspiration model API. Along the best way, we’ll explore the basic agentic design patterns: reflection, tool use, planning, and multi-agent setups. Then, we’ll mix all this data to construct a multi-AI agent system that may answer complex data-related questions.
As Richard Feynman put it, “.” So let’s start constructing! In this text, we’ll deal with the reflection design pattern. But first, let’s work out what exactly reflection is.
What reflection is
Let’s reflect on how we (humans) often work on tasks. Imagine I want to share the outcomes of a recent feature launch with my PM. I’ll likely put together a fast draft after which read it a couple of times from starting to finish, ensuring that every one parts are consistent, there’s enough information, and there aren’t any typos.
Or let’s take one other example: writing a SQL query. I’ll either write it step-by-step, checking the intermediate results along the best way, or (if it’s easy enough) I’ll draft it all of sudden, execute it, have a look at the result (checking for errors or whether the result matches my expectations), after which tweak the query based on that feedback. I’d rerun it, check the result, and iterate until it’s right.
So we rarely write long texts from top to bottom in a single go. We often circle back, review, and tweak as we go. These feedback loops are what help us improve the standard of our work.
LLMs use a special approach. For those who ask an LLM an issue, by default, it is going to generate a solution token by token, and the LLM won’t have the option to review its result and fix any issues. But in an agentic AI setup, we are able to create feedback loops for LLMs too, either by asking the LLM to review and improve its own answer or by sharing external feedback with it (like the outcomes of a SQL execution). And that’s the entire point of reflection. It sounds pretty straightforward, but it might yield significantly higher results.
There’s a considerable body of research showing the advantages of reflection:

- In “Reflexion: Language Agents with Verbal Reinforcement Learning” Shinn et al. (2023), the authors achieved a 91% pass@1 accuracy on the HumanEval coding benchmark, surpassing the previous state-of-the-art GPT-4, which scored just 80%. Additionally they found that Reflexion significantly outperforms all baseline approaches on the HotPotQA benchmark (a Wikipedia-based Q&A dataset that challenges agents to parse content and reason over multiple supporting documents).

Reflection is very impactful in agentic systems because it might be used to course-correct at many steps of the method:
- When a user asks an issue, the LLM can use reflection to guage whether the request is possible.
- When the LLM puts together an initial plan, it might use reflection to double-check whether the plan is sensible and can assist achieve the goal.
- After each execution step or tool call, the agent can evaluate whether it’s on the right track and whether it’s value adjusting the plan.
- When the plan is fully executed, the agent can reflect to see whether it has actually achieved the goal and solved the duty.
It’s clear that reflection can significantly improve accuracy. Nonetheless, there are trade-offs value discussing. Reflection might require multiple additional calls to the LLM and potentially other systems, which might result in increased latency and costs. So in business cases, it’s value considering whether the standard improvements justify the expenses and delays within the user flow.
Reflection in frameworks
Since there’s little question that reflection brings value to AI agents, it’s widely utilized in popular frameworks. Let’s have a look at some examples.
The concept of reflection was first proposed within the paper “ReAct: Synergizing Reasoning and Acting in Language Models” by Yao et al. (2022). ReAct is a framework that mixes interleaving stages of Reasoning (reflection through explicit thought traces) and Acting (task-relevant actions in an environment). On this framework, reasoning guides the alternative of actions, and actions produce latest observations that inform further reasoning. The reasoning stage itself is a mix of reflection and planning.
This framework became quite popular, so there are actually several off-the-shelf implementations, equivalent to:
- The DSPy framework by Databricks has a
ReActclass, - In LangGraph, you should use the
create_react_agentfunction, - Code agents within the smolagents library by HuggingFace are also based on the ReAct architecture.
Reflection from scratch
Now that we’ve learned the speculation and explored existing implementations, it’s time to get our hands dirty and construct something ourselves. Within the ReAct approach, agents use reflection at each step, combining planning with reflection. Nonetheless, to know the impact of reflection more clearly, we’ll have a look at it in isolation.
For instance, we’ll use text-to-SQL: we’ll give an LLM an issue and expect it to return a sound SQL query. We’ll be working with a flight delay dataset and the ClickHouse SQL dialect.
We’ll start by utilizing direct generation with none reflection as our baseline. Then, we’ll try using reflection by asking the model to critique and improve the SQL, or by providing it with additional feedback. After that, we’ll measure the standard of our answers to see whether reflection actually leads to higher results.
