
mostly a
It’s not essentially the most exciting topic, but an increasing number of firms are being attentive. So it’s price digging into which metrics to trace to really measure that performance.
It also helps to have proper evals in place anytime you push changes, to be sure things don’t go haywire.
So, for this text I’ve done some research on common metrics for multi-turn chatbots, RAG, and agentic applications.
I’ve also included a fast review of frameworks like DeepEval, RAGAS, and OpenAI’s Evals library, so you already know when to select what.
This text is split in two. In case you’re recent, Part 1 talks a bit about traditional metrics like BLEU and ROUGE, touches on LLM benchmarks, and introduces the concept of using an LLM as a judge in evals.
If this isn’t recent to you, you possibly can skip this. Part 2 digs into evaluations of various sorts of LLM applications.
What we did before
In case you’re well versed in how we evaluate NLP tasks and the way public benchmarks work, you possibly can skip this primary part.
In case you’re not, it’s good to know what the sooner metrics like accuracy and BLEU were originally used for and the way they work, together with understanding how we test for public benchmarks like MMLU.
Evaluating NLP tasks
Once we evaluate traditional NLP tasks similar to classification, translation, summarization, and so forth, we turn to traditional metrics like accuracy, precision, F1, BLEU, and ROUGE
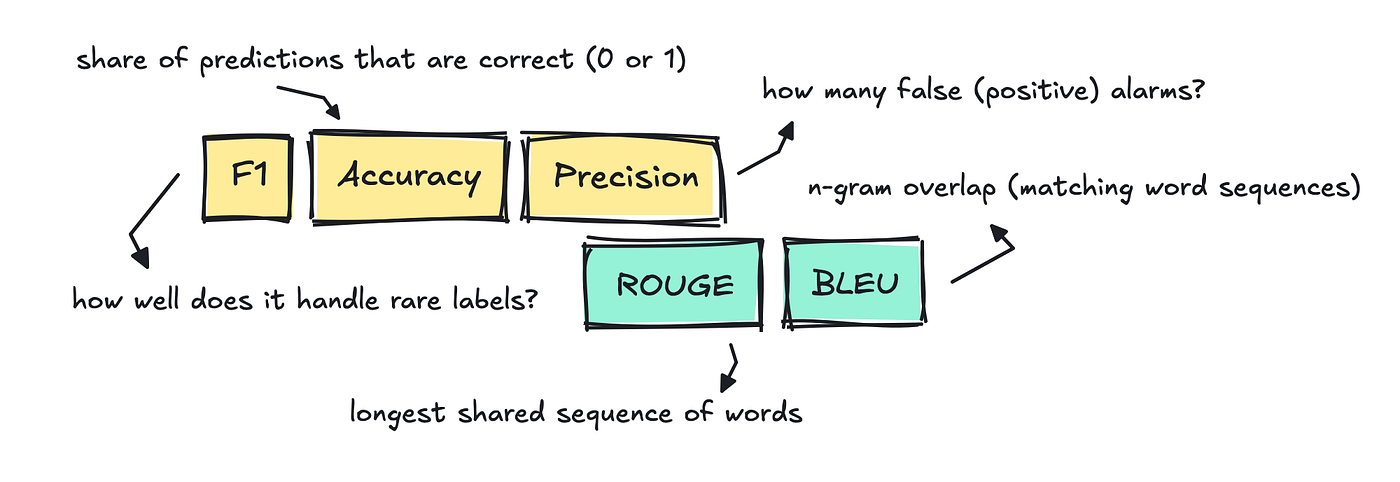
These metrics are still used today, but mostly when the model produces a single, easily comparable “right” answer.
Take classification, for instance, where the duty is to assign each text a single label. To check this, we will use accuracy by comparing the label assigned by the model to the reference label within the eval dataset to see if it got it right.
It’s very clear-cut: if it assigns the improper label, it gets a 0; if it assigns the right label, it gets a 1.
This implies if we construct a classifier for a spam dataset with 1,000 emails, and the model labels 910 of them accurately, the accuracy could be 0.91.
For text classification, we frequently also use F1, precision, and recall.
On the subject of NLP tasks like summarization and machine translation, people often used ROUGE and BLEU to see how closely the model’s translation or summary lines up with a reference text.
Each scores count overlapping n-grams, and while the direction of the comparison is different, essentially it just means the more shared word chunks, the upper the rating.
That is pretty simplistic, since if the outputs use different wording, it’ll rating low.
All of those metrics work best when there’s a single right answer to a response and are sometimes not the suitable selection for the LLM applications we construct today.
LLM benchmarks
In case you’ve watched the news, you’ve probably seen that each time a new edition of a giant language model gets released, it follows a number of benchmarks: MMLU Pro, GPQA, or Big-Bench.
