
Introduction
the the state-of-the-art architecture for NLP and never only. Modern models like ChatGPT, Llama, and Gemma are based on this architecture introduced in 2017 within the Attention Is All You Need paper from Vaswani et al.
Within the previous article, we saw how one can use spaCy to perform several tasks, and you may have noticed that we never had to coach anything, but we leveraged spaCy capabilities, that are mainly rule-based approaches.
SpaCy also offers to insert within the NLP pipeline trainable components or to make use of models off the shelf from the 🤗 HuggingFace Hub, which is an internet platform that gives open-source models for AI developers to make use of.
So let’s learn how one can use SpaCy with Hugging Face’s models!
Why Transformers?
Before transformers the SOTA architecture to create vector representations of words was word vectors techniques. A word vector is a dense representation of a word, which we are able to use to perform some mathematical calculation on it.
For instance, we are able to observe that two words which have an analogous meaning even have similar vectors. Essentially the most famous techniques of this sort are GloVe and FastText.
These methods, though, have introduced an enormous problem, a word is represented at all times by the identical vector. But a word doesn’t at all times have the identical meaning.
For instance:
- “She went to the bank to withdraw some money.”
- “He sat by the bank of the river, watching the water flow.”
In these two sentences, the word bank assumes two different meanings, so it doesn’t make sense to at all times represent the word with the identical vector.
With transformer-based architecture, we’re able today to create models that consider all the context to generate the vectorial representation of a word.
The fundamental innovation introduced by this network is the multi-head attention block. If you happen to should not conversant in it, I recently wrote an article about this: https://towardsdatascience.com/a-simple-implementation-of-the-attention-mechanism-from-scratch/
The transformer is made up of two parts. The left part, which is the encoder which creates the vectorial representation of texts, and the appropriate part, the decoder, is used to generate latest text. For instance, GPT is predicated on the appropriate part, since it generates text as a chatbot.
In this text, we’re taken with the encoder part, which is capable of capture the semantics of the text we give as input.
BERT and RoBERTa
This won’t be a course about these models, but let’s recap some fundamental topics.
While ChatGPT is built on the decoder side of the transformer architecture, BERT and RoBERTa are based on the encoder side.
BERT was introduced by Google in 2018 and you may read more about it here: https://arxiv.org/abs/1810.04805
