
ChatGPT something like: “Please scout all of tech for me and summarize trends and patterns based on what you think that I could be serious about,” you recognize that you simply’d get something generic, where it searches just a few web sites and news sources and hands you those.
It’s because ChatGPT is built for general use cases. It applies normal search methods to fetch information, often limiting itself to just a few web pages.
This text will show you easy methods to construct a distinct segment agent that may scout all of tech, aggregate hundreds of thousands of texts, filter data based on a persona, and find patterns and themes you possibly can act on.
The purpose of this workflow is to avoid sitting and scrolling through forums and social media on your individual. The agent should do it for you, grabbing whatever is helpful.

We’ll find a way to drag this off using a singular data source, a controlled workflow, and a few prompt chaining techniques.

By caching data, we will keep the price all the way down to just a few cents per report.
If you need to try the bot without booting it up yourself, you possibly can join this Discord channel. You’ll find the repository here if you need to construct it on your individual.
This text focuses on the final architecture and easy methods to construct it, not the smaller coding details as you will discover those in Github.
Notes on constructing
In case you’re latest to constructing with agents, you may feel like this one isn’t groundbreaking enough.
Still, if you need to construct something that works, you will want to use quite numerous software engineering to your AI applications. Even when LLMs can now act on their very own, they still need guidance and guardrails.
For workflows like this, where there may be a transparent path the system should take, you must construct more structured “workflow-like” systems. If you’ve a human within the loop, you possibly can work with something more dynamic.
The rationale this workflow works so well is because I even have a excellent data source behind it. Without this data moat, the workflow wouldn’t find a way to do higher than ChatGPT.
Preparing and caching data
Before we will construct an agent, we’d like to organize a knowledge source it will possibly tap into.
Something I believe numerous people get improper after they work with LLM systems is the idea that AI can process and aggregate data entirely by itself.
In some unspecified time in the future, we’d find a way to offer them enough tools to construct on their very own, but we’re not there yet by way of reliability.
So once we construct systems like this, we’d like data pipelines to be just as clean as for another system.
The system I’ve built here uses a knowledge source I already had available, which suggests I understand easy methods to teach the LLM to tap into it.
It ingests 1000’s of texts from tech forums and web sites per day and uses small NLP models to interrupt down the important keywords, categorize them, and analyze sentiment.
