
A collaboration between researchers in the USA and Canada has found that giant language models (LLMs) comparable to ChatGPT struggle to breed historical idioms without extensive pretraining – a costly and labor-intensive process that lies beyond the technique of most academic or entertainment initiatives, making projects comparable to completing Charles Dickens’s final, unfinished novel effectively through AI an unlikely proposition.
The researchers explored a spread of methods for generating text that historically accurate, starting with easy prompting using early twentieth-century prose, and moving to fine-tuning a business model on a small collection of books from that period.
In addition they compared the outcomes to a separate model that had been trained entirely on books published between 1880 and 1914.
In the primary of the tests, instructing ChatGPT-4o to mimic language produced quite different results from those of the smaller GPT2-based model that had been fantastic‑tuned on literature from the period:
. Source: https://arxiv.org/pdf/2505.00030
Though fine-tuning brings the output closer to the unique style, human readers were still ceaselessly capable of detect traces of contemporary language or ideas, suggesting that even carefully-adjusted models proceed to reflect the influence of their contemporary training data.
The researchers arrive on the frustrating conclusion that there aren’t any economical short-cuts towards the generation of machine-produced idiomatically-correct historical text or dialogue. In addition they conjecture that the challenge itself is perhaps ill-posed:
The recent study is titled , and comes from three researchers across University of Illinois, University of British Columbia, and Cornell University.
Complete Disaster
Initially, in a three-part research approach, the authors tested whether modern language models may very well be nudged into mimicking historical language through easy prompting. Using real excerpts from books published between 1905 and 1914, they asked ChatGPT‑4o to proceed these passages in the identical idiom.
The unique period text was:
To judge whether the generated text matched the intended historical style, and conscious that folks are usually not especially expert at guessing the date that a text was written, the researchers fantastic‑tuned a RoBERTa model to estimate publication dates, using a subset of the Corpus of Historical American English, covering material from 1810 to 2009.
The RoBERTa classifier was then used to evaluate continuations produced by ChatGPT‑4o, which had been prompted with real passages from books published between 1905 and 1914.
The system prompt (i.e., contextual instructions to ChatGPT about approach the duty) was:
Despite each one-shot and 20-shot prompting, ChatGPT-4o’s outputs consistently skewed toward a Twenty first-century stylistic register.
The instance given within the paper features one in every of ChatGPT-4o’s blog-like attempts to proceed the actual period text about photography:
As we will easily see, this generic, Wiki-style text doesn’t match the prolix and elaborate variety of the unique period text. Further, it does probably not proceed from where the unique content leaves off, but launches right into a tangential, abstract musing on one in every of the sub-topics.
The team also tested GPT‑1914, a smaller GPT‑2–class model trained from scratch on 26.5 billion tokens of literature dated between 1880 and 1914.
Though its output was less coherent than that of ChatGPT‑4o, it was more consistent with the variety of the source period. The only example provided within the paper, again as a completion of the real-world period text on photography, reads:
Since even the actual and original material is arcane and quite difficult to follow, it is difficult to know the extent to which GPT-1914 has accurately picked up from the unique; however the output actually sounds more period-authentic.
Nonetheless, the authors concluded from this experiment that straightforward prompting does little to beat the contemporary biases of a giant pretrained model comparable to ChatGPT-4o.
The Plot Thickens
To measure how closely the model outputs resembled authentic historical writing, the researchers used a statistical classifier to estimate the likely publication date of every text sample. They then visualized the outcomes using a kernel density plot, which shows where the model thinks each passage falls on a historical timeline.