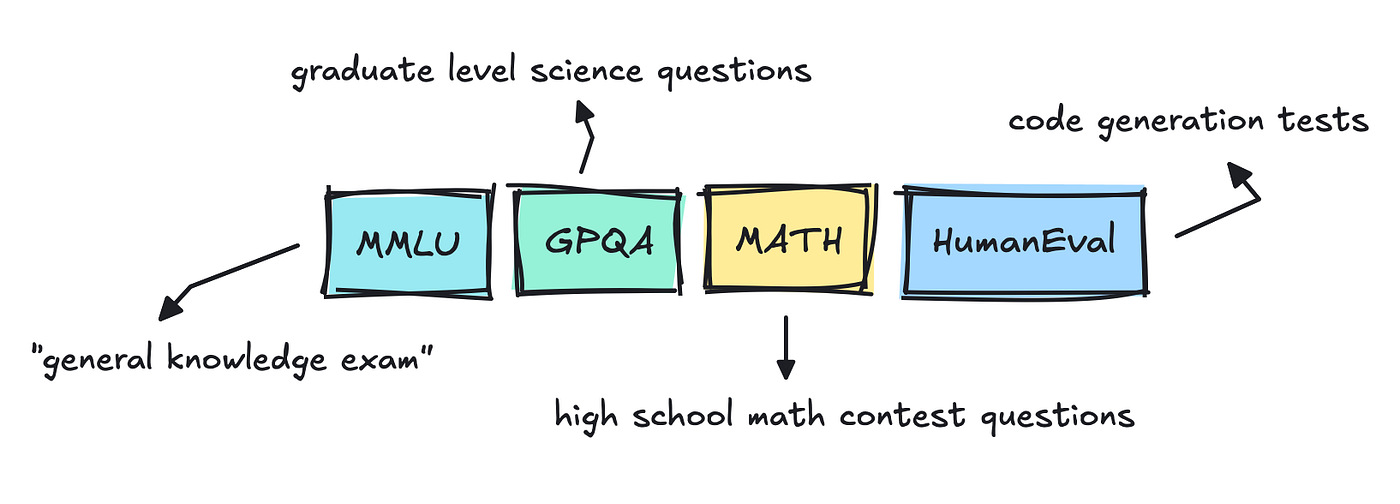
These are generic evals for which the correct term is de facto “benchmark” and never evals (which we’ll cover later).
Although there’s quite a lot of other evaluations done for every model, including for toxicity, hallucination, and bias, those that get a lot of the attention are more like exams or leaderboards.
Datasets like MMLU are multiple-choice and have been around for quite a while. I’ve actually skimmed through it before and seen how messy it’s.
Some questions and answers are quite ambiguous, which makes me think that LLM providers will attempt to train their models on these datasets simply to be sure they get them right.
This creates some fear in most people that the majority LLMs are only overfitting once they do well on these benchmarks and why there’s a necessity for newer datasets and independent evaluations.
LLM scorers
To run evaluations on these datasets, you possibly can normally use accuracy and unit tests. Nevertheless, what’s different now’s the addition of something called LLM-as-a-judge.
To benchmark the models, teams will mostly use traditional methods.
So so long as it’s multiple selection or there’s only one right answer, there’s no need for anything but to check the reply to the reference for an actual match.
That is the case for datasets similar to MMLU and GPQA, which have multiple selection answers.
For the coding tests (HumanEval, SWE-Bench), the grader can simply run the model’s patch or function. If every test passes, the issue counts as solved, and vice versa.
Nevertheless, as you possibly can imagine, if the questions are ambiguous or open-ended, the answers may fluctuate. This gap led to the rise of “LLM-as-a-judge,” where a big language model like GPT-4 scores the answers.
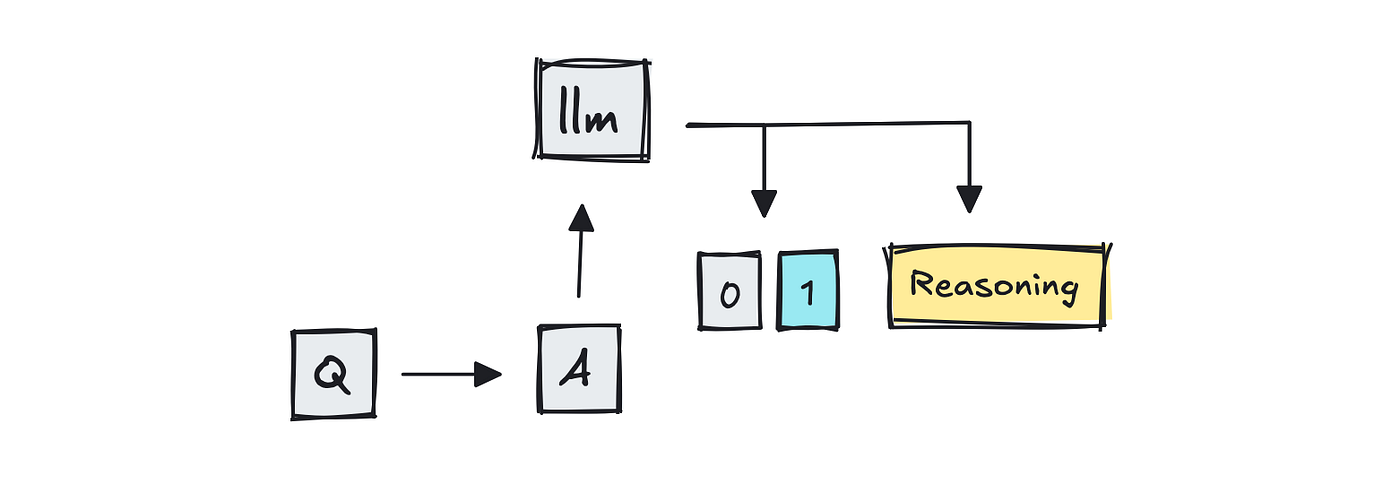
MT-Bench is one in every of the benchmarks that uses LLMs as scorers, because it feeds GPT-4 two competing multi-turn answers and asks which one is healthier.
Chatbot Arena, which use human raters, I believe now scales up by also incorporating the usage of an LLM-as-a-judge.
