
whether GenAI is just hype or external noise. I also thought this was hype, and I could sit this one out until the dust cleared. Oh, boy, was I flawed. GenAI has real-world applications. It also generates revenue for firms, so we expect firms to speculate heavily in research. Each time a technology disrupts something, the method generally moves through the next phases: denial, anger, and acceptance. The identical thing happened when computers were introduced. If we work within the software or hardware field, we’d need to make use of GenAI sooner or later.
In this text, I cover how you can power your application with large Language Models (LLMs) and discuss the challenges I faced while establishing LLMs. Let’s start.
1. Start by defining your use case clearly
Before jumping onto LLM, we must always ask ourselves some questions
Narrow down your use case and document it. In my case, I used to be working on an information platform as a service. We had tons of data on wikis, Slack, team channels, etc. We wanted a chatbot to read this information and answer questions on our behalf. The chatbot would answer customer questions and requests on our behalf, and if customers were still unhappy, they might be routed to an Engineer.
2. Select your model
You will have two options: Train your model from scratch or use a pre-trained model and construct on top of it. The latter would work typically unless you will have a specific use case. Training your model from scratch would require massive computing power, significant engineering efforts, and costs, amongst other things. Now, the following query is, which pre-trained model should I select? You possibly can select a model based in your use case. 1B parameter model has basic knowledge and pattern matching. Use cases may be restaurant reviews. The 10B parameter model has excellent knowledge and may follow instructions like a food order chatbot. A 100B+ parameters model has wealthy world knowledge and sophisticated reasoning. This may be used as a brainstorming partner. There are a lot of models available, comparable to Llama and ChatGPT. Once you will have a model in place, you possibly can expand on the model.
3. Enhance the model as per your data
Once you will have a model in place, you possibly can expand on the model. The LLM model is trained on generally available data. We wish to coach it on our data. Our model needs more context to supply answers. Let’s assume we wish to construct a restaurant chatbot that answers customer questions. The model doesn’t know information particular to your restaurant. So, we wish to supply the model some context. There are a lot of ways we are able to achieve this. Let’s dive into a few of them.
Prompt Engineering
Prompt engineering involves augmenting the input prompt with more context during inference time. You provide context in your input quote itself. That is the simplest to do and has no enhancements. But this comes with its disadvantages. You can’t give a big context contained in the prompt. There may be a limit to the context prompt. Also, you can not expect the user to at all times provide full context. The context may be extensive. This can be a quick and simple solution, nevertheless it has several limitations. Here’s a sample prompt engineering.
“Classify this review
I really like the movie
Sentiment: PositiveClassify this review
I hated the movie.
Sentiment: NegativeClassify the movie
The ending was exciting”
Reinforced Learning With Human Feedback (RLHF)

RLHF is one in every of the most-used methods for integrating LLM into an application. You provide some contextual data for the model to learn from. Here is the flow it follows: The model takes an motion from the motion space and observes the state change within the environment in consequence of that motion. The reward model generated a reward rating based on the output. The model updates its weight accordingly to maximise the reward and learns iteratively. For example, in LLM, motion is the following word that the LLM generates, and the motion space is the dictionary of all possible words and vocabulary. The environment is the text context; the State is the present text within the context window.
The above explanation is more like a textbook explanation. Let’s have a take a look at a real-life example. You would like your chatbot to reply questions regarding your wiki documents. Now, you select a pre-trained model like ChatGPT. Your wikis might be your context data. You possibly can leverage the langchain library to perform RAG. You possibly can Here’s a sample code in Python
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
import os
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = "your-openai-key-here"
# Step 1: Load Wikipedia documents
query = "Alan Turing"
wiki_loader = WikipediaLoader(query=query, load_max_docs=3)
wiki_docs = wiki_loader.load()
# Step 2: Split the text into manageable chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
split_docs = splitter.split_documents(wiki_docs)
# Step 3: Embed the chunks into vectors
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(split_docs, embeddings)
# Step 4: Create a retriever
retriever = vector_store.as_retriever(search_type="similarity", search_kwargs={"k": 3})
# Step 5: Create a RetrievalQA chain
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # You too can try "map_reduce" or "refine"
retriever=retriever,
return_source_documents=True,
)
# Step 6: Ask an issue
query = "What did Alan Turing contribute to computer science?"
response = qa_chain(query)
# Print the reply
print("Answer:", response["result"])
print("n--- Sources ---")
for doc in response["source_documents"]:
print(doc.metadata)4. Evaluate your model
Now, you will have added RAG to your model. How do you check in case your model is behaving appropriately? This is just not a code where you give some input parameters and receive a hard and fast output, which you’ll be able to test against. Since this can be a language-based communication, there may be multiple correct answers. But what you possibly can know of course is whether or not the reply is inaccurate. There are a lot of metrics you possibly can test your model against.