BERT is a stack of encoder layers. There are two sizes of this model. BERT base incorporates 12 encoders while BERT large incorporates 24 encoders

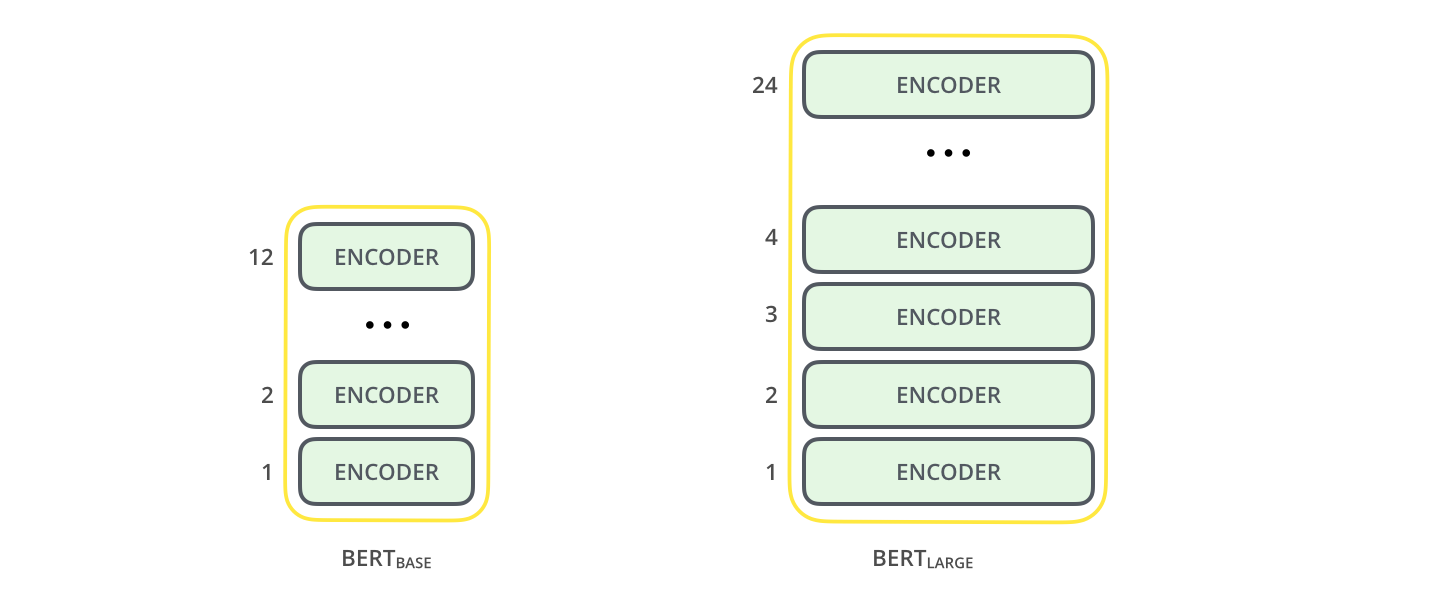{kind=link}
BERT base generates a vector of size 768, while the massive one a vector of size 1024. Each take an input of size 512 tokens.
The tokenizer utilized by the BERT model is named WordPiece.
BERT is trained on two objectives:
- Masked Language Modeling (MLM): Predicts missing (masked) tokens inside a sentence.
- Next Sentence Prediction (NSP): Determines whether a given second sentence logically follows the primary one.
RoBERTa model builds on top of BERT with some key differences: https://arxiv.org/abs/1907.11692.
RoBERTa uses a dynamic masking, so masked tokens change at every iteration in the course of the training, and doesn’t use the NSP as training objectives.
Use RoBERTa with SpaCy
The TextCategorizer is a spaCy component that predicts a number of labels for a whole document. It will probably work in two modalities:
- exclusive_classes = true: one label per text (e.g., or )
- exclusive_classes = false: multiple labels per text (e.g., , , )
spaCy can mix this with different embeddings:
- Classic word vectors (
tok2vec) - Transformer models like RoBERTa, which we use here
In this manner we are able to lavarage the RoBERTa understanding of the english language, and integrate it within the spacy pipeline to make it production ready.
If you may have a dataset, you may further train the RoBERTa model using spaCy to fine-tune it on the particular downstream task you’re trying to unravel.
Dataset preparation
In this text I’m going to make use of the TREC dataset, which incorporates short questions. Each query is labelled with the sort of answer it expects, akin to:
| Label | Meaning |
|---|---|
| ABBR | Abbreviation |
| DESC | Description / Definition |
| ENTY | Entity (thing, object) |
| HUM | Human (person, group) |
| LOC | Location (place) |
| NUM | Numeric (count, date, etc) |
That is an example, where we expect as answer a human name:
Q (text): “Who wrote the Iliad?”
A (label): “HUM”
As usual we start by installing the libraries.
!pip install datasets==3.6.0
!pip install -U spacy[transformers]Now we want to load prepare the dataset.
With spacy.blank("en") we are able to create a blank spaCy pipeline for English. It doesn’t include any components (just like the tagger or the parser),. It’s lightweight and excellent for converting raw text to Doc objects without loading a full language model like we do with en_core_web_sm.
DocBin is a special spaCy class that efficiently stores many Doc objects in binary format. That is how spaCy expects training data to be saved.
Once converted and saved as .spacy files, these may be passed directly into spacy train, which is far faster than using plain JSON or text files.