So, teams should still use overlap metrics like BLEU or ROUGE for quick sanity checks, or depend on exact-match parsing when possible, but what’s recent is to have one other large language model judge the output.
What we do with LLM apps
The first thing that changes now’s that we’re not only testing the LLM itself but all the system.
When we will, we still use programmatic methods to guage, identical to before.
For more nuanced outputs, we will start with something low-cost and deterministic like BLEU or ROUGE to take a look at n-gram overlap, but most up-to-date frameworks on the market will now use LLM scorers to guage.
There are three areas price talking about: evaluate multi-turn conversations, RAG, and agents, when it comes to the way it’s done and what sorts of metrics we will turn to.
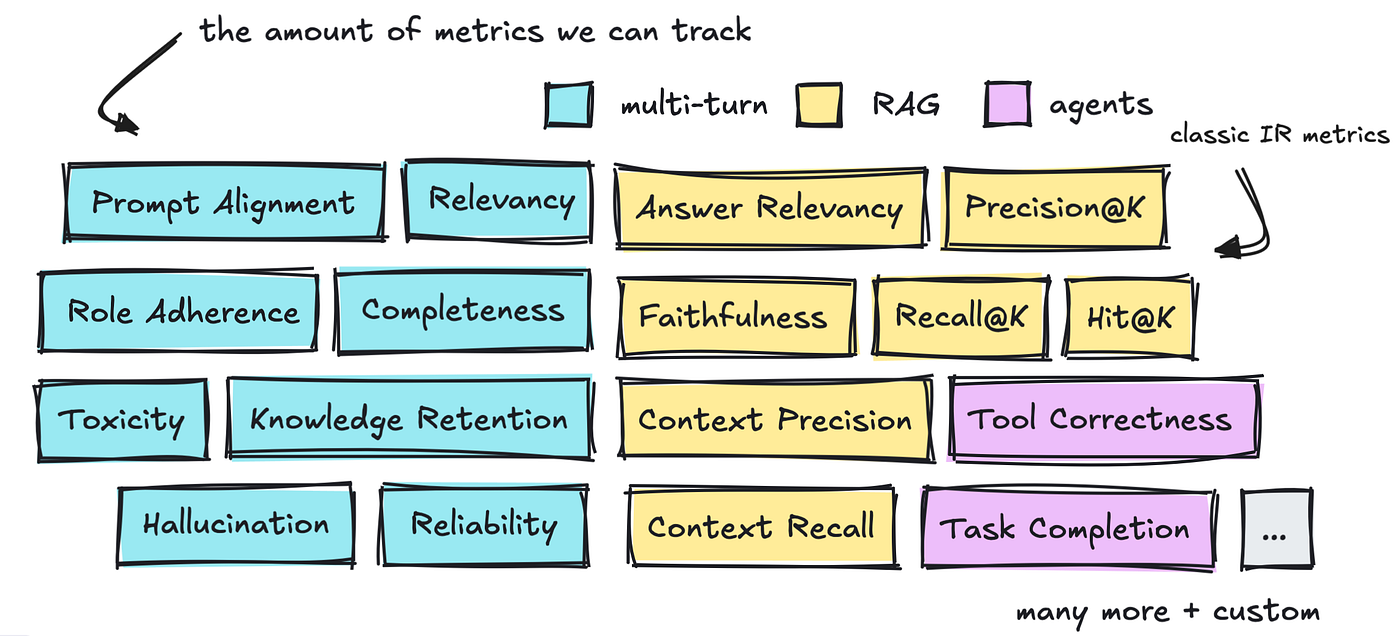
We’ll discuss all of those metrics which have already been defined briefly before moving on to the several frameworks that help us out.
Multi-turn conversations
The primary a part of that is about constructing evals for multi-turn conversations, those we see in chatbots.
Once we interact with a chatbot, we wish the conversation to feel natural, skilled, and for it to recollect the suitable bits. We would like it to remain on topic throughout the conversation and truly answer the thing we asked.
There are quite a number of standard metrics which have already been defined here. The primary we will discuss are Relevancy/Coherence and Completeness.
Relevancy is a metric that ought to track if the LLM appropriately addresses the user’s query and stays on topic, whereas Completeness is high if the ultimate final result actually addresses the user’s goal.
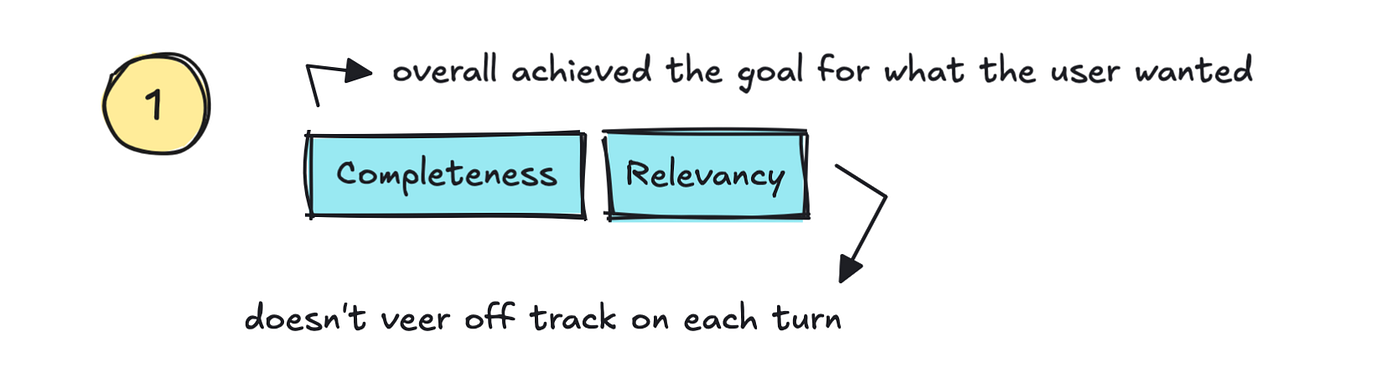
That’s, if we will track satisfaction across all the conversation, we may also track whether it really does “reduce support costs” and increase trust, together with providing high “self-service rates.”