Direct generation
We’ll begin with essentially the most straightforward approach, direct generation, where we ask the LLM to generate SQL that answers a user query.
pip install anthropicWe’d like to specify the API Key for the Anthropic API.
import os
os.environ['ANTHROPIC_API_KEY'] = config['ANTHROPIC_API_KEY']The subsequent step is to initialise the client, and we’re all set.
import anthropic
client = anthropic.Anthropic()Now we are able to use this client to send messages to the LLM. Let’s put together a function to generate SQL based on a user query. I’ve specified the system prompt with basic instructions and detailed information concerning the data schema. I’ve also created a function to send the system prompt and user query to the LLM.
base_sql_system_prompt = '''
You might be a senior SQL developer and your task is to assist generate a SQL query based on user requirements.
You might be working with ClickHouse database. Specify the format (Tab Separated With Names) within the SQL query output to make sure that column names are included within the output.
Don't use count(*) in your queries because it's a nasty practice with columnar databases, prefer using count().
Be sure that the query is syntactically correct and optimized for performance, considering ClickHouse specific features (i.e. that ClickHouse is a columnar database and supports functions like ARRAY JOIN, SAMPLE, etc.).
Return only the SQL query with none additional explanations or comments.
You shall be working with flight_data table which has the next schema:
Column Name | Data Type | Null % | Example Value | Description
--- | --- | --- | --- | ---
12 months | Int64 | 0.0 | 2024 | Yr of flight
month | Int64 | 0.0 | 1 | Month of flight (1–12)
day_of_month | Int64 | 0.0 | 1 | Day of the month
day_of_week | Int64 | 0.0 | 1 | Day of week (1=Monday … 7=Sunday)
fl_date | datetime64[ns] | 0.0 | 2024-01-01 00:00:00 | Flight date (YYYY-MM-DD)
op_unique_carrier | object | 0.0 | 9E | Unique carrier code
op_carrier_fl_num | float64 | 0.0 | 4814.0 | Flight number for reporting airline
origin | object | 0.0 | JFK | Origin airport code
origin_city_name | object | 0.0 | "Latest York, NY" | Origin city name
origin_state_nm | object | 0.0 | Latest York | Origin state name
dest | object | 0.0 | DTW | Destination airport code
dest_city_name | object | 0.0 | "Detroit, MI" | Destination city name
dest_state_nm | object | 0.0 | Michigan | Destination state name
crs_dep_time | Int64 | 0.0 | 1252 | Scheduled departure time (local, hhmm)
dep_time | float64 | 1.31 | 1247.0 | Actual departure time (local, hhmm)
dep_delay | float64 | 1.31 | -5.0 | Departure delay in minutes (negative if early)
taxi_out | float64 | 1.35 | 31.0 | Taxi out time in minutes
wheels_off | float64 | 1.35 | 1318.0 | Wheels-off time (local, hhmm)
wheels_on | float64 | 1.38 | 1442.0 | Wheels-on time (local, hhmm)
taxi_in | float64 | 1.38 | 7.0 | Taxi in time in minutes
crs_arr_time | Int64 | 0.0 | 1508 | Scheduled arrival time (local, hhmm)
arr_time | float64 | 1.38 | 1449.0 | Actual arrival time (local, hhmm)
arr_delay | float64 | 1.61 | -19.0 | Arrival delay in minutes (negative if early)
cancelled | int64 | 0.0 | 0 | Cancelled flight indicator (0=No, 1=Yes)
cancellation_code | object | 98.64 | B | Reason for cancellation (if cancelled)
diverted | int64 | 0.0 | 0 | Diverted flight indicator (0=No, 1=Yes)
crs_elapsed_time | float64 | 0.0 | 136.0 | Scheduled elapsed time in minutes
actual_elapsed_time | float64 | 1.61 | 122.0 | Actual elapsed time in minutes
air_time | float64 | 1.61 | 84.0 | Flight time in minutes
distance | float64 | 0.0 | 509.0 | Distance between origin and destination (miles)
carrier_delay | int64 | 0.0 | 0 | Carrier-related delay in minutes
weather_delay | int64 | 0.0 | 0 | Weather-related delay in minutes
nas_delay | int64 | 0.0 | 0 | National Air System delay in minutes
security_delay | int64 | 0.0 | 0 | Security delay in minutes
late_aircraft_delay | int64 | 0.0 | 0 | Late aircraft delay in minutes
'''
def generate_direct_sql(rec):
# making an LLM call
message = client.messages.create(
model = "claude-3-5-haiku-latest",
# I selected smaller model in order that it's easier for us to see the impact
max_tokens = 8192,
system=base_sql_system_prompt,
messages = [
{'role': 'user', 'content': rec['question']}
]
)
sql = message.content[0].text
# cleansing the output
if sql.endswith('```'):
sql = sql[:-3]
if sql.startswith('```sql'):
sql = sql[6:]
return sqlThat’s it. Now let’s test our text-to-SQL solution. I’ve created a small evaluation set of 20 question-and-answer pairs that we are able to use to ascertain whether our system is working well. Here’s one example:
{
'query': 'What was the very best speed in mph?',
'answer': '''
select max(distance / (air_time / 60)) as max_speed
from flight_data
where air_time > 0
format TabSeparatedWithNames'''
}Let’s use our text-to-SQL function to generate SQL for all user queries within the test set.