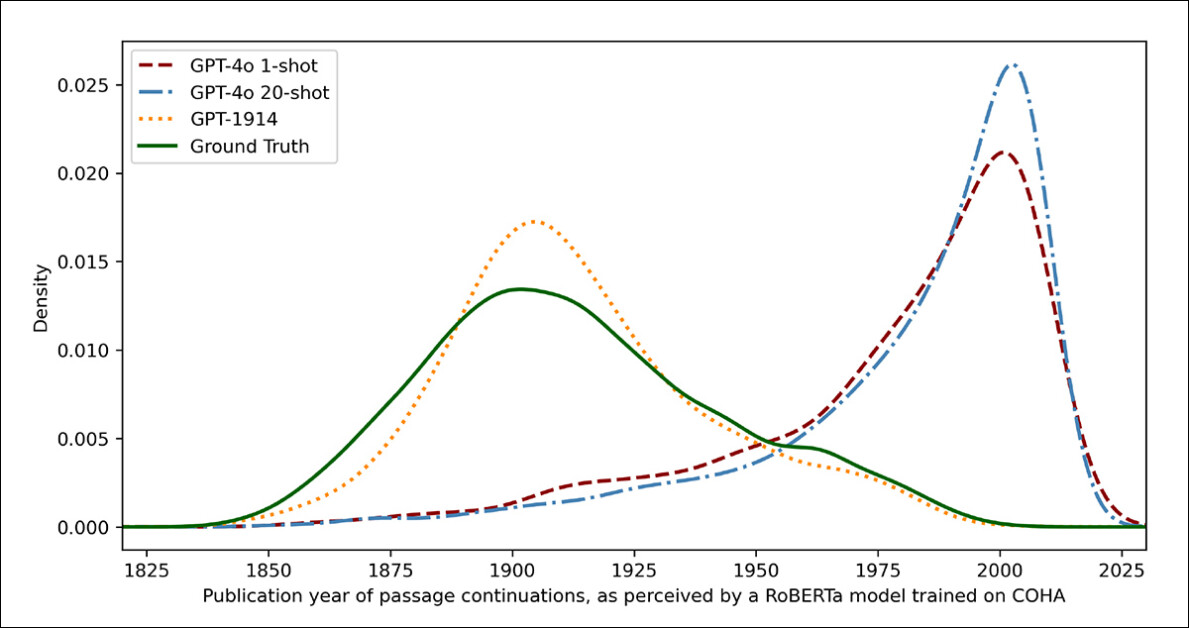
The fantastic‑tuned RoBERTa model used for this task, the authors note, isn’t flawless, but was nonetheless able to spotlight general stylistic trends. Passages written by GPT‑1914, the model trained entirely on period literature, clustered across the early twentieth century – just like the unique source material.
Against this, ChatGPT-4o’s outputs, even when prompted with multiple historical examples, tended to resemble twenty‑first‑century writing, reflecting the info it was originally trained on.
The researchers quantified this mismatch using Jensen-Shannon divergence, a measure of how different two probability distributions are. GPT‑1914 scored an in depth 0.006 in comparison with real historical text, while ChatGPT‑4o’s one-shot and 20-shot outputs showed much wider gaps, at 0.310 and 0.350 respectively.
The authors argue that these findings indicate prompting alone, even with multiple examples, isn’t a reliable solution to produce text that convincingly simulates a historical style.
Completing the Passage
The paper then investigates whether fine-tuning might produce a superior result, since this process involves directly affecting the usable weights of a model by ‘continuing’ its training on user-specified data – a process that may affect the unique core functionality of the model, but significantly improve its performance on the domain that’s being ‘pushed’ into it or else emphasized during fine-training.
In the primary fine-tuning experiment, the team trained GPT‑4o‑mini on around two thousand passage-completion pairs drawn from books published between 1905 and 1914, with the aim of seeing whether a smaller-scale fine-tuning could shift the model’s outputs toward a more historically accurate style.
Using the identical RoBERTa-based classifier that acted as a judge in the sooner tests to estimate the stylistic ‘date’ of every output, the researchers found that in the brand new experiment, the fine-tuned model produced text closely aligned with the bottom truth.
Its stylistic divergence from the unique texts, measured by Jensen-Shannon divergence, dropped to 0.002, generally according to GPT‑1914:

Nonetheless, the researchers caution that this metric may only capture superficial features of historical style, and never deeper conceptual or factual anachronisms.