The second part is Knowledge Retention and Reliability.
That’s: does it remember key details from the conversation, and might we trust it to not get “lost”? It’s not simply enough that it remembers details. It also must find a way to correct itself.
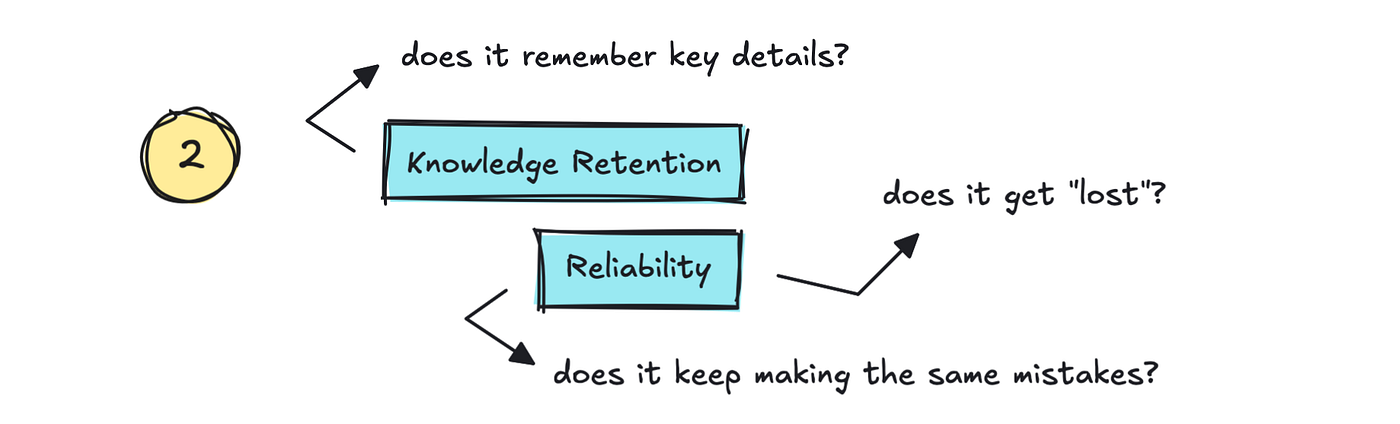
That is something we see in vibe coding tools. They forget the mistakes they’ve made after which keep making them. We must be tracking this as low Reliability or Stability.
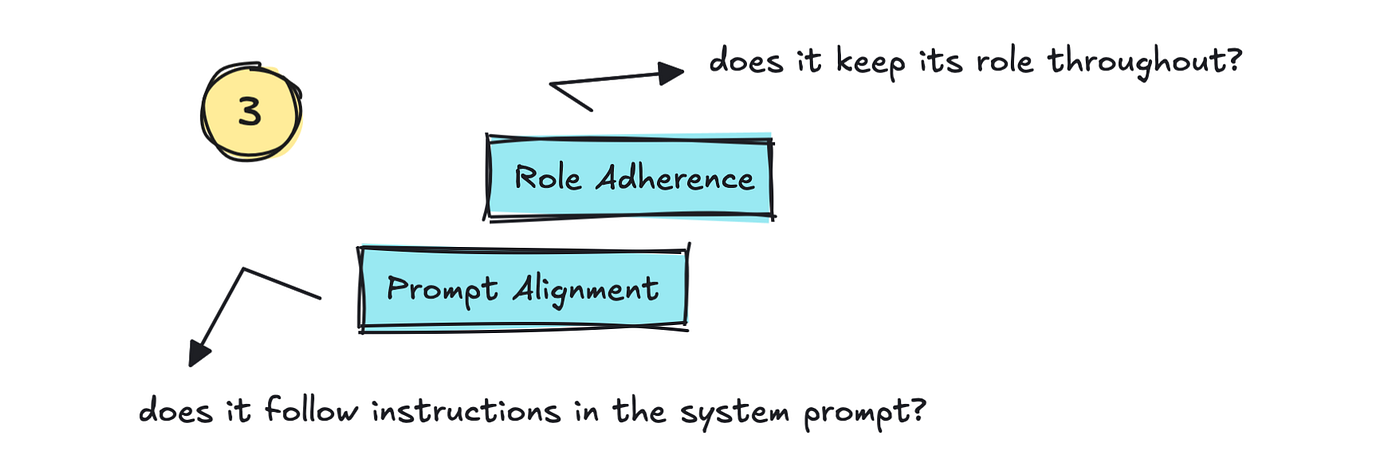
The third part we will track is Role Adherence and Prompt Alignment. This tracks whether the LLM sticks to the role it’s been given and whether it follows the instructions within the system prompt.
Next are metrics around safety, similar to Hallucination and Bias/Toxicity.
Hallucination is vital to trace but in addition quite difficult. People may try to establish web search to guage the output, or they split the output into different claims which are evaluated by a bigger model (LLM-as-a-judge style).