Evaluate manually
You possibly can continually evaluate your model manually. For example, we had integrated a Slack chatbot that was enhanced with RAG using our wikis and Jira. Once we added the chatbot to the Slack channel, we initially shadowed its responses. The clients couldn’t view the responses. Once we gained confidence, we made the chatbot publicly visible to the clients. We evaluated its response manually. But this can be a quick and vague approach. You can’t gain confidence from such manual testing. So, the answer is to check against some benchmark, comparable to ROUGE.
Evaluate with ROUGE rating.
ROUGE metrics are used for text summarization. Rouge metrics compare the generated summary with reference summaries using different ROUGE metrics. Rouge metrics evaluate the model using recall, precision, and F1 scores. ROUGE metrics are available in various types, and poor completion can still end in rating; hence, we confer with different ROUGE metrics. For some context, a unigram is a single word; a bigram is 2 words; and an n-gram is N words.
For instance,
Reference: “It’s cold outside.”
Generated output: “It is vitally cold outside.”
Reduce hassle with the external benchmark
The ROUGE Rating is used to grasp how model evaluation works. Other benchmarks exist, just like the BLEU Rating. Nevertheless, we cannot practically construct the dataset to guage our model. We will leverage external libraries to benchmark our models. Essentially the most commonly used are the GLUE Benchmark and SuperGLUE Benchmark.
5. Optimize and deploy your model
This step may not be crucial, but reducing computing costs and getting faster results is at all times good. Once your model is prepared, you possibly can optimize it to enhance performance and reduce memory requirements. We are going to touch on a number of concepts that require more engineering efforts, knowledge, time, and costs. These concepts will make it easier to get acquainted with some techniques.
Quantization of the weights
Models have parameters, internal variables inside a model which are learned from data during training and whose values determine how the model makes predictions. 1 parameter often requires 24 bytes of processor memory. So, when you select 1B, parameters would require 24 GB of processor memory. Quantization converts the model weights from higher-precision floating-point numbers to lower-precision floating-point numbers for efficient storage. Changing the storage precision can significantly affect the variety of bytes required to store a single value of the load. The table below illustrates different precisions for storing weights.
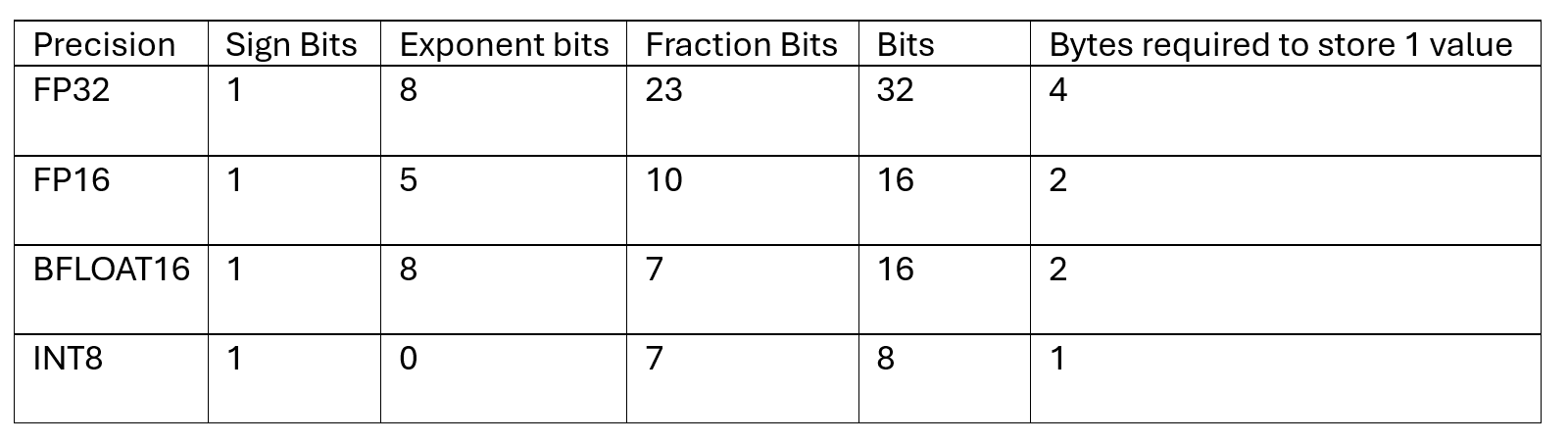
Pruning
Pruning involves removing weights in a model which are less vital and have little impact, comparable to weights equal to or near zero. Some techniques of pruning are
a. Full model retraining
b. PEFT like LoRA
c. Post-training.
Conclusion
To conclude, you possibly can select a pre-trained model, comparable to ChatGPT or FLAN-T5, and construct on top of it. Constructing your pre-trained model requires expertise, resources, time, and budget. You possibly can fine-tune it as per your use case if needed. Then, you should use your LLM to power applications and tailor them to your application use case using techniques like RAG. You possibly can evaluate your model against some benchmarks to see if it behaves appropriately. You possibly can then deploy your model.