This lets us see which keywords are trending inside different categories over a selected time period.
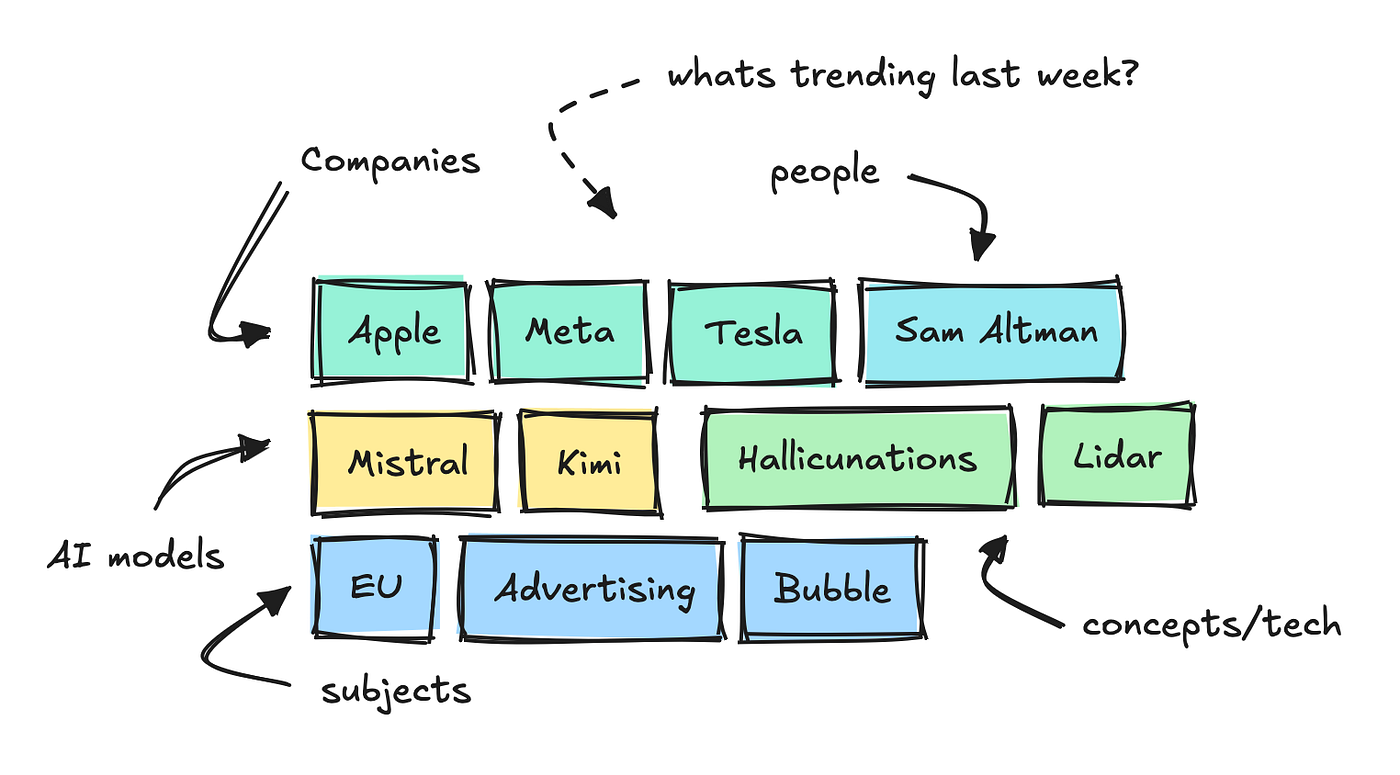
To construct this agent, I added one other endpoint that collects “facts” for every of those keywords.
This endpoint receives a keyword and a time period, and the system sorts comments and posts by engagement. Then it process the texts in chunks with smaller models that may resolve which “facts” to maintain.
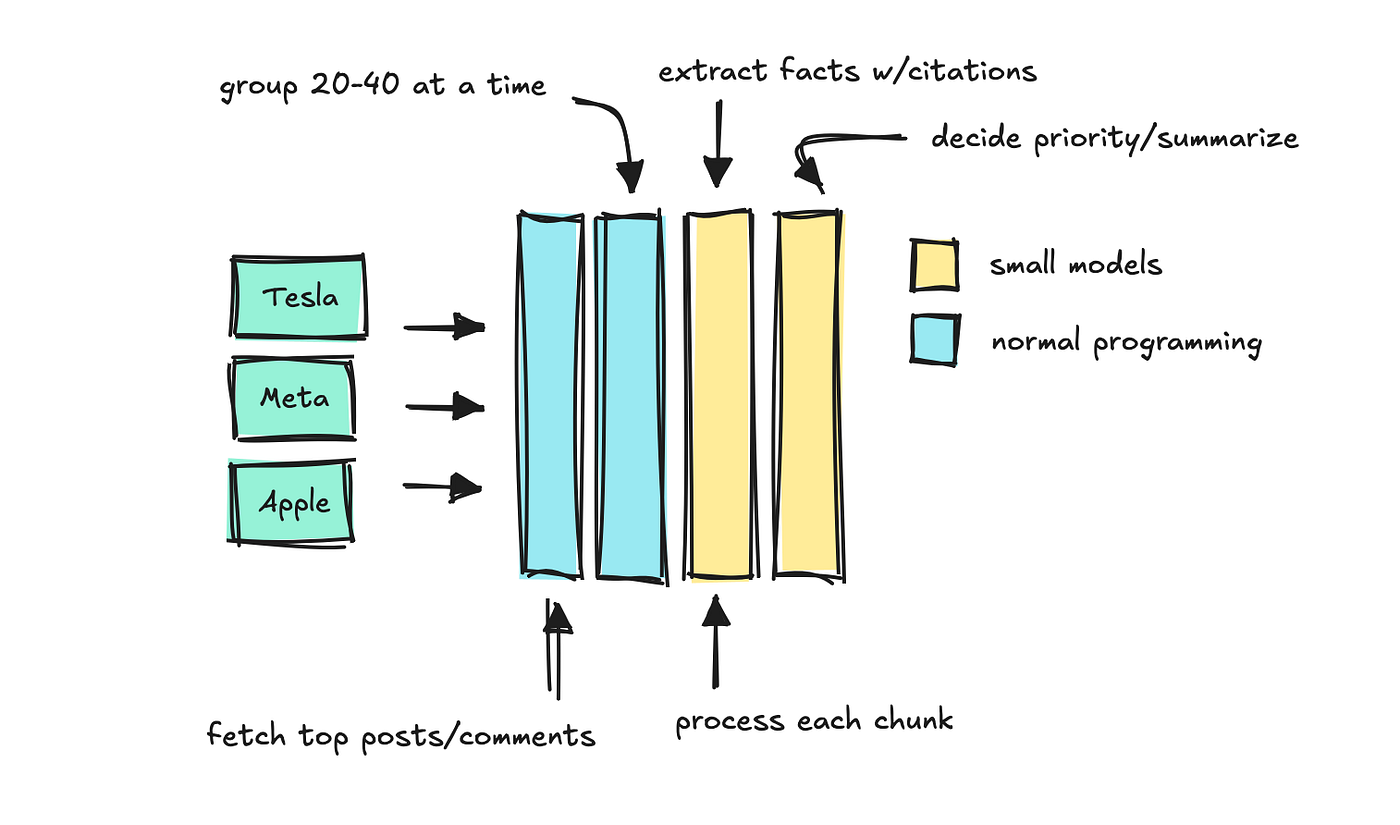
We apply a final LLM to summarize which facts are most vital, keeping the source citations intact.
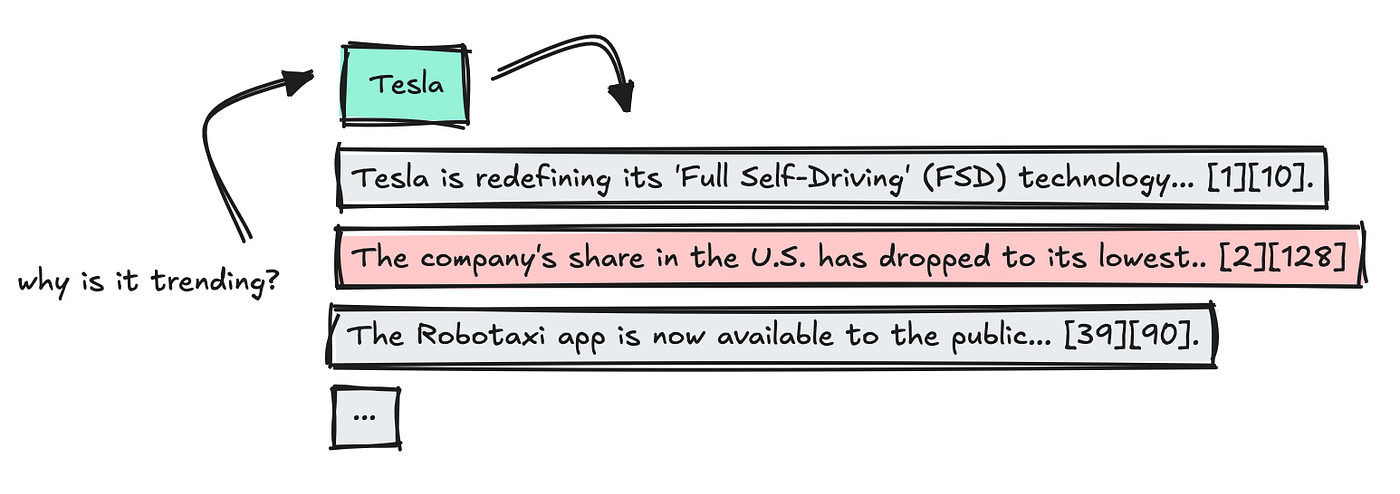
This can be a form of prompt chaining process, and I built it to mimic LlamaIndex’s citation engine.
The primary time the endpoint is known as for a keyword, it will possibly take as much as half a minute to finish. But because the system caches the result, any repeat request takes just just a few milliseconds.
So long as the models are sufficiently small, the price of running this on just a few hundred keywords per day is minimal. Later, we will have the system run several keywords in parallel.
You possibly can probably imagine now that we will construct a system to fetch these keywords and facts to construct different reports with LLMs.
When to work with small vs larger models
Before moving on, let’s just mention that selecting the fitting model size matters.
I believe that is on everyone’s mind at once.
