
Byte Dance unveiled a reinforcement learning (RL) method that more effectively performs complex reasoning ability than ‘Deep Chic-R1’. Through this, R1 has exceeded the mathematical performance of R1, and it has been released specifically, especially the small print that didn’t even reveal the deep chic.
Byte Dance and Tsinghua University researchers are recent RL approaches that improve the reasoning ability of a big language model (LLM) on the twenty first (local time)DAPO(Decoupled Clip and Dynamic Sampling Policy Optimisation)The paper on the web archive was published.
Recently, RL has been used as a core technology that pulls the complex reasoning ability of LLM.
DAPO is an RL algorithm that improves the Deep Chic’s RL technique, ‘GRPO’, which helps LLM to perform complex reasoning ability, equivalent to self-verification and repetitive refinement. GRPO helps models compare various behaviors and update the group’s statement.
Nonetheless, the researchers identified that open AI or Deep Chic didn’t disclose detailed technologies, which is difficult to breed RL learning results. Actually, the model was improved with GRPO, however the AIME benchmark said it was 17 points behind Deep Chic. In other words, it’s identified that “vital training details could have been omitted within the R1 paper.”
Thus, the researchers revealed the 4 core techniques of DAPO, which successfully implement LLM RL, as full open source.
Existing RL models use ‘clipping’ technology to forestall the worth from changing an excessive amount of. Nonetheless, on this process, the model can only give the reply that the model is simply too convinced, and there could also be an issue that reduces diversity. DAPO, alternatively, sets the upper and lower limit of clipping individually to create more diverse tokens and helps the model to explore more broadly.
In lots of RL courses, unnecessary prompts are also wasteful of computational resources. Particularly, if a prompt that doesn’t affect learning is included, it’s less efficient. DAPO filters out such effective prompt in order that each batch consists of meaningful data and helps the model to learn faster.
As well as, the present method treats your complete response as a sample, but DAPO divides the response right into a token unit and assigns ‘gradient’ to every token. In this manner, the long reasoning process is more weighted and effectively works for complex multi -level problems.
As well as, the present model gives excessive penalties for long responses, but DAPO dynamically adjusts the penalty to forestall sudden disappearance of useful information and make learning more stable.
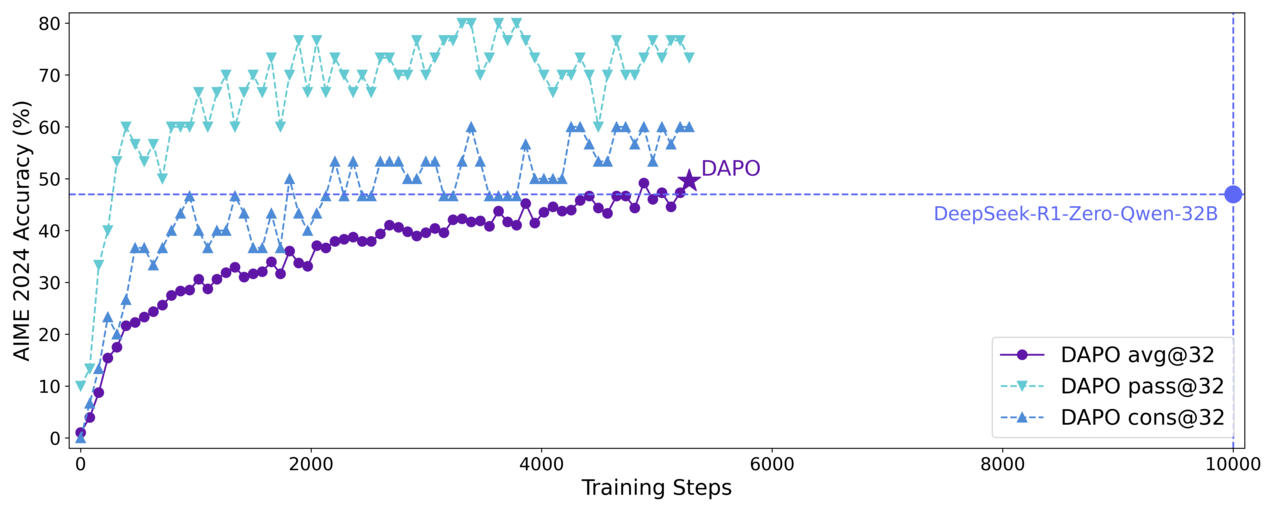
The DAPO algorithm has a better performance than the Deep Chic-R1 on the benchmark.
Alibaba’s ‘Cue One 2.5-32B’ won 50 points in ‘AIME 2024’ and exceeded the deep chic method (47 points) using the identical model.
As well as, 50% lower than the present methods have achieved higher results.
The result was positive from the community.
Philip Schmide Google Deep Mind Engineer said on X (Twitter), “This is best than Deep Chic’s GRPO.” “The community develops into this transparency and collaboration,” said Arfit Sharma, a cloud infrastructure construction company.
Then again, Vitali Kurin NVIDIA’s chief research scientist questioned that reducing the training stage doesn’t mean reducing the whole training time.
DAPO’s algorithm, learning code, and dataset In GitHub You possibly can download it.
By Park Chan, reporter cpark@aitimes.com