# load evaluation set
with open('./data/flight_data_qa_pairs.json', 'r') as f:
qa_pairs = json.load(f)
qa_pairs_df = pd.DataFrame(qa_pairs)
tmp = []
# executing LLM for every query in our eval set
for rec in tqdm.tqdm(qa_pairs_df.to_dict('records')):
llm_sql = generate_direct_sql(rec)
tmp.append(
{
'id': rec['id'],
'llm_direct_sql': llm_sql
}
)
llm_direct_df = pd.DataFrame(tmp)
direct_result_df = qa_pairs_df.merge(llm_direct_df, on = 'id')Now we’ve our answers, and the following step is to measure the standard.
Measuring quality
Unfortunately, there’s no single correct answer in this case, so we are able to’t just compare the SQL generated by the LLM to a reference answer. We’d like to provide you with a solution to measure quality.
There are some elements of quality that we are able to check with objective criteria, but to ascertain whether the LLM returned the proper answer, we’ll need to make use of an LLM. So I’ll use a mix of approaches:
- First, we’ll use objective criteria to ascertain whether the proper format was laid out in the SQL (we instructed the LLM to make use of
TabSeparatedWithNames). - Second, we are able to execute the generated query and see whether ClickHouse returns an execution error.
- Finally, we are able to create an LLM judge that compares the output from the generated query to our reference answer and checks whether or not they differ.
Let’s start by executing the SQL. It’s value noting that our get_clickhouse_data function doesn’t throw an exception. As a substitute, it returns text explaining the error, which might be handled by the LLM later.
CH_HOST = 'http://localhost:8123' # default address
import requests
import pandas as pd
import tqdm
# function to execute SQL query
def get_clickhouse_data(query, host = CH_HOST, connection_timeout = 1500):
r = requests.post(host, params = {'query': query},
timeout = connection_timeout)
if r.status_code == 200:
return r.text
else:
return 'Database returned the next error:n' + r.text
# getting the outcomes of SQL execution
direct_result_df['llm_direct_output'] = direct_result_df['llm_direct_sql'].apply(get_clickhouse_data)
direct_result_df['answer_output'] = direct_result_df['answer'].apply(get_clickhouse_data)The subsequent step is to create an LLM judge. For this, I’m using a series‑of‑thought approach that prompts the LLM to offer its reasoning before giving the ultimate answer. This offers the model time to think through the issue, which improves response quality.
llm_judge_system_prompt = '''
You might be a senior analyst and your task is to match two SQL query results and determine in the event that they are equivalent.
Focus only on the info returned by the queries, ignoring any formatting differences.
Keep in mind the initial user query and data needed to reply it. For instance, if user asked for the common distance, and each queries return the identical average value but in one in all them there's also a count of records, it's best to consider them equivalent, since each provide the identical requested information.
Answer with a JSON of the next structure:
{
'reasoning': '',
'equivalence':
}
Be sure that ONLY JSON is within the output.