There are quite advanced models you should utilize for any workflow, but as we begin to apply increasingly LLMs to those applications, the variety of calls per run adds up quickly and this may get expensive.
So, when you possibly can, use smaller models.
You saw that I used smaller models to cite and group sources in chunks. Other tasks which are great for small models include routing and parsing natural language into structured data.
In case you find that the model is faltering, you possibly can break the duty down into smaller problems and use prompt chaining, first do one thing, then use that result to do the subsequent, and so forth.
You continue to wish to use larger LLMs when it’s essential find patterns in very large texts, or while you’re communicating with humans.
On this workflow, the price is minimal because the information is cached, we use smaller models for many tasks, and the one unique large LLM calls are the ultimate ones.
How this agent works
Let’s undergo how the agent works under the hood. I built the agent to run inside Discord, but that’s not the main focus here. We’ll give attention to the agent architecture.
I split the method into two parts: one setup, and one news. The primary process asks the user to establish their profile.
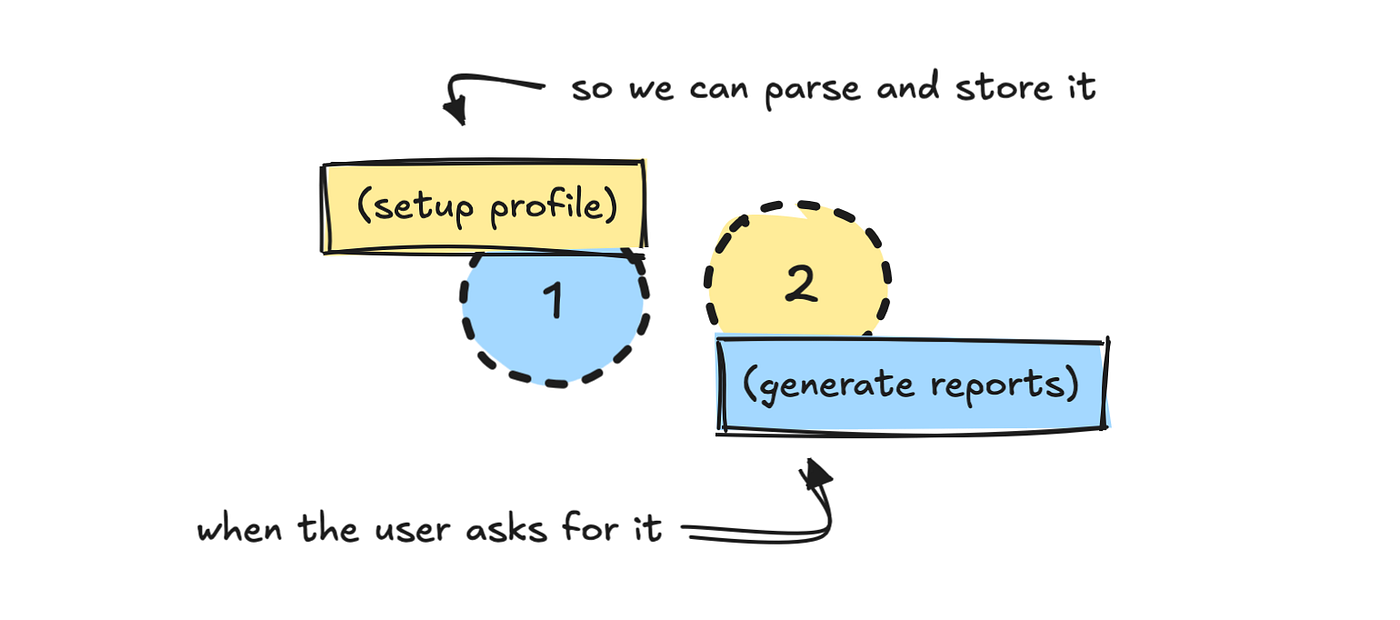
Since I already know easy methods to work with the information source, I’ve built a reasonably extensive system prompt that helps the LLM translate those inputs into something we will fetch data with later.
PROMPT_PROFILE_NOTES = """
You might be tasked with defining a user persona based on the user's profile summary.
