
Although ‘ICL’, also often known as ‘Few-Shot learning’, has a greater performance than fine-tuning in generalization of recent tasks, but has an issue that costs more in reasoning calculations. Google has proposed a brand new artificial intelligence (AI) model learning that adds some great benefits of the 2 methods.
The researchers at Google Deep Mind and Stanford University are two typical methods that adjust LLM for specific tasks on the ninth (local time). Comparative evaluation of micro-adjustment and generalization performance of ICL (in-context learning)Announced.
The wonderful adjustment is a technique of re -learning a preliminary LLM with a small dataset for a selected purpose. On this process, the inner parameters of the model are adjusted.
ICL, then again, provides a prompt that incorporates some response examples that solve the issue with the issue that should be solved, without changing the parameters of the model, and the model sees it and learns it. Specifically, ICL doesn’t need to alter the parameters of the model, so the user can use and access it more easily.
Google was in April last 12 months ‘Many-shot in-context learning‘ICL has introduced the usefulness of ICL through the eyes of’.
This time, ICL discovered that ICL showed higher generalization, but emphasized that higher calculation costs are generated throughout the reasoning process. He also proposed a brand new approach to some great benefits of each methods.
The researchers designed a ‘controlled artificial dataset’ to match the 2 methods of generalization. The actual fact -based data with complex and consistent structures, corresponding to virtual family relationships and fictional hierarchies, have been generated, and all nouns, adjectives, and verbs have been replaced by random words in order that the model has never been prematurely.
The test tasks consisted of varied forms corresponding to reversals, Syllogisims inferences, and hierarchical meaning structure evaluation. For instance, “Femp is more dangerous than glon”, and the model can infer the undeniable fact that “Glon is less dangerous than Pemp” or “All Glon is YOMP” and “All Trope is Glon.” I evaluated whether it will be.
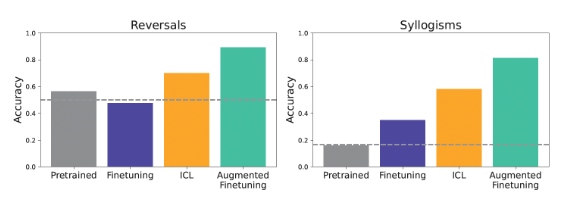
To this end, I used ‘Geminai 1.5 Flash’. In consequence, the ICL method showed higher generalization in most tasks. Specifically, it was found to be advantageous in tasks corresponding to relationship reasoning and logical induction.
As such, ICL shows strong generalization performance, nevertheless it has the drawback of high computation costs since it is mandatory to enter a considerable amount of context information each time.
In consequence, the researchers proposed a brand new ‘augmented fine-tuning’ method that mixes some great benefits of ICL and wonderful coordination.
This method is the important thing to making a recent example by utilizing the ICL capability of LLM itself and using it as a micro -adjustment learning data.
Augmented strategies are divided into two. Local strategies transform individual sentences or generate intuitive reasoning results, corresponding to backpow theory from single information. The worldwide strategy provides your entire dataset in context and connects the data given to induce deeper reasoning.
This method explains that it will probably make the wonderful adjusted model more reliably and versatile to varied inputs without the necessity to perform the ICL each time.
Matt Lampinen Google Deep Mind Research Scientist said, “Data enhancement requires additional computation costs, but the whole cost is lower than the ICL method when using the model repeatedly.”
As well as, micro -adjustment alone could also be idea to hunt augmented wonderful adjustment if the performance shouldn’t be enough.
“I hope this study will aid you to learn foundation model and understand generalization, and to enhance your model’s practicality.”
By Park Chan, reporter cpark@aitimes.com