You shall be working with flight_data table which has the next schema:
Column Name | Data Type | Null % | Example Value | Description
--- | --- | --- | --- | ---
12 months | Int64 | 0.0 | 2024 | Yr of flight
month | Int64 | 0.0 | 1 | Month of flight (1–12)
day_of_month | Int64 | 0.0 | 1 | Day of the month
day_of_week | Int64 | 0.0 | 1 | Day of week (1=Monday … 7=Sunday)
fl_date | datetime64[ns] | 0.0 | 2024-01-01 00:00:00 | Flight date (YYYY-MM-DD)
op_unique_carrier | object | 0.0 | 9E | Unique carrier code
op_carrier_fl_num | float64 | 0.0 | 4814.0 | Flight number for reporting airline
origin | object | 0.0 | JFK | Origin airport code
origin_city_name | object | 0.0 | "Latest York, NY" | Origin city name
origin_state_nm | object | 0.0 | Latest York | Origin state name
dest | object | 0.0 | DTW | Destination airport code
dest_city_name | object | 0.0 | "Detroit, MI" | Destination city name
dest_state_nm | object | 0.0 | Michigan | Destination state name
crs_dep_time | Int64 | 0.0 | 1252 | Scheduled departure time (local, hhmm)
dep_time | float64 | 1.31 | 1247.0 | Actual departure time (local, hhmm)
dep_delay | float64 | 1.31 | -5.0 | Departure delay in minutes (negative if early)
taxi_out | float64 | 1.35 | 31.0 | Taxi out time in minutes
wheels_off | float64 | 1.35 | 1318.0 | Wheels-off time (local, hhmm)
wheels_on | float64 | 1.38 | 1442.0 | Wheels-on time (local, hhmm)
taxi_in | float64 | 1.38 | 7.0 | Taxi in time in minutes
crs_arr_time | Int64 | 0.0 | 1508 | Scheduled arrival time (local, hhmm)
arr_time | float64 | 1.38 | 1449.0 | Actual arrival time (local, hhmm)
arr_delay | float64 | 1.61 | -19.0 | Arrival delay in minutes (negative if early)
cancelled | int64 | 0.0 | 0 | Cancelled flight indicator (0=No, 1=Yes)
cancellation_code | object | 98.64 | B | Reason for cancellation (if cancelled)
diverted | int64 | 0.0 | 0 | Diverted flight indicator (0=No, 1=Yes)
crs_elapsed_time | float64 | 0.0 | 136.0 | Scheduled elapsed time in minutes
actual_elapsed_time | float64 | 1.61 | 122.0 | Actual elapsed time in minutes
air_time | float64 | 1.61 | 84.0 | Flight time in minutes
distance | float64 | 0.0 | 509.0 | Distance between origin and destination (miles)
carrier_delay | int64 | 0.0 | 0 | Carrier-related delay in minutes
weather_delay | int64 | 0.0 | 0 | Weather-related delay in minutes
nas_delay | int64 | 0.0 | 0 | National Air System delay in minutes
security_delay | int64 | 0.0 | 0 | Security delay in minutes
late_aircraft_delay | int64 | 0.0 | 0 | Late aircraft delay in minutes
'''
llm_judge_user_prompt_template = '''
Here is the initial user query:
{user_query}
Here is the SQL query generated by the primary analyst:
SQL:
{sql1}
Database output:
{result1}
Here is the SQL query generated by the second analyst:
SQL:
{sql2}
Database output:
{result2}
'''
def llm_judge(rec, field_to_check):
# construct the user prompt
user_prompt = llm_judge_user_prompt_template.format(
user_query = rec['question'],
sql1 = rec['answer'],
result1 = rec['answer_output'],
sql2 = rec[field_to_check + '_sql'],
result2 = rec[field_to_check + '_output']
)
# make an LLM call
message = client.messages.create(
model = "claude-sonnet-4-5",
max_tokens = 8192,
temperature = 0.1,
system = llm_judge_system_prompt,
messages=[
{'role': 'user', 'content': user_prompt}
]
)
data = message.content[0].text
# Strip markdown code blocks
data = data.strip()
if data.startswith('```json'):
data = data[7:]
elif data.startswith('```'):
data = data[3:]
if data.endswith('```'):
data = data[:-3]
data = data.strip()
return json.loads(data) Now, let’s run the LLM judge to get the outcomes.
tmp = []
for rec in tqdm.tqdm(direct_result_df.to_dict('records')):
try:
judgment = llm_judge(rec, 'llm_direct')
except Exception as e:
print(f"Error processing record {rec['id']}: {e}")
proceed
tmp.append(
{
'id': rec['id'],
'llm_judge_reasoning': judgment['reasoning'],
'llm_judge_equivalence': judgment['equivalence']
}
)
judge_df = pd.DataFrame(tmp)
direct_result_df = direct_result_df.merge(judge_df, on = 'id')Let’s have a look at one example to see how the LLM judge works.