There are also other methods, similar to SelfCheckGPT, which checks the model’s consistency by calling it several times on the identical prompt to see if it sticks to its original answer and the way repeatedly it diverges.
For Bias/Toxicity, you should use other NLP methods, similar to a fine-tuned classifier.
Other metrics you could wish to track might be custom to your application, for instance, code correctness, security vulnerabilities, JSON correctness, and so forth.
As for do the evaluations, you don’t at all times must use an LLM, although in most of those cases the usual solutions do.
In cases where we will extract the right answer, similar to parsing JSON, we naturally don’t need to make use of an LLM. As I said earlier, many LLM providers also benchmark with unit tests for code-related metrics.
It goes without saying that using an LLM as a judge isn’t at all times super reliable, identical to the applications they measure, but I don’t have any numbers for you here, so that you’ll must hunt for that on your individual.
Retrieval Augmented Generation (RAG)
To proceed constructing on what we will track for multi-turn conversations, we will turn to what we want to measure when using Retrieval Augmented Generation (RAG).
With RAG systems, we want to separate the method into two: measuring retrieval and generation metrics individually.
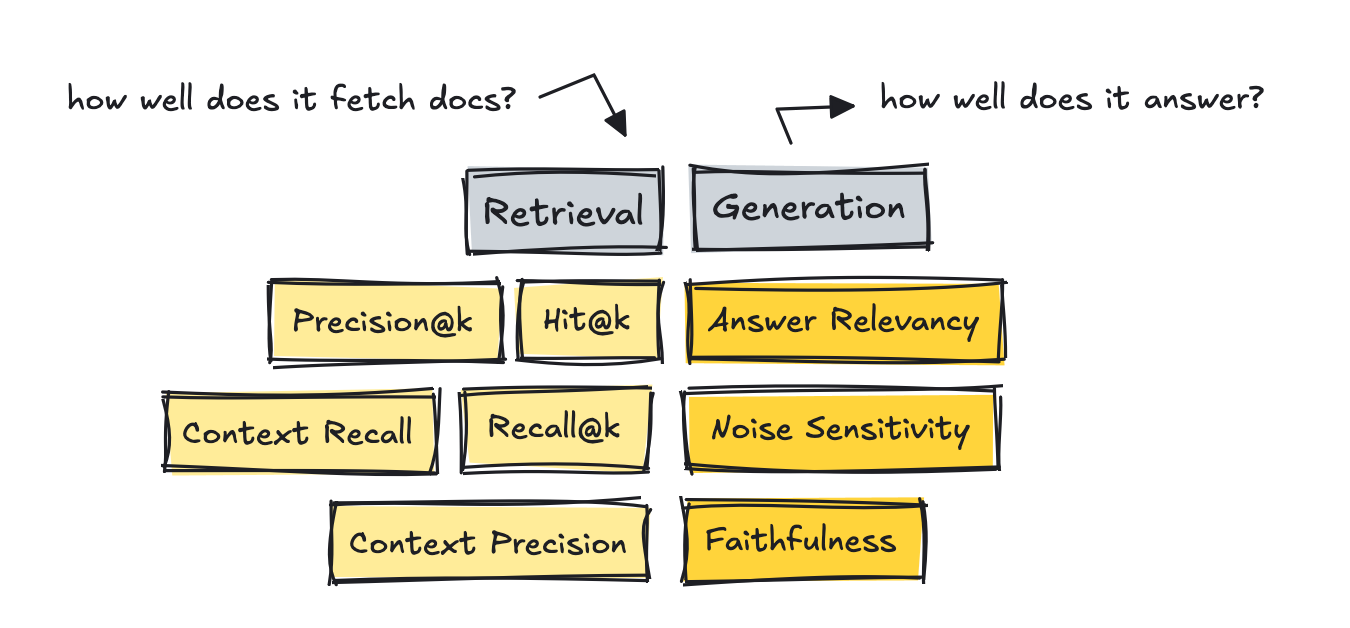
The primary part to measure is retrieval and whether the documents which are fetched are the right ones for the query.
If we get low scores on the retrieval side, we will tune the system by organising higher chunking strategies, changing the embedding model, adding techniques similar to hybrid search and re-ranking, filtering with metadata, and similar approaches.
To measure retrieval, we will use older metrics that depend on a curated dataset, or we will use reference-free methods that use an LLM as a judge.
I want to say the classic IR metrics first because they were the primary on the scene. For these, we want “gold” answers, where we arrange a question after which rank each document for that exact query.
Although you should use an LLM to construct these datasets, we don’t use an LLM to measure, since we have already got scores within the dataset to check against.
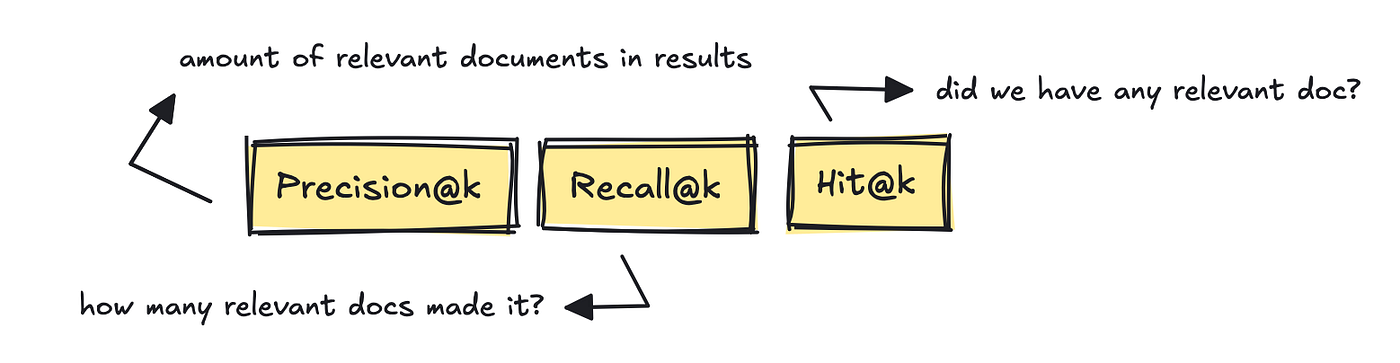
Probably the most well-known IR metrics are Precision@k, Recall@k, and Hit@k.
