
A brand new collaboration between University of California Merced and Adobe offers an advance on the state-of-the-art in – the much-studied task of ‘de-obscuring’ occluded or hidden parts of images of individuals, for purposes resembling virtual try-on, animation and photo-editing.
Source: https://liagm.github.io/CompleteMe/pdf/supp.pdf
The latest approach, titled , uses supplementary input images to ‘suggest’ to the system what content should replace the hidden or missing section of the human depiction (hence the applicability to fashion-based try-on frameworks):

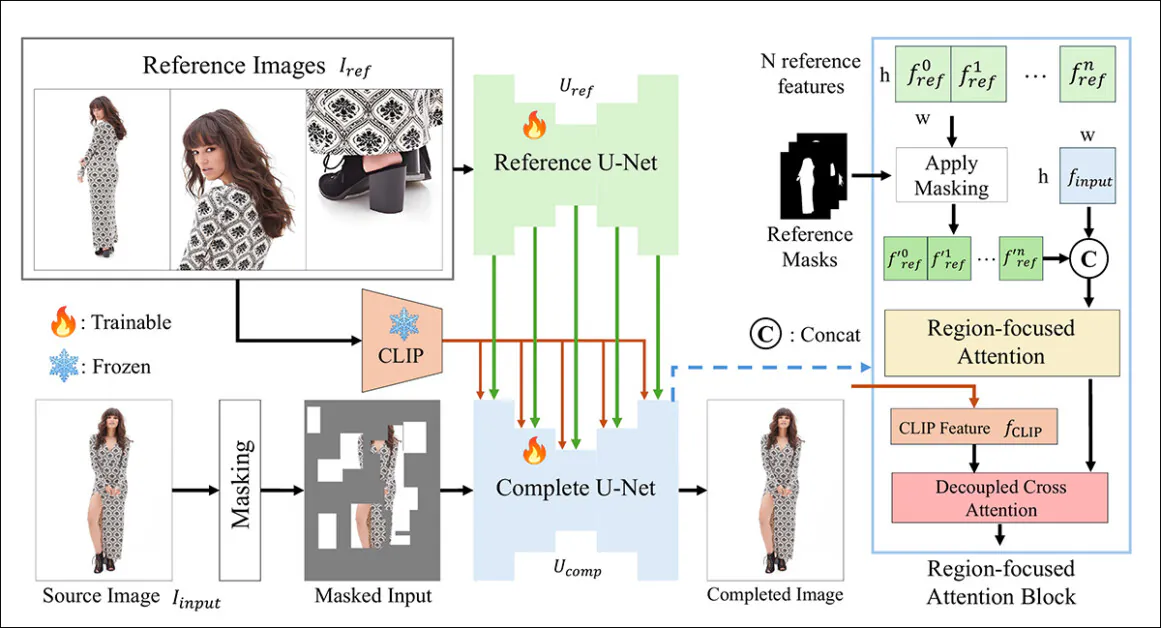
The brand new system uses a dual U-Net architecture and a (RFA) block that marshals resources to the pertinent area of the image restoration instance.
The researchers also offer a brand new and difficult benchmark system designed to guage reference-based completion tasks (since CompleteMe is an element of an existing and ongoing research strand in computer vision, albeit one which has had no benchmark schema until now).
In tests, and in a well-scaled user study, the brand new method got here out ahead in most metrics, and ahead overall. In certain cases, rival methods were utterly foxed by the reference-based approach:

The paper states:
Sadly, the project’s GitHub presence accommodates no code, nor guarantees any, and the initiative, which also has a modest project page, seems framed as a proprietary architecture.

Method
The CompleteMe framework is underpinned by a Reference U-Net, which handles the combination of the ancillary material into the method, and a cohesive U-Net, which accommodates a wider range of processes for obtaining the , as illustrated within the conceptual schema below:
Source: https://arxiv.org/pdf/2504.20042
The system first encodes the masked input image right into a latent representation. At the identical time, the Reference U-Net processes multiple reference images – each showing different body regions – to extract detailed spatial features.
These features go through a Region-focused Attention block embedded within the ‘complete’ U-Net, where they’re selectively masked using corresponding region masks, ensuring the model attends only to relevant areas within the reference images.
The masked features are then integrated with global CLIP-derived semantic features through decoupled cross-attention, allowing the model to reconstruct missing content with each nice detail and semantic coherence.
To boost realism and robustness, the input masking process combines random grid-based occlusions with human body shape masks, each applied with equal probability, increasing the complexity of the missing regions that the model must complete.
For Reference Only
Previous methods for reference-based image inpainting typically relied on encoders. Projects of this sort include CLIP itself, and DINOv2, each of which extract global features from reference images, but often lose the nice spatial details needed for accurate identity preservation.