# user query
In 2024, what percentage of time all airplanes spent within the air?
# correct answer
select (sum(air_time) / sum(actual_elapsed_time)) * 100 as percentage_in_air
where 12 months = 2024
from flight_data
format TabSeparatedWithNames
percentage_in_air
81.43582596894757
# generated by LLM answer
SELECT
round(sum(air_time) / (sum(air_time) + sum(taxi_out) + sum(taxi_in)) * 100, 2) as air_time_percentage
FROM flight_data
WHERE 12 months = 2024
FORMAT TabSeparatedWithNames
air_time_percentage
81.39
# LLM judge response
{
'reasoning': 'Each queries calculate the share of time airplanes
spent within the air, but use different denominators. The primary query
uses actual_elapsed_time (which incorporates air_time + taxi_out + taxi_in
+ any ground delays), while the second uses only (air_time + taxi_out
+ taxi_in). The second query is approach is more accurate for answering
"time airplanes spent within the air" because it excludes ground delays.
Nonetheless, the outcomes are very close (81.44% vs 81.39%), suggesting minimal
impact. These are materially different approaches that occur to yield
similar results',
'equivalence': FALSE
}The reasoning is sensible, so we are able to trust our judge. Now, let’s check all LLM-generated queries.
def get_llm_accuracy(sql, output, equivalence):
problems = []
if 'format tabseparatedwithnames' not in sql.lower():
problems.append('No format laid out in SQL')
if 'Database returned the next error' in output:
problems.append('SQL execution error')
if not equivalence and ('SQL execution error' not in problems):
problems.append('Flawed answer provided')
if len(problems) == 0:
return 'No problems detected'
else:
return ' + '.join(problems)
direct_result_df['llm_direct_sql_quality_heuristics'] = direct_result_df.apply(
lambda row: get_llm_accuracy(row['llm_direct_sql'], row['llm_direct_output'], row['llm_judge_equivalence']), axis=1)The LLM returned the proper answer in 70% of cases, which is just not bad. But there’s definitely room for improvement, because it often either provides the mistaken answer or fails to specify the format accurately (sometimes causing SQL execution errors).

Adding a mirrored image step
To enhance the standard of our solution, let’s try adding a mirrored image step where we ask the model to review and refine its answer.
For a mirrored image call, I’ll keep the identical system prompt because it incorporates all of the needed details about SQL and the info schema. But I’ll tweak the user message to share the initial user query and the generated SQL, asking the LLM to critique and improve it.
simple_reflection_user_prompt_template = '''
Your task is to evaluate the SQL query generated by one other analyst and propose improvements if needed.
Check whether the query is syntactically correct and optimized for performance.
Listen to nuances in data (especially time stamps types, whether to make use of total elapsed time or time within the air, etc).
Be sure that the query answers the initial user query accurately.
Because the result return the next JSON:
{{
'reasoning': '',
'refined_sql': ''
}}
Be sure that ONLY JSON is within the output and nothing else. Be sure that the output JSON is valid.
Here is the initial user query:
{user_query}
Here is the SQL query generated by one other analyst:
{sql}
'''
def simple_reflection(rec) -> str:
# constructing a user prompt
user_prompt = simple_reflection_user_prompt_template.format(
user_query=rec['question'],
sql=rec['llm_direct_sql']
)
# making an LLM call
message = client.messages.create(
model="claude-3-5-haiku-latest",
max_tokens = 8192,
system=base_sql_system_prompt,
messages=[
{'role': 'user', 'content': user_prompt}
]
)
data = message.content[0].text
# strip markdown code blocks
data = data.strip()
if data.startswith('```json'):
data = data[7:]
elif data.startswith('```'):
data = data[3:]
if data.endswith('```'):
data = data[:-3]
data = data.strip()
return json.loads(data.replace('n', ' ')) Let’s refine the queries with reflection and measure the accuracy. We don’t see much improvement in the ultimate quality. We’re still at 70% correct answers.