These measure the quantity of relevant documents in the outcomes, what number of relevant documents were retrieved based on the gold reference answers, and whether not less than one relevant document made it into the outcomes.
The newer frameworks similar to RAGAS and DeepEval introduces reference-free, LLM-judge style metrics like Context Recall and Context Precision.
These count how most of the truly relevant chunks made it into the highest K list based on the query, using an LLM to guage.
That’s, based on the query, did the system actually return any relevant documents based on the reply, or are there too many irrelevant ones to reply the query properly?
To construct datasets for evaluating retrieval, you possibly can mine questions from real logs after which use a human to curate them.
You too can use dataset generators with the assistance of an LLM, which exist in most frameworks or as standalone tools like YourBench.
In case you were to establish your individual dataset generator using an LLM, you would do something like below.
# Prompt to generate questions
qa_generate_prompt_tmpl = """
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and no prior knowledge
generate only {num} questions and {num} answers based on the above context.
...
"""Nevertheless it would must be a bit more advanced.
If we turn to the generation a part of the RAG system, we at the moment are measuring how well it answers the query using the provided docs.
If this part isn’t performing well, we will adjust the prompt, tweak the model settings (temperature, etc.), replace the model entirely, or fine-tune it for domain expertise. We may also force it to “reason” using CoT-style loops, check for self-consistency, and so forth.
For this part, RAGAS is beneficial with its metrics: Answer Relevancy, Faithfulness, and Noise Sensitivity.
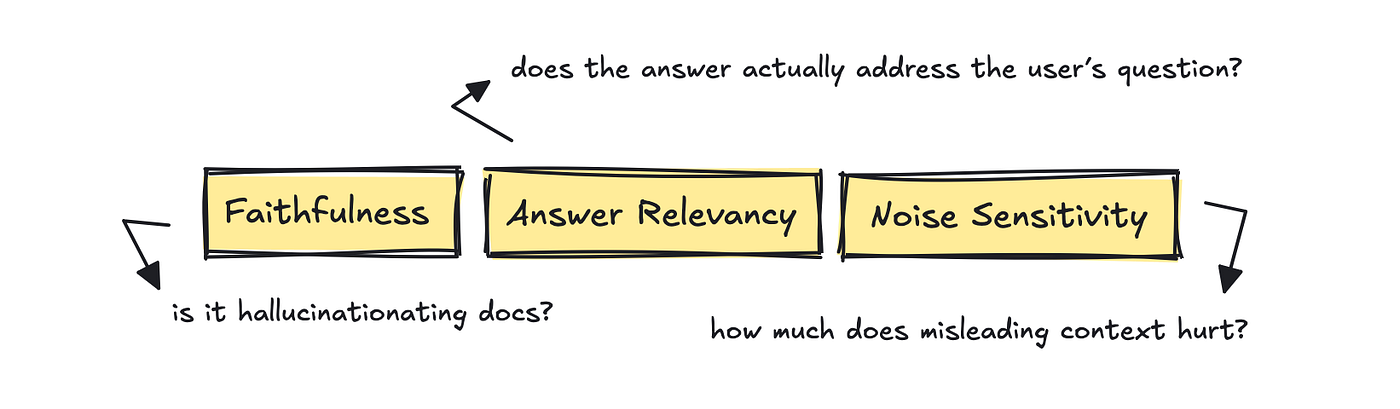
These metrics ask whether the reply actually addresses the user’s query, whether every claim in the reply is supported by the retrieved docs, and whether a little bit of irrelevant context throws the model off track.
If we take a look at RAGAS, what they likely do for the primary metric is ask the LLM to “Rate from 0 to 1 how directly this answer addresses the query,” providing it with the query, answer, and retrieved context. This returns a raw 0–1 rating that could be used to compute averages.
So, to conclude we split the system into two to guage, and although you should use methods that depend on the IR metrics it’s also possible to use reference free methods that depend on an LLM to attain.
The last item we want to cover is how agents are expanding the set of metrics we now have to track, beyond what we’ve already covered.
Agents
With agents, we’re not only the output, the conversation, and the context.
Now we’re also evaluating the way it “moves”: whether it may well complete a task or workflow, how effectively it does so, and whether it calls the suitable tools at the suitable time.
Frameworks will call these metrics in another way, but essentially the highest two you must track are Task Completion and Tool Correctness.
