
Recently, Huawei, who strained the USA with the event of a brand new AI chip that’s such as the NVIDIA ‘H100’, has released a model optimized for the chip. Like deep chic, it adopts a MOE method and maximizes efficiency with chip engineering technology.
Huawei Cloud researchers are designed for ‘Ascend NPU’ through the net archive on the seventh.Pan -gu Ultra Moe (PANGU ULTRA MOE)‘The model has been released.
This can be a large language model (LLM) of 718 billion parameters. In other words, it has a dynamic structure that works just for some expert models in accordance with the query.
Above all, the model architecture was transformed into 1000’s of model architectures and simulation focused on optimizing system design.
Five ways, similar to parallelization of pipeline, parallelization of tensor, parallelization of experts, parallelization of knowledge, and context parallelization, a big -scale simulation combined with experts, hierarchies, and hidden states. Because of this, the ultimate model was confirmed that the perfect performance was available when including 256 experts, Hidden State 7680 and 61 layers.
As well as, it optimizes communication between NPU devices to cut back synchronization overhead and distribute lively memory loads.
Because of this, the model used 6000 Ascend NPUs to attain 30.0%of model flop utilization (MFU) and handled 1.46 million tokens per second. This is similar MFU performance as Deep Chic-R1.
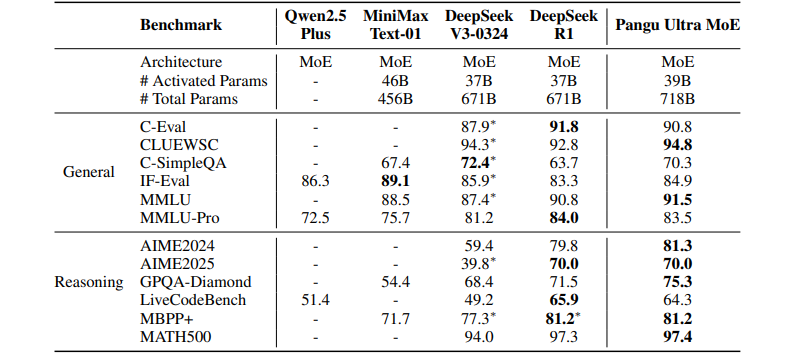
It showed competitive performance on the benchmark. 81.3%and 97.4%were accurate in AIME 2024 and Math 500, which measure mathematics. 94.8%of Chinese understanding (Cluewsc) and 91.5%in Knowledge Evaluation (MMLU). This is usually over Deep Chic-R1.
As such, this model is meaningful that it has found a mix that’s optimized for hardware by utilizing the strengths of chip manufacturers. This shows that it could construct a model that performs advanced performance without counting on US technologies similar to NVIDIA.
Huawei has already launched a model that has been trained only with China’s iFlatetech and ascend chips. The reasoning model called ‘Xinghuo X1’, which was released last month, can be known to have the identical performance as ‘O1’ of Deep Chic-R1 and Open AI.
Recently, rumors have emerged that they’ve cooperated in learning Deep Chic’s next model, R2. As such, the chip was supplied to the educational of the most recent models of major Chinese firms, and the technology has been raised, and now it has released its own model. This is comparable to NVIDIA’s approach.
The researchers said, “This study shows that efficient learning of rare models using MOE is feasible through a wide selection of experiments.”
By Dae -jun Lim, reporter ydj@aitimes.com