
Tencent is within the strategy of releasing a new edition of its Hunyuan Video model, titled The brand new release is outwardly capable of creating Hunyuan LoRA models redundant, by allowing the user to create ‘deepfake’-style video customization through a image:
Source: https://hunyuancustom.github.io/ (warning: CPU/memory-intensive site!)
Within the left-most column of the video above, we see the one source image supplied to HunyuanCustom, followed by the brand new system’s interpretation of the prompt within the second column, next to it. The remaining columns show the outcomes from various proprietary and FOSS systems: Kling; Vidu; Pika; Hailuo; and the Wan-based SkyReels-A2.
Within the video below, we see renders of three scenarios essential to this release: respectively, ; ; and (person + clothes):
We are able to notice just a few things from these examples, mostly related to the system counting on a as a substitute of multiple images of the identical subject.
In the primary clip, the person is basically still facing the camera. He dips his head down and sideways at not far more than 20-25 degrees of rotation, but, at an inclination in excess of that, the system would really have to start out guessing what he looks like in profile. This is tough, probably not possible to gauge accurately from a sole frontal image.
Within the second example, we see that the little girl is within the rendered video as she is in the one static source image. Again, with this sole image as reference, the HunyuanCustom would need to make a comparatively uninformed guess about what her ‘resting face’ looks like. Moreover, her face doesn’t deviate from camera-facing stance by greater than the prior example (‘man eating crisps’).
Within the last example, we see that for the reason that source material – the girl and the garments she is prompted into wearing – should not complete images, the render has cropped the scenario to suit – which is definitely slightly a great solution to a knowledge issue!
The purpose is that though the brand new system can handle multiple images (akin to , or ), it doesn’t apparently allow for multiple angles or alternative views , in order that diverse expressions or unusual angles might be accommodated. To this extent, the system may subsequently struggle to switch the growing ecosystem of LoRA models which have sprung up around HunyuanVideo since its release last December, since these will help HunyuanVideo to provide consistent characters from any angle and with any facial features represented within the training dataset (20-60 images is typical).
Wired for Sound
For audio, HunyuanCustom leverages the LatentSync system (notoriously hard for hobbyists to establish and get good results from) for obtaining lip movements which can be matched to audio and text that the user supplies:
On the time of writing, there are not any English-language examples, but these seem like slightly good – the more so if the strategy of making them is easily-installable and accessible.
Editing Existing Video
The brand new system offers what seem like very impressive results for video-to-video (V2V, or Vid2Vid) editing, wherein a segment of an existing (real) video is masked off and intelligently replaced by a subject given in a single reference image. Below is an example from the supplementary materials site:
As we are able to see, and as is standard in a vid2vid scenario, the is to some extent altered by the method, though most altered within the targeted region, i.e., the plush toy. Presumably pipelines might be developed to create such transformations under a garbage matte approach that leaves nearly all of the video content equivalent to the unique. That is what Adobe Firefly does under the hood, and does quite well – but it surely is an under-studied process within the FOSS generative scene.
That said, a lot of the alternative examples provided do a greater job of targeting these integrations, as we are able to see within the assembled compilation below:
A Recent Start?
This initiative is a development of the Hunyuan Video project, not a tough pivot away from that development stream. The project’s enhancements are introduced as discrete architectural insertions slightly than sweeping structural changes, aiming to permit the model to keep up identity fidelity across frames without counting on fine-tuning, as with LoRA or textual inversion approaches.
To be clear, subsequently, HunyuanCustom will not be trained from scratch, but slightly is a fine-tuning of the December 2024 HunyuanVideo foundation model.
Those that have developed HunyuanVideo LoRAs may wonder if they’ll still work with this recent edition, or whether they’ll need to reinvent the LoRA wheel yet again in the event that they want more customization capabilities than are built into this recent release.
Usually, a heavily fine-tuned release of a hyperscale model alters the model weights enough that LoRAs made for the sooner model is not going to work properly, or in any respect, with the newly-refined model.
Sometimes, nonetheless, a fine-tune’s popularity can challenge its origins: one example of a fine-tune becoming an efficient , with a dedicated ecosystem and followers of its own, is the Pony Diffusion tuning of Stable Diffusion XL (SDXL). Pony currently has 592,000+ downloads on the ever-changing CivitAI domain, with an enormous range of LoRAs which have used Pony (and never SDXL) as the bottom model, and which require Pony at inference time.