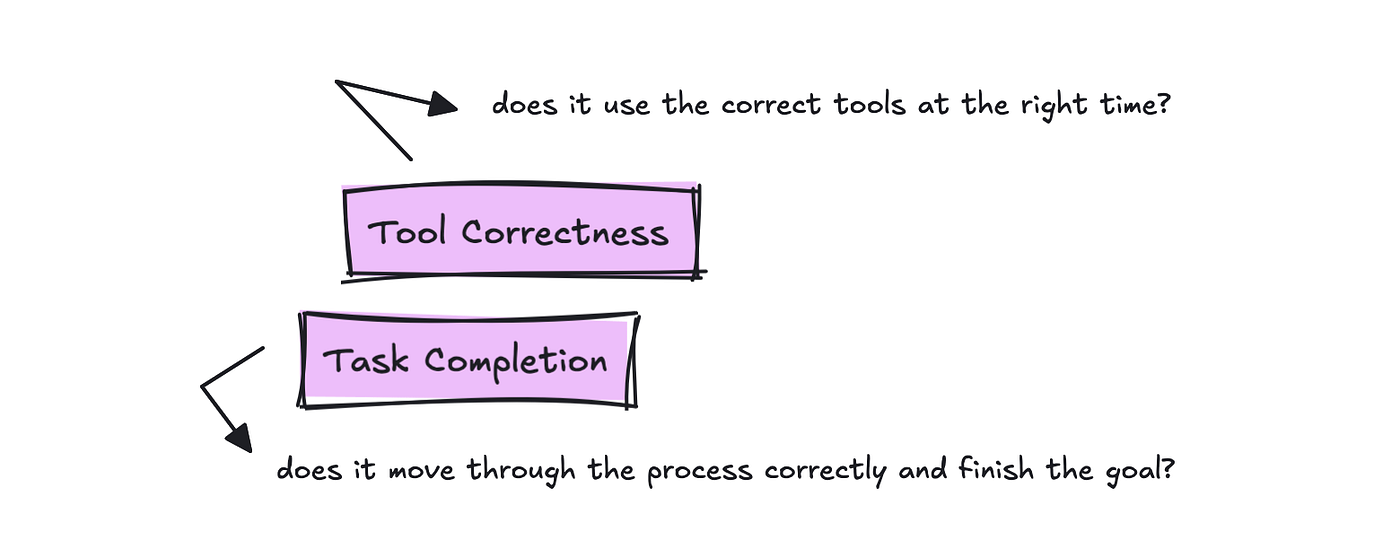
For tracking tool usage, we wish to know if the right tool was used for the user’s query.
We do need some form of gold script with ground truth inbuilt to check each run, but you possibly can creator that when after which use it every time you make changes.
For Task Completion, the evaluation is to read all the trace and the goal, and return a number between 0 and 1 with a rationale. This could measure how effective the agent is at accomplishing the duty.
For agents, you’ll still have to test other things we’ve already covered, depending in your application
Next, let’s turn to get an summary of the favored frameworks on the market that may allow you to out.
Eval frameworks
There are quite a number of frameworks that allow you to out with evals, but I would like to discuss a number of popular ones: RAGAS, DeepEval, OpenAI’s and MLFlow’s Evals, and break down what they’re good at and when to make use of what.
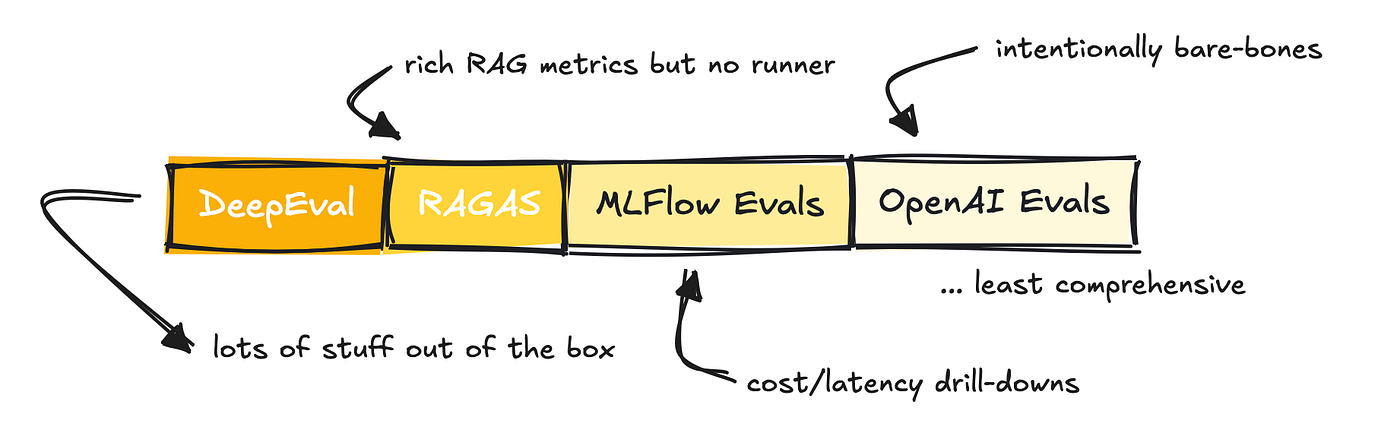
OpenAI and MLFlow’s Evals are add-ons somewhat than stand-alone frameworks, whereas RAGAS was primarily built as a metric library for evaluating RAG applications (although they provide other metrics as well).
DeepEval is possibly essentially the most comprehensive evaluation library out of all of them.
Nevertheless, it’s essential to say that all of them offer the power to run evals on your individual dataset, work for multi-turn, RAG, and agents indirectly or one other, support LLM-as-a-judge, allow organising custom metrics, and are CI-friendly.
They differ, as mentioned, in how comprehensive they’re.
MLFlow was primarily built to guage traditional ML pipelines, so the variety of metrics they provide is lower for LLM-based apps. OpenAI is a really lightweight solution that expects you to establish your individual metrics, although they supply an example library to allow you to start.