Your job is to:
1. Pick a brief personality description for the user.
2. Select essentially the most relevant categories (major and minor).
3. Select keywords the user should track, strictly following the foundations below (max 6).
4. Choose time period (based only on what the user asks for).
5. Resolve whether the user prefers concise or detailed summaries.
Step 1. Personality
- Write a brief description of how we must always think concerning the user.
- Examples:
- CMO for non-technical product → "non-technical, skip jargon, give attention to product keywords."
- CEO → "only include highly relevant keywords, no technical overload, straight to the purpose."
- Developer → "technical, serious about detailed developer conversation and technical terms."
[...]
"""
I’ve also defined a schema for the outputs I would like:
class ProfileNotesResponse(BaseModel):
personality: str
major_categories: List[str]
minor_categories: List[str]
keywords: List[str]
time_period: str
concise_summaries: boolWithout having domain knowledge of the API and the way it really works, it’s unlikely that an LLM would work out easy methods to do that by itself.
For tasks like this, I attempt to all the time use structured outputs in JSON format. That way we will validate the result, and if validation fails, we re-run it.
That is the simplest strategy to work with LLMs in a system, especially when there’s no human within the loop to envision what the model returns.
Once the LLM has translated the user profile into the properties we defined within the schema, we store the profile somewhere. I used MongoDB, but that’s optional.
Storing the personality isn’t strictly required, but you do have to translate what the user says right into a form that helps you to generate data.
Generating the reports