Releasing
The project page for the recent paper (which is titled ) features links to a GitHub site that, as I write, just became functional, and appears to contain all code and mandatory weights for local implementation, along with a proposed timeline (where the one vital thing yet to return is ComfyUI integration).
On the time of writing, the project’s Hugging Face presence continues to be a 404. There may be, nonetheless, an API-based version of where one can apparently demo the system, as long as you’ll be able to provide a WeChat scan code.
I even have rarely seen such an elaborate and extensive usage of such a wide selection of projects in a single assembly, as is obvious in HunyuanCustom – and presumably among the licenses would in any case oblige a full release.
Two models are announced on the GitHub page: a 720px1280px version requiring 8)GB of GPU Peak Memory, and a 512px896px version requiring 60GB of GPU Peak Memory.
The repository states – and iterates that the system has only been tested to this point on Linux.
The sooner Hunyuan Video model has, since official release, been quantized right down to sizes where it may well be run on lower than 24GB of VRAM, and it seems reasonable to assume that the brand new model will likewise be adapted into more consumer-friendly forms by the community, and that it is going to quickly be adapted to be used on Windows systems too.
As a consequence of time constraints and the overwhelming amount of knowledge accompanying this release, we are able to only take a broader, slightly than in-depth have a look at this release. Nonetheless, let’s pop the hood on HunyuanCustom just a little.
A Take a look at the Paper
The info pipeline for HunyuanCustom, apparently compliant with the GDPR framework, incorporates each synthesized and open-source video datasets, including OpenHumanVid, with eight core categories represented: , , , , , , , and .
Source: https://arxiv.org/pdf/2505.04512
Initial filtering begins with PySceneDetect, which segments videos into single-shot clips. TextBPN-Plus-Plus is then used to remove videos containing excessive on-screen text, subtitles, watermarks, or logos.
To handle inconsistencies in resolution and duration, clips are standardized to 5 seconds in length and resized to 512 or 720 pixels on the short side. Aesthetic filtering is handled using Koala-36M, with a custom threshold of 0.06 applied for the custom dataset curated by the brand new paper’s researchers.
The topic extraction process combines the Qwen7B Large Language Model (LLM), the YOLO11X object recognition framework, and the favored InsightFace architecture, to discover and validate human identities.
For non-human subjects, QwenVL and Grounded SAM 2 are used to extract relevant bounding boxes, that are discarded if too small.

Source: https://github.com/IDEA-Research/Grounded-SAM-2
Multi-subject extraction utilizes Florence2 for bounding box annotation, and Grounded SAM 2 for segmentation, followed by clustering and temporal segmentation of coaching frames.
The processed clips are further enhanced via annotation, using a proprietary structured-labeling system developed by the Hunyuan team, and which furnishes layered metadata akin to descriptions and camera motion cues.
Mask augmentation strategies, including conversion to bounding boxes, were applied during training to scale back overfitting and make sure the model adapts to diverse object shapes.
Audio data was synchronized using the aforementioned LatentSync, and clips discarded if synchronization scores fall below a minimum threshold.
The blind image quality assessment framework HyperIQA was used to exclude videos scoring under 40 (on HyperIQA’s bespoke scale). Valid audio tracks were then processed with Whisper to extract features for downstream tasks.