Source: https://arxiv.org/pdf/2304.07193
CompleteMe addresses this aspect through a specialized Reference U-Net initialized from Stable Diffusion 1.5, but operating without the diffusion noise step*.
Each reference image, covering different body regions, is encoded into detailed latent features through this U-Net. Global semantic features are also extracted individually using CLIP, and each sets of features are cached for efficient use during attention-based integration. Thus, the system can accommodate multiple reference inputs flexibly, while preserving fine-grained appearance information.
Orchestration
The cohesive U-Net manages the ultimate stages of the completion process. Adapted from the inpainting variant of Stable Diffusion 1.5, it takes as input the masked source image in latent form, alongside detailed spatial features drawn from the reference images and global semantic features extracted by the CLIP encoder.
These various inputs are brought together through the RFA block, which plays a critical role in steering the model’s focus toward essentially the most relevant areas of the reference material.
Before entering the eye mechanism, the reference features are explicitly masked to remove unrelated regions after which concatenated with the latent representation of the source image, ensuring that spotlight is directed as precisely as possible.
To boost this integration, CompleteMe incorporates a decoupled cross-attention mechanism adapted from the IP-Adapter framework:

Source: https://ip-adapter.github.io/
This enables the model to process spatially detailed visual features and broader semantic context through separate attention streams, that are later combined, leading to a coherent reconstruction that, the authors contend, preserves each identity and fine-grained detail.
Benchmarking
Within the absence of an apposite dataset for reference-based human completion, the researchers have proposed their very own. The (unnamed) benchmark was constructed by curating select image pairs from the WPose dataset devised for Adobe Research’s 2023 UniHuman project.

Source: https://github.com/adobe-research/UniHuman?tab=readme-ov-file#data-prep
The researchers manually drew source masks to point the inpainting areas, ultimately obtaining 417 tripartite image groups constituting a source image, mask, and reference image.

The authors used the LLaVA Large Language Model (LLM) to generate text prompts describing the source images.
Metrics used were more extensive than usual; besides the standard Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS, on this case for evaluating masked regions), the researchers used DINO for similarity scores; DreamSim for generation result evaluation; and CLIP.
Data and Tests
To check the work, the authors utilized each the default Stable Diffusion V1.5 model and the 1.5 inpainting model. The system’s image encoder used the CLIP Vision model, along with projection layers – modest neural networks that reshape or align the CLIP outputs to match the inner feature dimensions utilized by the model.
Training took place for 30,000 iterations over eight NVIDIA A100† GPUs, supervised by Mean Squared Error (MSE) loss, at a batch size of 64 and a learning rate of two×10-5. Various elements were randomly dropped throughout training, to stop the system overfitting on the information.
The dataset was modified from the Parts to Whole dataset, itself based on the DeepFashion-MultiModal dataset.

Source: https://huanngzh.github.io/Parts2Whole/
The authors state:
Rival prior methods tested were Large occluded human image completion (LOHC) and the plug-and-play image inpainting model BrushNet; reference-based models tested were Paint-by-Example; AnyDoor; LeftRefill; and MimicBrush.
The authors began with a quantitative comparison on the previously-stated metrics:
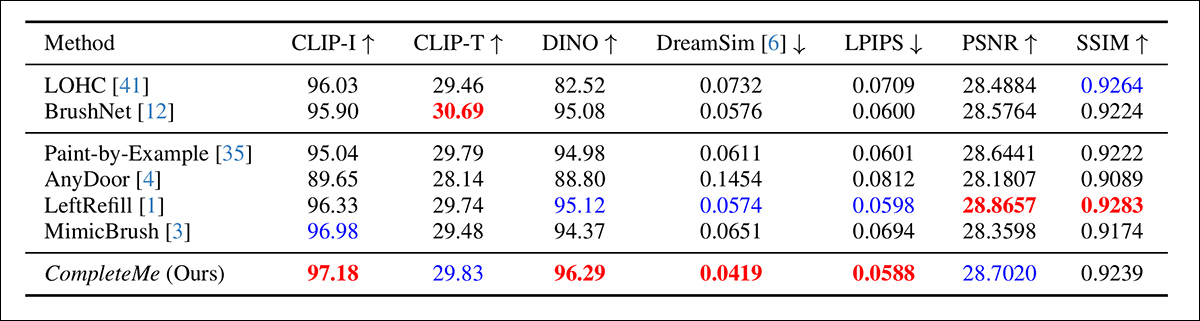
Regarding the quantitative evaluation, the authors note that CompleteMe achieves the very best scores on most perceptual metrics, including CLIP-I, DINO, DreamSim, and LPIPS, that are intended to capture semantic alignment and appearance fidelity between the output and the reference image.
Nonetheless, the model doesn’t outperform all baselines across the board. Notably, BrushNet scores highest on CLIP-T, LeftRefill leads in SSIM and PSNR, and MimicBrush barely outperforms on CLIP-I.
While CompleteMe shows consistently strong results overall, the performance differences are modest in some cases, and certain metrics remain led by competing prior methods. Perhaps not unfairly, the authors frame these results as evidence of CompleteMe’s balanced strength across each structural and perceptual dimensions.
Illustrations for the qualitative tests undertaken for the study are far too quite a few to breed here, and we refer the reader not only to the source paper, but to the extensive supplementary PDF, which accommodates many additional qualitative examples.
We highlight the first qualitative examples presented within the foremost paper, together with a number of additional cases drawn from the supplementary image pool introduced earlier in this text:

Of the qualitative results displayed above, the authors comment:
A second comparison, a part of which is shown below, focuses on the 4 reference-based methods Paint-by-Example, AnyDoor, LeftRefill, and MimicBrush. Here just one reference image and a text prompt were provided.
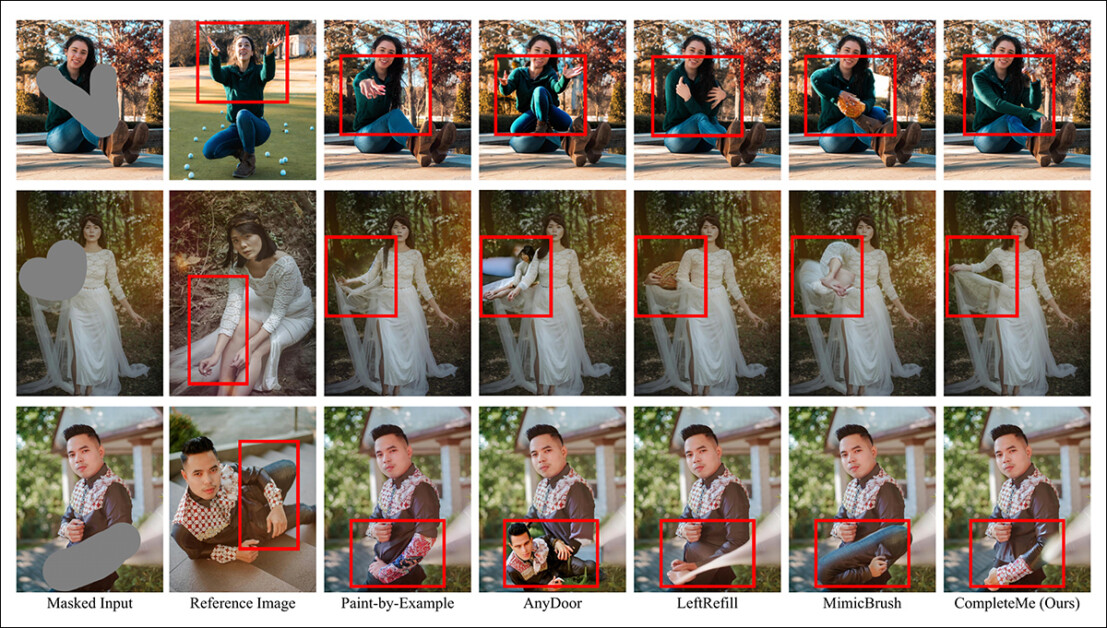
The authors state:
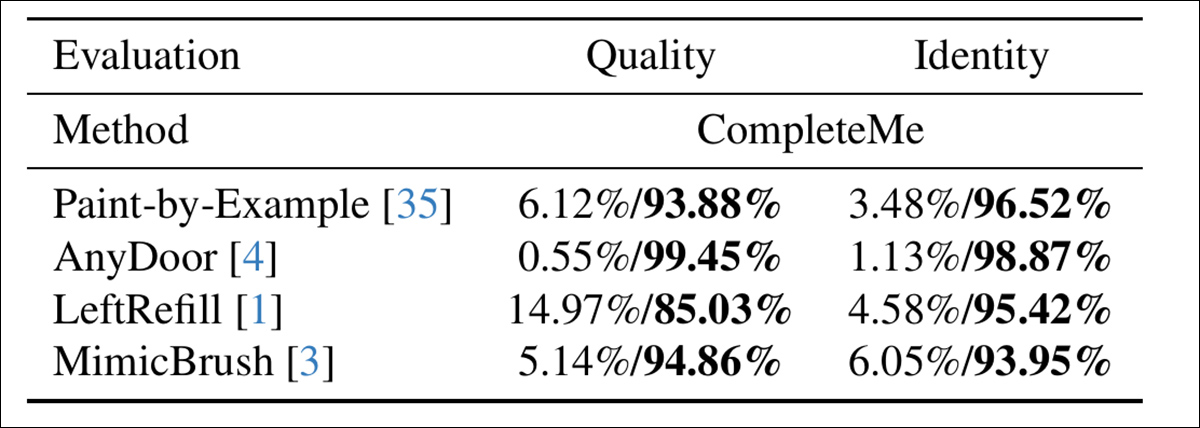
To evaluate how well the models align with human perception, the authors conducted a user study involving 15 annotators and a pair of,895 sample pairs. Each pair compared the output of CompleteMe against one in all 4 reference-based baselines: Paint-by-Example, AnyDoor, LeftRefill, or MimicBrush.
Annotators evaluated each result based on the visual quality of the finished region and the extent to which it preserved identity features from the reference – and here, evaluating overall quality and identity, CompleteMe obtained a more definitive result:
Conclusion
If anything, the qualitative leads to this study are undermined by their sheer volume, since close examination indicates that the brand new system is a handiest entry on this relatively area of interest but hotly-pursued area of neural image editing.
Nonetheless, it takes just a little extra care and zooming-in on the unique PDF to understand how well the system adapts the reference material to the occluded area compared (in nearly all cases) to prior methods.

*
†