So now this script to organize the train and dev dataset needs to be pretty straightforward.
from datasets import load_dataset
import spacy
from spacy.tokens import DocBin
# Load TREC dataset
dataset = load_dataset("trec")
# Get label names (e.g., ["DESC", "ENTY", "ABBR", ...])
label_names = dataset["train"].features["coarse_label"].names
# Create a blank English pipeline (no components yet)
nlp = spacy.blank("en")
# Convert Hugging Face examples into spaCy Docs and save as .spacy file
def convert_to_spacy(split, filename):
doc_bin = DocBin()
for instance in split:
text = example["text"]
label = label_names[example["coarse_label"]]
cats = {name: 0.0 for name in label_names}
cats[label] = 1.0
doc = nlp.make_doc(text)
doc.cats = cats
doc_bin.add(doc)
doc_bin.to_disk(filename)
convert_to_spacy(dataset["train"], "train.spacy")
convert_to_spacy(dataset["test"], "dev.spacy")
We’re going to firther train RoBERTa on this dataset using a sapCy CLI command. The command expects a file where we describe the sort of training, the model we’re using, the variety of epohchs etc.
Here is the config file I used for my training pourposes.
[paths]
train = ./train.spacy
dev = ./dev.spacy
vectors = null
init_tok2vec = null
[system]
gpu_allocator = "pytorch"
seed = 42
[nlp]
lang = "en"
pipeline = ["transformer", "textcat"]
batch_size = 32
[components]
[components.transformer]
factory = "transformer"
[components.transformer.model]
@architectures = "spacy-transformers.TransformerModel.v3"
name = "roberta-base"
tokenizer_config = {"use_fast": true}
transformer_config = {}
mixed_precision = false
grad_scaler_config = {}
[components.transformer.model.get_spans]
@span_getters = "spacy-transformers.strided_spans.v1"
window = 128
stride = 96
[components.textcat]
factory = "textcat"
scorer = {"@scorers": "spacy.textcat_scorer.v2"}
threshold = 0.5
[components.textcat.model]
@architectures = "spacy.TextCatEnsemble.v2"
nO = null
[components.textcat.model.linear_model]
@architectures = "spacy.TextCatBOW.v3"
ngram_size = 1
no_output_layer = true
exclusive_classes = true
length = 262144
[components.textcat.model.tok2vec]
@architectures = "spacy-transformers.TransformerListener.v1"
upstream = "transformer"
pooling = {"@layers": "reduce_mean.v1"}
grad_factor = 1.0
[corpora]
[corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.train}
[corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
[training]
train_corpus = "corpora.train"
dev_corpus = "corpora.dev"
seed = ${system.seed}
gpu_allocator = ${system.gpu_allocator}
dropout = 0.1
accumulate_gradient = 1
patience = 1600
max_epochs = 10
max_steps = 2000
eval_frequency = 100
frozen_components = []
annotating_components = []
[training.optimizer]
@optimizers = "Adam.v1"
learn_rate = 0.00005
L2 = 0.01
grad_clip = 1.0
use_averages = false
eps = 1e-08
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
[training.batcher]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = false
tolerance = 0.2
[training.batcher.size]
@schedules = "compounding.v1"
start = 256
stop = 2048
compound = 1.001
[training.logger]
@loggers = "spacy.ConsoleLogger.v1"
progress_bar = true
[training.score_weights]
cats_score = 1.0
[initialize]
vectors = ${paths.vectors}
init_tok2vec = ${paths.init_tok2vec}
vocab_data = null
lookups = null
[initialize.components]
[initialize.tokenizer]
Make certain you may have a GPU at your disposal and launch the training CLI command!
python —m spacy train config.cfg --output ./output --gpu-id 0
You will notice the training starting with and you may monitor the lack of the TextCategorizer component.

Simply to be clear, we’re training here the TextCategorizer component, which is a small neural network head that receives the document representation and learns to predict the right label.
But we’re also fine-tuning RoBERTa during this training. Which means the RoBERTa weights are updated using the TREC dataset, so it learns how one can represent input questions in a way that’s more useful for classification.
Once the model is trained and saved, we are able to use it in inference!
import spacy
nlp = spacy.load("output/model-best")
doc = nlp("What's the capital of Italy?")
print(doc.cats)
The output needs to be something just like the next
{'LOC': 0.98, 'HUM': 0.01, 'NUM': 0.0, …}
Final Thoughts
To recap, on this post we saw how one can:Use a Hugging Face dataset with spaCy
- Convert text classification data into
.spacyformat - Configure a full pipeline using RoBERTa and
textcat - Train and test your model using spaCy CLI
This method works for any short text classification task, emails, support tickets, product reviews, FAQs, and even chatbot intents.