Let’s take a look at what happens within the second step when the user triggers the report.
When the user hits the /news command, with or with out a time period set, we first fetch the user profile data we’ve stored.
This offers the system the context it must fetch relevant data, using each categories and keywords tied to the profile. The default time period is weekly.
From this, we get a listing of top and trending keywords for the chosen time period that could be interesting to the user.

Without this data source, constructing something like this could have been difficult. The info must be prepared upfront for the LLM to work with it properly.
After fetching keywords, it could make sense so as to add an LLM step that filters out keywords irrelevant to the user. I didn’t do this here.
Next, we use the endpoint prepared earlier, which comprises cached “facts” for every keyword. This offers us already vetted and sorted information for every one.
We run keyword calls in parallel to hurry things up, but the primary person to request a brand new keyword still has to attend a bit longer.
Once the outcomes are in, we mix the information, remove duplicates, and parse the citations so each fact links back to a selected source via a keyword number.
We then run the information through a prompt-chaining process. The primary LLM finds 5 to 7 themes and ranks them by relevance, based on the user profile. It also pulls out the important thing points.
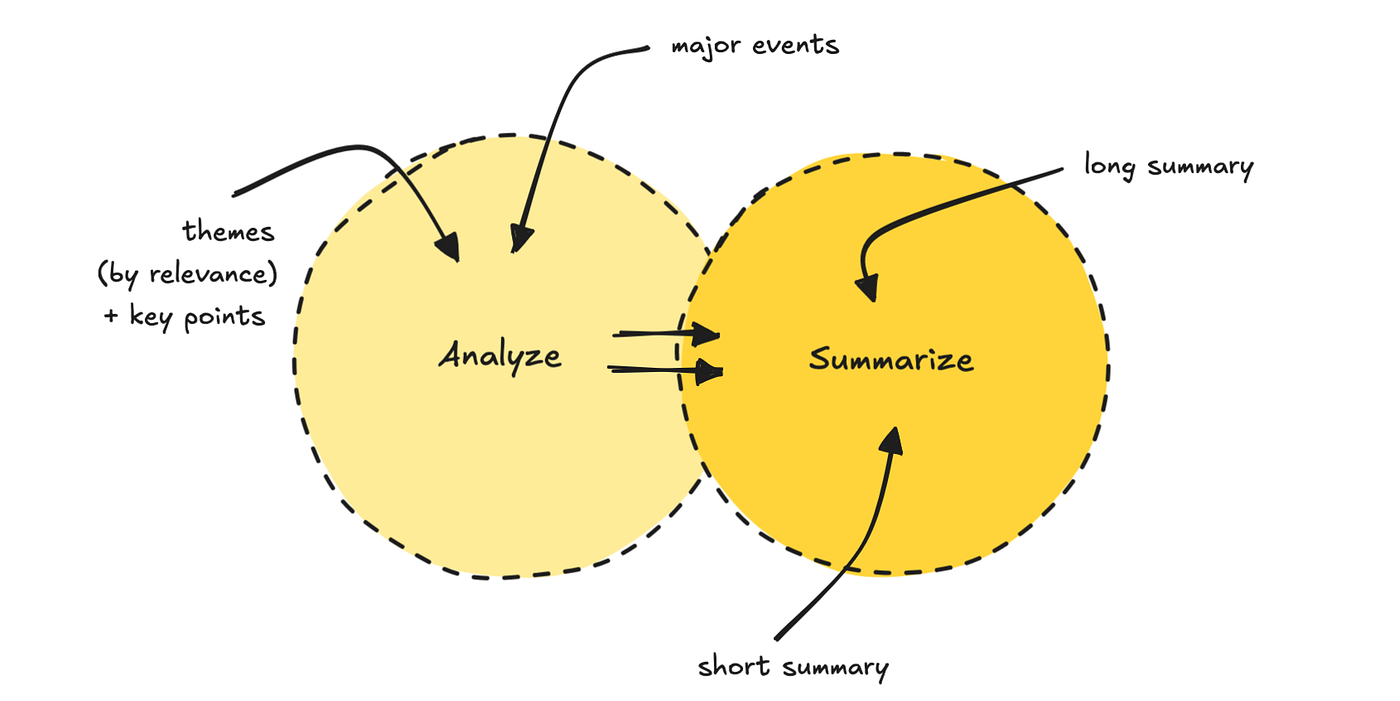
The second LLM pass uses each the themes and original data to generate two different summary lengths, together with a title.
We are able to do that to make sure that to cut back cognitive load on the model.