RAGAS provides quite a number of metrics and integrates with LangChain so you possibly can run them easily.
DeepEval offers loads out of the box, including the RAGAS metrics.
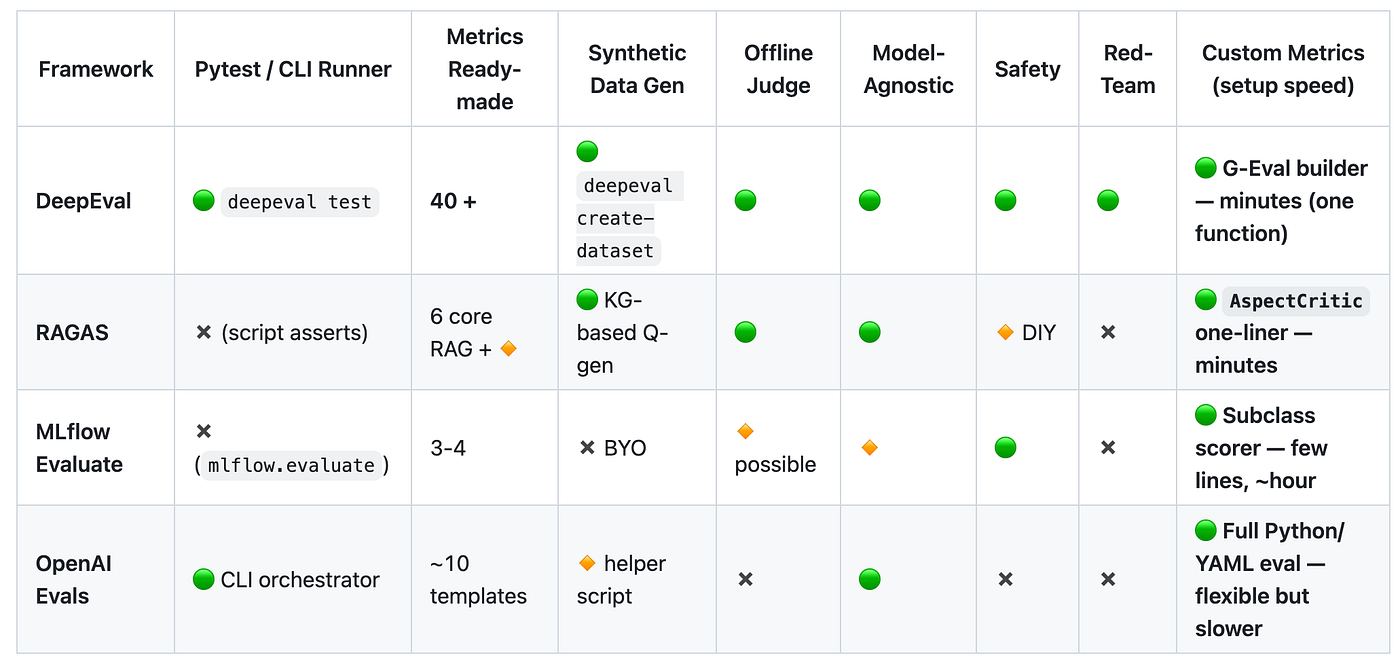
If we take a look at the metrics being offered, we will get a way of how extensive these solutions are.
It’s price noting that those offering metrics don’t at all times follow a regular in naming. They might mean the identical thing but call it something different.
For instance, faithfulness in a single may mean the identical as groundedness in one other. Answer relevancy would be the same as response relevance, and so forth.
This creates plenty of unnecessary confusion and complexity around evaluating systems basically.
Nevertheless, DeepEval stands out with over 40 metrics available and likewise offers a framework called G-Eval, which helps you arrange custom metrics quickly making it the fastest way from idea to a runnable metric.
OpenAI’s Evals framework is healthier suited once you want bespoke logic, not once you just need a fast judge.
Based on the DeepEval team, custom metrics are what developers arrange essentially the most, so don’t get stuck on who offers what metric. Your use case will probably be unique, and so will the way you evaluate it.
So, which do you have to use for what situation?
Use RAGAS once you need specialized metrics for RAG pipelines with minimal setup. Pick DeepEval once you want a whole, out-of-the-box eval suite.
MLFlow is a superb selection if you happen to’re already invested in MLFlow or prefer built-in tracking and UI features. OpenAI’s Evals framework is essentially the most barebones, so it’s best if you happen to’re tied into OpenAI infrastructure and need flexibility.
Lastly, DeepEval also provides red teaming via their DeepTeam framework, which automates adversarial testing of LLM systems. There are other frameworks on the market that do that too, although perhaps not as extensively.
I’ll must do something on adversarial testing of LLM systems and prompt injections in the long run. It’s an interesting topic.
The dataset business is lucrative business which is why it’s great that we’re now at this point where we will use other LLMs to annotate data, or rating tests.
Nevertheless, LLM judges aren’t magic and the evals you’ll arrange you’ll probably discover a bit flaky, just as with another LLM application you construct. Based on the world wide web, most teams and firms sample-audit with humans every few weeks to remain real.
The metrics you arrange in your app will likely be custom, so though I’ve now put you thru hearing about quite many you’ll probably construct something on your individual.
It’s good to know what the usual ones are though.
Hopefully it proved educational anyhow.
In case you liked this one, remember to read a few of my other articles here on TDS, or on Medium.
You may follow me here, LinkedIn or my website if you must get notified after I release something recent.
❤