The authors incorporate the LLaVA language assistant model through the annotation phase, and so they emphasize the central position that this framework has in HunyuanCustom. LLaVA is used to generate image captions and assist in aligning visual content with text prompts, supporting the development of a coherent training signal across modalities:
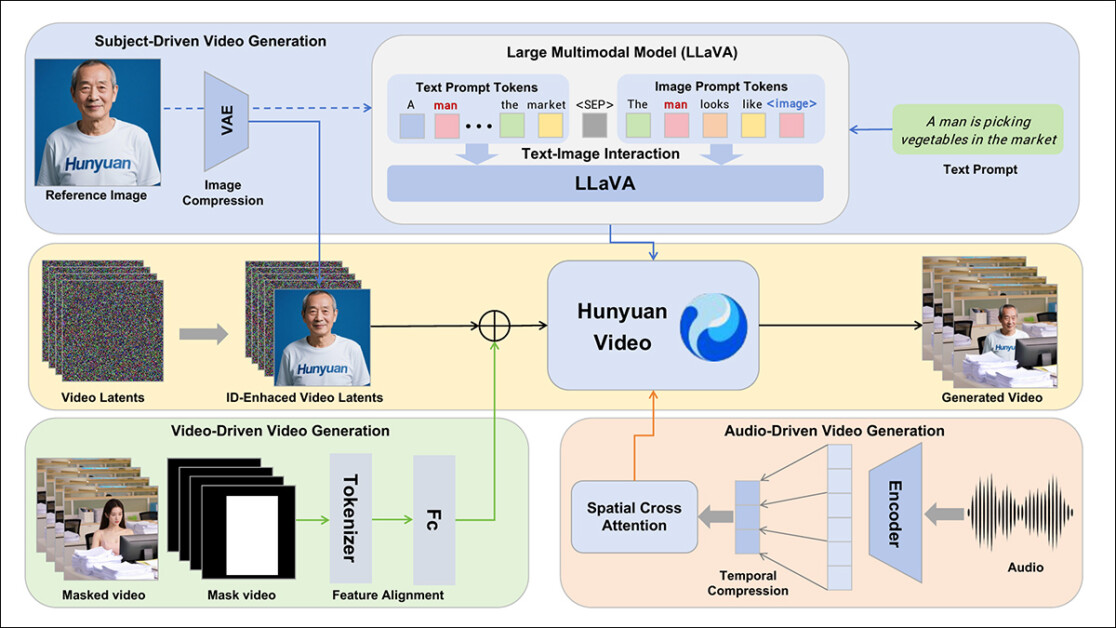
By leveraging LLaVA’s vision-language alignment capabilities, the pipeline gains a further layer of semantic consistency between visual elements and their textual descriptions – especially precious in multi-subject or complex-scene scenarios.
Custom Video
To permit video generation based on a reference image and a prompt, the 2 modules centered around LLaVA were created, first adapting the input structure of HunyuanVideo in order that it could accept a picture together with text.
This involved formatting the prompt in a way that embeds the image directly or tags it with a brief identity description. A separator token was used to stop the image embedding from overwhelming the prompt content.
Since LLaVA’s visual encoder tends to compress or discard fine-grained spatial details through the alignment of image and text features (particularly when translating a single reference image right into a general semantic embedding), an was incorporated. Since nearly all video latent diffusion models have some difficulty maintaining an identity without an LoRA, even in a five-second clip, the performance of this module in community testing may prove significant.
In any case, the reference image is then resized and encoded using the causal 3D-VAE from the unique HunyuanVideo model, and its latent inserted into the video latent across the temporal axis, with a spatial offset applied to forestall the image from being directly reproduced within the output, while still guiding generation.
The model was trained using Flow Matching, with noise samples drawn from a logit-normal distribution – and the network was trained to get well the proper video from these noisy latents. LLaVA and the video generator were each fine-tuned together in order that the image and prompt could guide the output more fluently and keep the topic identity consistent.
For multi-subject prompts, each image-text pair was embedded individually and assigned a definite temporal position, allowing identities to be distinguished, and supporting the generation of scenes involving interacting subjects.
Sound and Vision
HunyuanCustom conditions audio/speech generation using each user-input audio and a text prompt, allowing characters to talk inside scenes that reflect the described setting.
To support this, an Identity-disentangled AudioNet module introduces audio features without disrupting the identity signals embedded from the reference image and prompt. These features are aligned with the compressed video timeline, divided into frame-level segments, and injected using a spatial cross-attention mechanism that keeps each frame isolated, preserving subject consistency and avoiding temporal interference.
A second temporal injection module provides finer control over timing and motion, working in tandem with AudioNet, mapping audio features to specific regions of the latent sequence, and using a Multi-Layer Perceptron (MLP) to convert them into token-wise motion offsets. This permits gestures and facial movement to follow the rhythm and emphasis of the spoken input with greater precision.
HunyuanCustom allows subjects in existing videos to be edited directly, replacing or inserting people or objects right into a scene without having to rebuild all the clip from scratch. This makes it useful for tasks that involve altering appearance or motion in a targeted way.
To facilitate efficient subject-replacement in existing videos, the brand new system avoids the resource-intensive approach of recent methods akin to the currently-popular VACE, or those who merge entire video sequences together, favoring as a substitute the compression of a reference video using the pretrained causal 3D-VAE – aligning it with the generation pipeline’s internal video latents, after which adding the 2 together. This keeps the method relatively lightweight, while still allowing external video content to guide the output.
A small neural network handles the alignment between the clean input video and the noisy latents utilized in generation. The system tests two ways of injecting this information: merging the 2 sets of features before compressing them again; and adding the features frame by frame. The second method works higher, the authors found, and avoids quality loss while keeping the computational load unchanged.