This last step to construct the report takes essentially the most time, since I selected to make use of a reasoning model like GPT-5.
You may swap it for something faster, but I find advanced models are higher at this last stuff.
The complete process takes just a few minutes, depending on how much has already been cached that day.
Take a look at the finished result below.
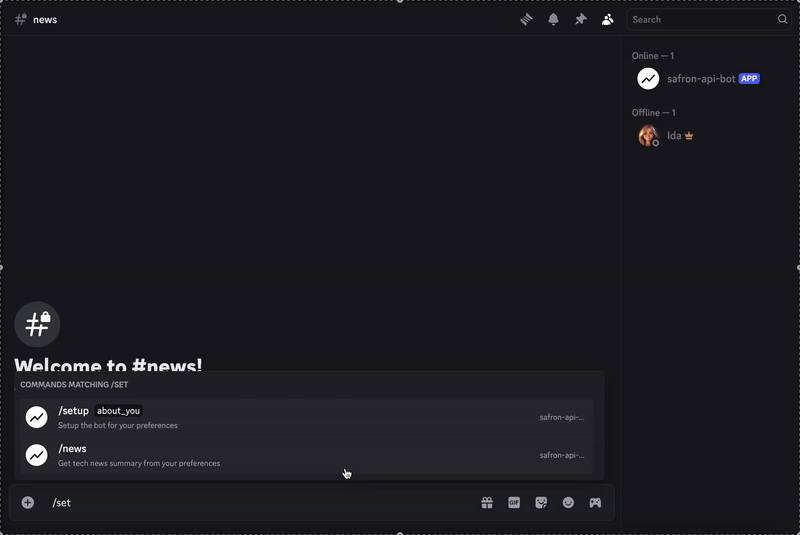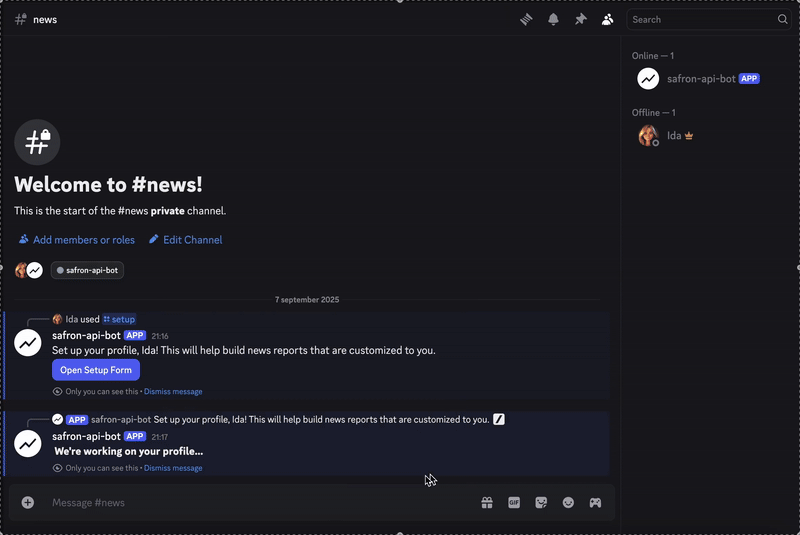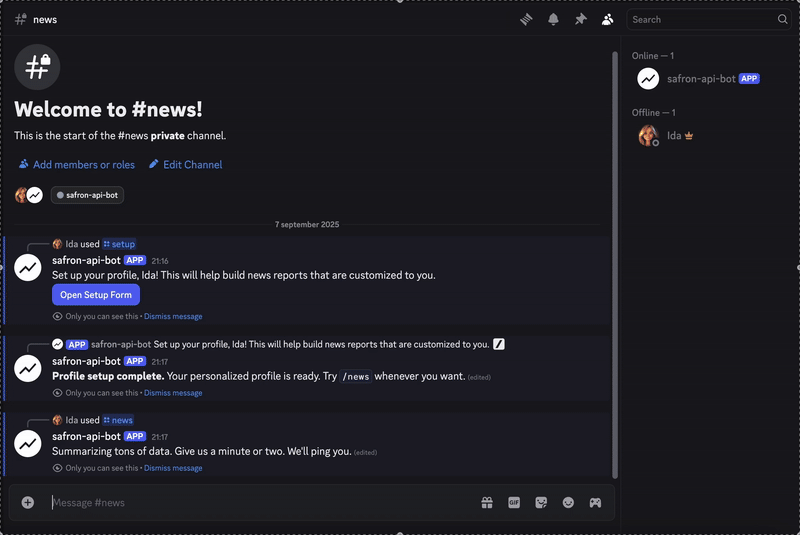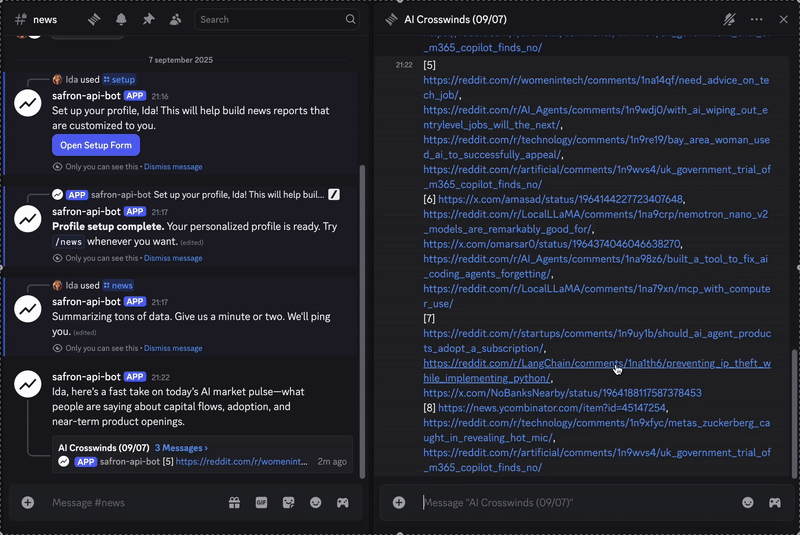
If you need to take a look at the code and construct this bot yourself, you will discover it here. In case you just wish to generate a report, you possibly can join this channel.
I even have some plans to enhance it, but I’m blissful to listen to feedback in the event you find it useful.
And in the event you need a challenge, you possibly can rebuild it into something else, like a content generator.
Notes on constructing agents
Every agent you construct might be different, so that is on no account a blueprint for constructing with LLMs. But you possibly can see the extent of software engineering this demands.
LLMs, at the very least for now, don’t remove the necessity for good software and data engineers.
For this workflow, I’m mostly using LLMs to translate natural language into JSON after which move that through the system programmatically. It’s the simplest strategy to control the agent process, but additionally not what people normally imagine after they consider AI applications.
There are situations where using a more free-moving agent is good, especially when there may be a human within the loop.
Nevertheless, hopefully you learned something, or got inspiration to construct something on your individual.
If you need to follow my writing, follow me here, my website, Substack, or LinkedIn.
❤