Let’s have a look at specific examples to know what happened. First, there are a few cases where the LLM managed to repair the issue, either by correcting the format or by adding missing logic to handle zero values.

Nonetheless, there are also cases where the LLM overcomplicated the reply. The initial SQL was correct (matching the golden set answer), but then the LLM decided to ‘improve’ it. A few of these improvements are reasonable (e.g., accounting for nulls or excluding cancelled flights). Still, for some reason, it decided to make use of ClickHouse sampling, although we don’t have much data and our table doesn’t support sampling. In consequence, the refined query returned an execution error: Database returned the next error: Code: 141. DB::Exception: Storage default.flight_data doesn't support sampling. (SAMPLING_NOT_SUPPORTED).

Reflection with external feedback
Reflection didn’t improve accuracy much. This is probably going because we didn’t provide any additional information that will help the model generate a greater result. Let’s try sharing external feedback with the model:
The results of our check on whether the format is specified accurately
The output from the database (either data or an error message)
Let’s put together a prompt for this and generate a new edition of the SQL.
feedback_reflection_user_prompt_template = '''
Your task is to evaluate the SQL query generated by one other analyst and propose improvements if needed.
Check whether the query is syntactically correct and optimized for performance.
Listen to nuances in data (especially time stamps types, whether to make use of total elapsed time or time within the air, etc).
Be sure that the query answers the initial user query accurately.
Because the result return the next JSON:
{{
'reasoning': '',
'refined_sql': ''
}}
Be sure that ONLY JSON is within the output and nothing else. Be sure that the output JSON is valid.
Here is the initial user query:
{user_query}
Here is the SQL query generated by one other analyst:
{sql}
Here is the database output of this question:
{output}
We run an automatic check on the SQL query to ascertain whether it has fomatting issues. Here's the output:
{formatting}
'''
def feedback_reflection(rec) -> str:
# define message for formatting
if 'No format laid out in SQL' in rec['llm_direct_sql_quality_heuristics']:
formatting = 'SQL missing formatting. Specify "format TabSeparatedWithNames" to make sure that column names are also returned'
else:
formatting = 'Formatting is correct'
# constructing a user prompt
user_prompt = feedback_reflection_user_prompt_template.format(
user_query = rec['question'],
sql = rec['llm_direct_sql'],
output = rec['llm_direct_output'],
formatting = formatting
)
# making an LLM call
message = client.messages.create(
model = "claude-3-5-haiku-latest",
max_tokens = 8192,
system = base_sql_system_prompt,
messages = [
{'role': 'user', 'content': user_prompt}
]
)
data = message.content[0].text
# strip markdown code blocks
data = data.strip()
if data.startswith('```json'):