Human Touch
Finally, the researchers conducted human evaluation tests using 250 hand-selected passages from books published between 1905 and 1914, they usually observe that lots of these texts would likely be interpreted quite otherwise today than they were on the time of writing:
The researchers created short questions that every historical passage could plausibly answer, then fine-tuned GPT‑4o‑mini on these query–answer pairs. To strengthen the evaluation, they trained five separate versions of the model, every time holding out a unique portion of the info for testing.
They then produced responses using each the default versions of GPT-4o and GPT-4o‑mini, in addition to the fantastic‑tuned variants, each evaluated on the portion it had not seen during training.
Lost in Time
To evaluate how convincingly the models could imitate historical language, the researchers asked three expert annotators to review 120 AI-generated completions, and judge whether each seemed plausible for a author in 1914.
This direct evaluation approach proved more difficult than expected: although the annotators agreed on their assessments nearly eighty percent of the time, the imbalance of their judgments (with ‘plausible’ chosen twice as often as ‘not plausible’) meant that their actual level of agreement was only moderate, as measured by a Cohen’s kappa rating of 0.554.
The raters themselves described the duty as , often requiring additional research to guage whether an announcement aligned with what was known or believed in 1914.
Some passages raised difficult questions on tone and perspective – for instance, whether a response was appropriately limited in its worldview to reflect what would have been typical in 1914. This sort of judgment often hinged on the extent of (i.e., the tendency to view other cultures through the assumptions or biases of 1’s own).
On this context, the challenge was to choose whether a passage expressed simply enough cultural bias to appear historically plausible without sounding too modern, or too overtly offensive by today’s standards. The authors note that even for scholars acquainted with the period, it was difficult to attract a pointy line between language that felt historically accurate and language that reflected present-day ideas.
Nonetheless, the outcomes showed a transparent rating of the models, with the fine-tuned version of GPT‑4o‑mini judged most plausible overall:
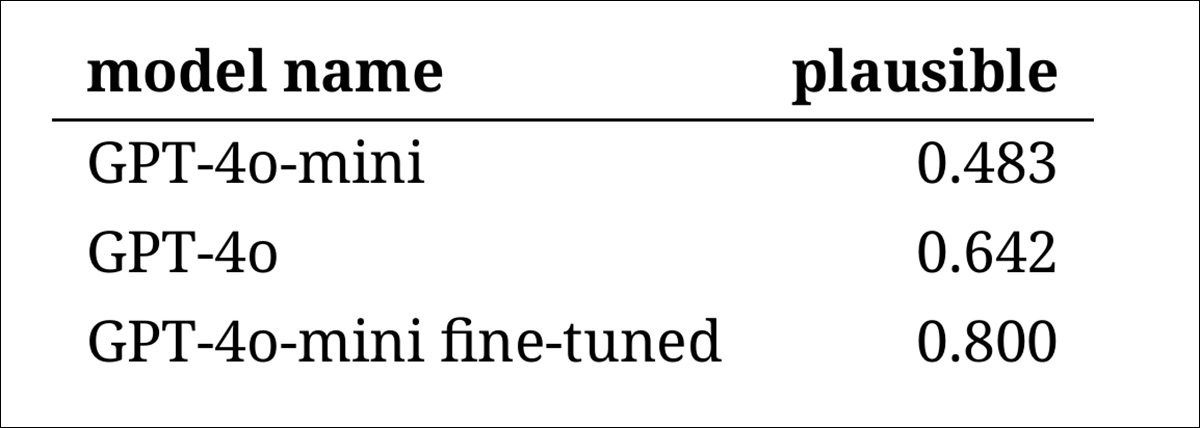
Whether this level of performance, rated in eighty percent of cases, is reliable enough for historical research stays unclear – particularly for the reason that study didn’t include a baseline measure of how often real period texts is perhaps misclassified.
Intruder Alert
Next got here an ‘intruder test’, wherein expert annotators were shown 4 anonymous passages answering the identical historical query. Three of the responses got here from language models, while one was an actual and real excerpt from an actual early twentieth-century source.
The duty was to discover which passage was the unique one, genuinely written in the course of the period.
