
Huawei has released its next -generation artificial intelligence (AI) data center architecture. Through this, he insisted that AI chip ‘Ascend’ implemented NVIDIA’s ‘H100’ and ‘H800’ GPU.
Huawei is a next -generation data center architecture to construct a high -performance AI infrastructure on the nineteenth (local time).Cloud Matrix 384 (Cloudmatrix384)‘The paper on the archive was published.
The Cloud Matrix 384 combines 384 Ascend 910C NPUs, 192 Kunpeng CPUs and other hardware components with one integrated super node, and is interconnected with an ultra -high bandwidth and low -cost integrated bus (UB) network.
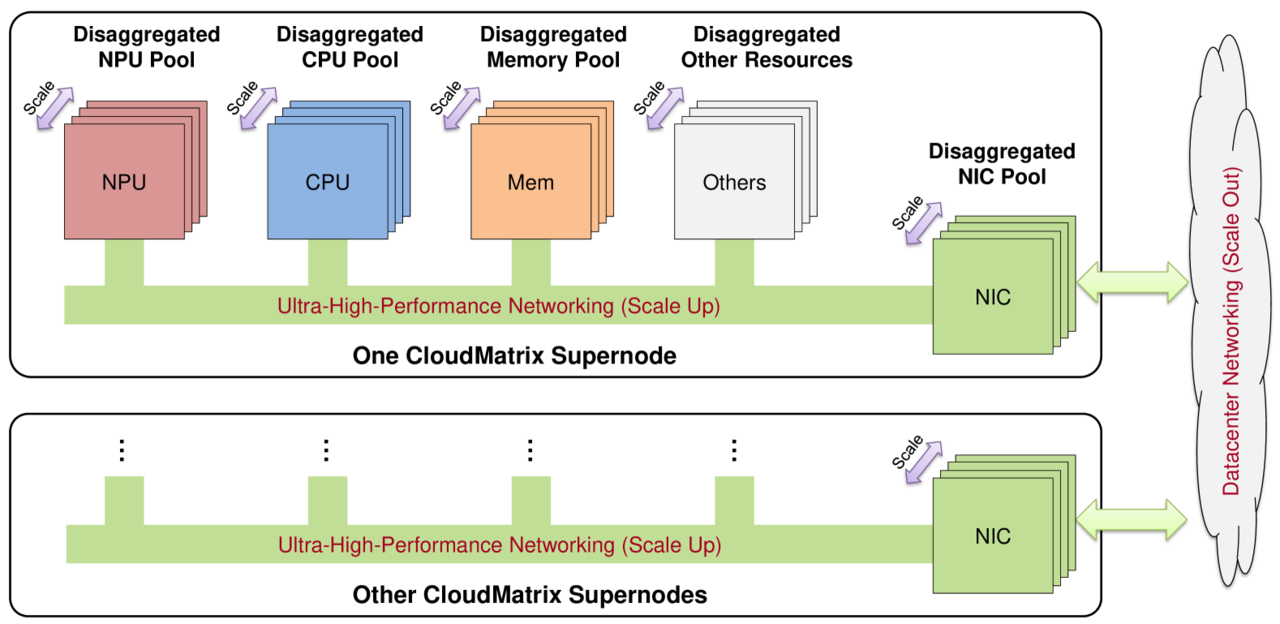
Unlike conventional hierarchical designs, the Cloud Matrix 384 enables all-to-all communication between the UB network. Through this, it’s designed to dynamically integrate the computational resources, memory, and network resources, uniform access, and independently expand.
This architecture is very outstanding in communication-intensive operations, similar to parallel processing of large-scale expert mixing (MOE) models and distributed key-value (KV) cache, and is attracting attention as a foundation for next-generation large language (LLM) services.
Huawei has developed the Cloud Matrix-Infer, an AI reasoning solution optimized for this architecture, and presented the next-generation AI service structure for MOE models similar to ‘Deep Chic-R1’.
▲ The structure that separates the prefill, decode, and caching and operates into an individually expandable resource pool, ▲ large MOE parallel processing strategy ▲ INT8 precision quantization and microcrafting pip lining, etc. are applied.
First, we designed a peer-to-to-peer service architecture separated by prefill, decode, and caching into independent expandable resource pools, respectively. Unlike the present KV cache -centered structure, it enables access to high bandwidth and uniform cache data by utilizing UB networks, reducing data location constraints, simplifying work scheduling, and improving cache efficiency.
As well as, the corporate introduced a big -scale skilled parallelization (EP) strategy that uses UB network to efficiently mix token distribution and expert output. This strategy supports the high parallel level of EP320, and every NPU allows just one skilled to reduce decode delay.
As well as, the hardware -friendly optimization technique optimized for Cloud Matrix 384 is applied. Highly optimized operators, micro layout -based pip lines, and INT8 precision quantification, which greatly improved execution efficiency and resource utilization.
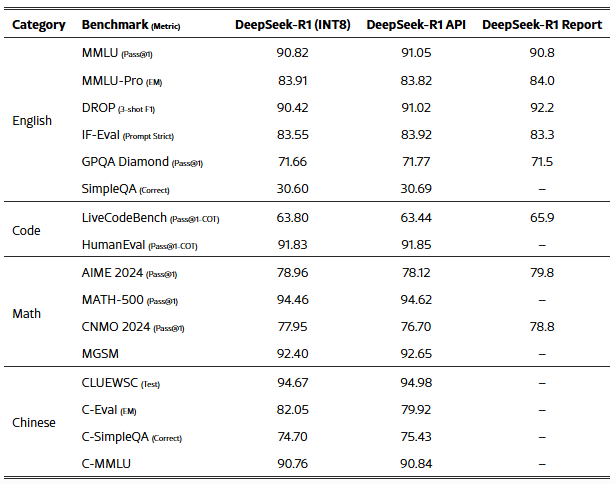
Because of this, Cloud Matrix-Infers recorded 6688 tokens per second per second of Ascend chip, 1943 tokens per second, and lower than 50ms.
That is ahead of the operational efficiency in comparison with the present system based on the NVIDIA H100 and H800, and the delay time is 15ms and lower than 15ms. Specifically, despite the INT8 quantization application, it maintained similar accuracy to the official Deep Chic-R1 API.
This technology progress can be consistent with the recent remarks of the founding father of Runjeong Pay Huawei. “Ascend chips are multiple generation than American competitors, but stacking and clustering can realize the world’s best performance.”
Jensen Hwang Nvidia also agreed. “AI is basically a parallel processing problem, so when you haven’t got enough performance in individual computers, you possibly can connect more chips in energy -rich places like China.”
By Park Chan, reporter cpark@aitimes.com