data = data[7:]
elif data.startswith('```'):
data = data[3:]
if data.endswith('```'):
data = data[:-3]
data = data.strip()
return json.loads(data.replace('n', ' ')) After running our accuracy measurements, we are able to see that accuracy has improved significantly: 17 correct answers (85% accuracy) in comparison with 14 (70% accuracy).
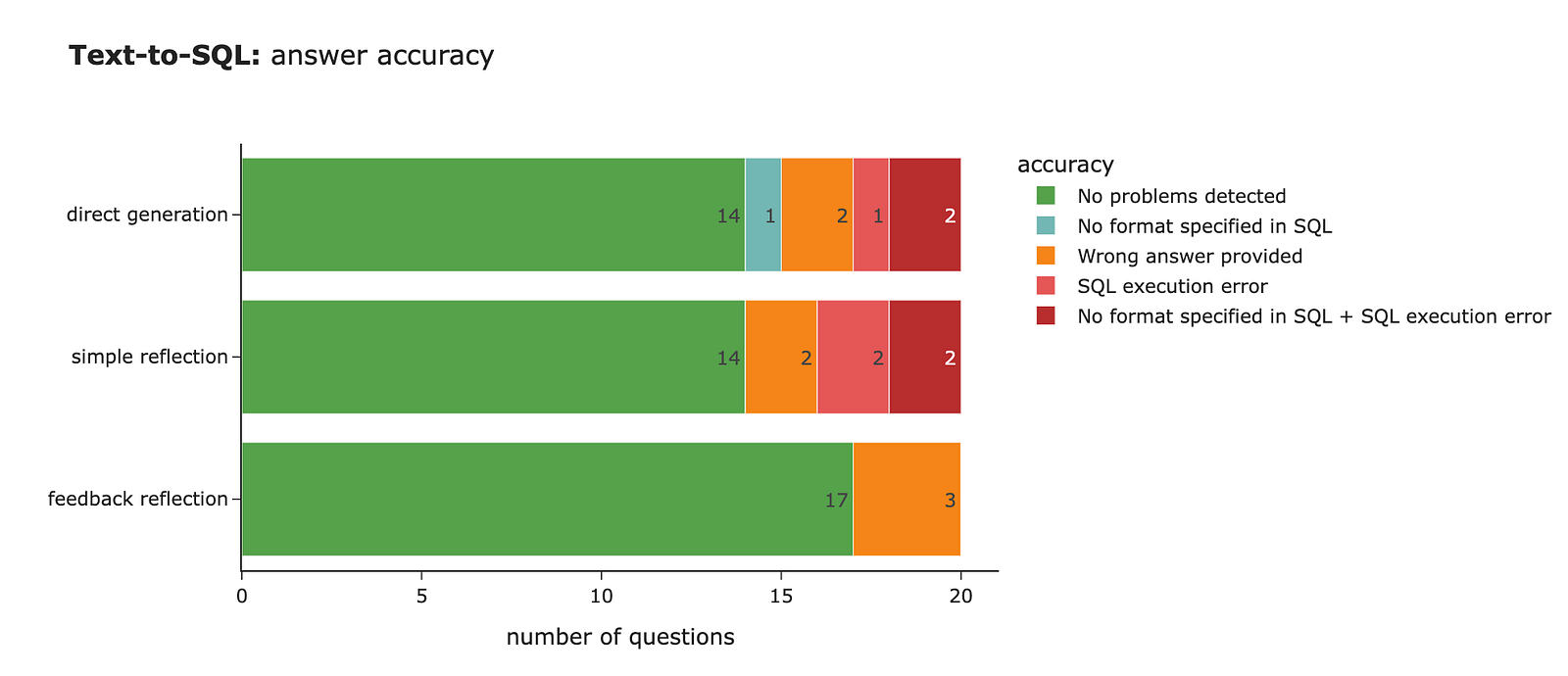
If we check the cases where the LLM fixed the problems, we are able to see that it was in a position to correct the format, address SQL execution errors, and even revise the business logic (e.g., using air time for calculating speed).

Let’s also do some error evaluation to look at the cases where the LLM made mistakes. Within the table below, we are able to see that the LLM struggled with defining certain timestamps, incorrectly calculating total time, or using total time as a substitute of air time for speed calculations. Nonetheless, a few of the discrepancies are a bit tricky:
- Within the last query, the time period wasn’t explicitly defined, so it’s reasonable for the LLM to make use of 2010–2023. I wouldn’t consider this an error, and I’d adjust the evaluation as a substitute.
- One other example is the way to define airline speed:
avg(distance/time)orsum(distance)/sum(time). Each options are valid since nothing was laid out in the user query or system prompt (assuming we don’t have a predefined calculation method).

Overall, I feel we achieved a reasonably good result. Our final 85% accuracy represents a big 15% point improvement. You can potentially transcend one iteration and run 2–3 rounds of reflection, however it’s value assessing while you hit diminishing returns in your specific case, since each iteration goes with increased cost and latency.
Summary
It’s time to wrap things up. In this text, we began our journey into understanding how the magic of agentic AI systems works. To figure it out, we’ll implement a multi-agent text-to-data tool using only API calls to foundation models. Along the best way, we’ll walk through the important thing design patterns step-by-step: starting today with reflection, and moving on to tool use, planning, and multi-agent coordination.
In this text, we began with essentially the most fundamental pattern — reflection. Reflection is on the core of any agentic flow, for the reason that LLM must reflect on its progress toward achieving the top goal.
Reflection is a comparatively straightforward pattern. We simply ask the identical or a special model to analyse the result and try to improve it. As we learned in practice, sharing external feedback with the model (like results from static checks or database output) significantly improves accuracy. Multiple research studies and our own experience with the text-to-SQL agent prove the advantages of reflection. Nonetheless, these accuracy gains come at a price: more tokens spent and better latency on account of multiple API calls.
Reference
This text is inspired by the “Agentic AI” course by Andrew Ng from DeepLearning.AI.