Data and Tests
In tests, the metrics used were: the identity consistency module in ArcFace, which extracts facial embeddings from each the reference image and every frame of the generated video, after which calculates the typical cosine similarity between them; , via sending YOLO11x segments to Dino 2 for comparison; CLIP-B, text-video alignment, which measures similarity between the prompt and the generated video; CLIP-B again, to calculate similarity between each frame and each its neighboring frames and the primary frame, in addition to temporal consistency; and , as defined by VBench.
As indicated earlier, the baseline closed source competitors were Hailuo; Vidu 2.0; Kling (1.6); and Pika. The competing FOSS frameworks were VACE and SkyReels-A2.
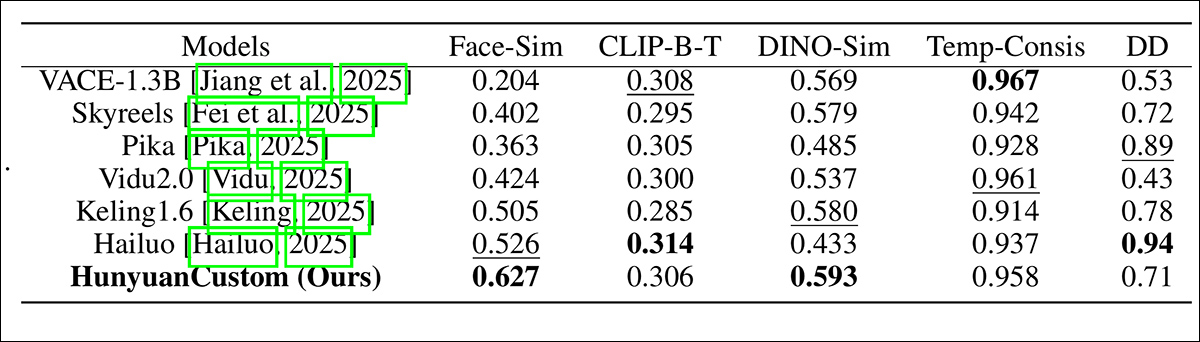
Of those results, the authors state:
Though the project site is saturated with comparison videos (the layout of which seems to have been designed for website aesthetics slightly than easy comparison), it doesn’t currently feature a video equivalent of the static results crammed together within the PDF, in regard to the initial qualitative tests. Though I include it here, I encourage the reader to make a detailed examination of the videos on the project site, as they offer a greater impression of the outcomes:
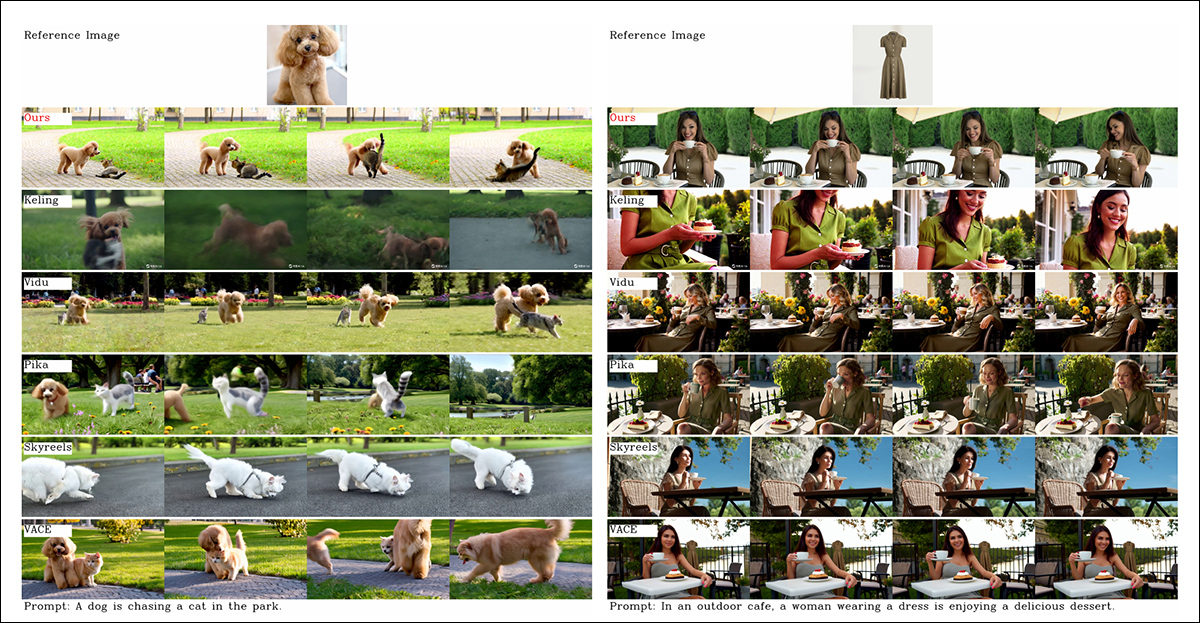
The authors comment here:
The authors further comment that Pika performs poorly by way of temporal consistency, introducing subtitle artifacts (effects from poor data curation, where text elements in video clips have been allowed to pollute the core concepts).