This approach didn’t ask the annotators to rate plausibility directly, but reasonably measured how often the actual passage stood out from the AI-generated responses, in effect, testing whether the models could idiot readers into pondering their output was authentic.
The rating of the models matched the outcomes from the sooner judgment task: the fine-tuned version of GPT‑4o‑mini was probably the most convincing among the many models, but still fell wanting the actual thing.
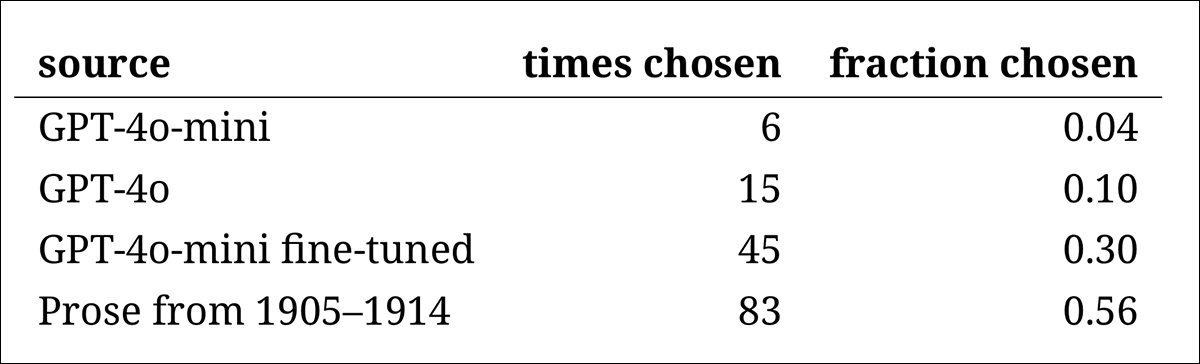
This test also served as a useful benchmark, since, with the real passage identified greater than half the time, the gap between authentic and artificial prose remained noticeable to human readers.
A statistical evaluation often known as McNemar’s test confirmed that the differences between the models were meaningful, except within the case of the 2 untuned versions (GPT‑4o and GPT‑4o‑mini), which performed similarly.
The Way forward for the Past
The authors found that prompting modern language models to adopt a historical voice didn’t reliably produce convincing results: fewer than two-thirds of the outputs were judged plausible by human readers, and even this figure likely overstates performance.
In lots of cases, the responses included explicit signals that the model was speaking from a present-day perspective – phrases comparable to or were common enough to look in as many as one-fifth of completions. Disclaimers of this type made it clear that the model was simulating history from the surface, reasonably than writing from inside it.
The authors state:
The authors conclude that while fine-tuning a business model on historical passages can produce stylistically convincing output at minimal cost, it doesn’t fully eliminate traces of contemporary perspective. Pretraining a model entirely on period material avoids anachronism but demands far greater resources, and ends in less fluent output.
Neither method offers a whole solution, and, for now, any try and simulate historical voices appears to involve a tradeoff between authenticity and coherence. The authors conclude that further research shall be needed to make clear how best to navigate that tension.
Conclusion
Perhaps some of the interesting inquiries to arise out of the brand new paper is that of authenticity. While they are usually not perfect tools, loss functions and metrics comparable to LPIPS and SSIM give computer vision researchers at the least a like-on-like methodology for evaluating against ground truth.
When generating recent text within the variety of a bygone era, against this, there isn’t a ground truth – only an try and inhabit a vanished cultural perspective. Attempting to reconstruct that mindset from literary traces is itself an act of quantization, since such traces are merely evidence, while the cultural consciousness from which they emerge stays beyond inference, and sure beyond imagination.
On a practical level too, the foundations of contemporary language models, shaped by present-day norms and data, risk to reinterpret or suppress ideas that may have appeared reasonable or unremarkable to an Edwardian reader, but which now register as (ceaselessly offensive) artifacts of prejudice, inequality or injustice.
One wonders, due to this fact, even when we could create such a colloquy, whether it won’t repel us.