Hailuo maintains facial identity, they state, but fails to preserve full-body consistency. Amongst open-source methods, VACE, the researchers assert, is unable to keep up identity consistency, whereas they contend that HunyuanCustom produces videos with strong identity preservation, while retaining quality and variety.
Next, tests were conducted for , against the identical contenders. As within the previous example, the flattened PDF results should not print equivalents of videos available on the project site, but are unique among the many results presented:

The paper states:
An extra experiment was ‘virtual human commercial’, wherein the frameworks were tasked to integrate a product with an individual:

For this round, the authors state:
One area where video results would have been very useful was the qualitative round for audio-driven subject customization, where the character speaks the corresponding audio from a text-described scene and posture.
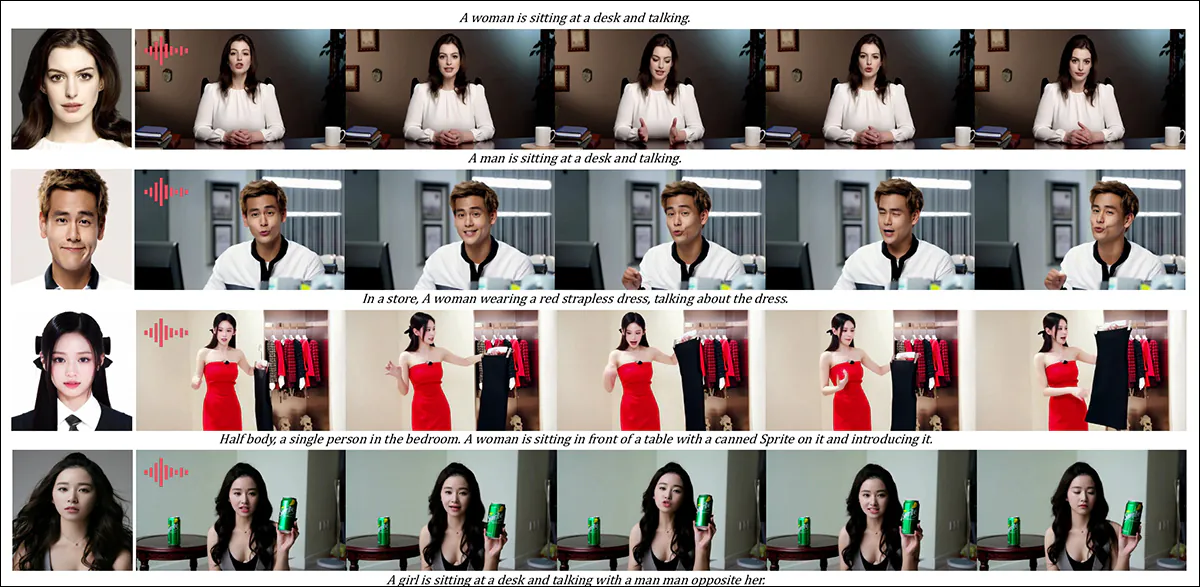
The authors assert:
Further tests (please see PDF for all details) included a round pitting the brand new system against VACE and Kling 1.6 for video subject substitute:

Of those, the last tests presented in the brand new paper, the researchers opine:
Conclusion
That is an enchanting release, not least since it addresses something that the ever-discontent hobbyist scene has been complaining about more recently – the shortage of lip-sync, in order that the increased realism capable in systems akin to Hunyuan Video and Wan 2.1 is likely to be given a brand new dimension of authenticity.
Though the layout of nearly all of the comparative video examples on the project site makes it slightly difficult to check HunyuanCustom’s capabilities against prior contenders, it have to be noted that very, only a few projects within the video synthesis space have the courage to pit themselves in tests against Kling, the business video diffusion API which is all the time hovering at or near the highest of the leader-boards; Tencent appears to have made headway against this incumbent in a slightly impressive manner.
*