
The form of content that users might wish to create using a generative model resembling Flux or Hunyuan Video is probably not all the time be easily available, even when the content request is fairly generic, and one might guess that the generator could handle it.
One example, illustrated in a brand new paper that we’ll take a take a look at in this text, notes that the increasingly-eclipsed OpenAI Sora model has some difficulty rendering an anatomically correct firefly, using the prompt :
Source: https://arxiv.org/pdf/2503.01739
Since I rarely take research claims at face value, I tested the identical prompt on Sora today and got a rather higher result. Nevertheless, Sora still didn’t render the glow appropriately – moderately than illuminating the tip of the firefly’s tail, where bioluminescence occurs, it misplaced the glow near the insect’s feet:

Paradoxically, the Adobe Firefly generative diffusion engine, trained on the corporate’s copyright-secured stock photos and videos, only managed a 1-in-3 success rate on this regard, after I tried the identical prompt in Photoshop’s generative AI feature:

This instance was highlighted by the researchers of the brand new paper for instance that the distribution, emphasis and coverage in training sets used to tell popular foundation models may not align with the user’s needs, even when the user will not be asking for anything particularly difficult – a subject that brings up the challenges involved in adapting hyperscale training datasets to their best and performative outcomes as generative models.
The authors state:
They introduce a newly curated dataset and suggest that their methodology could possibly be refined in future work to create data collections that higher align with user expectations than many existing models.
Data for the People
Essentially their proposal posits an information curation approach that falls somewhere between the custom data for a model-type resembling a LoRA (and this approach is way too specific for general use); and the broad and comparatively indiscriminate high-volume collections (resembling the LAION dataset powering Stable Diffusion) which aren’t specifically aligned with any end-use scenario.
The brand new approach, each as methodology and a novel dataset, is (moderately tortuously) named , or . The VideoUFO dataset comprises 1.9 million video clips spanning 1291 user-focused topics. The topics themselves were elaborately developed from an existing video dataset, and parsed through diverse language models and Natural Language Processing (NLP) techniques:
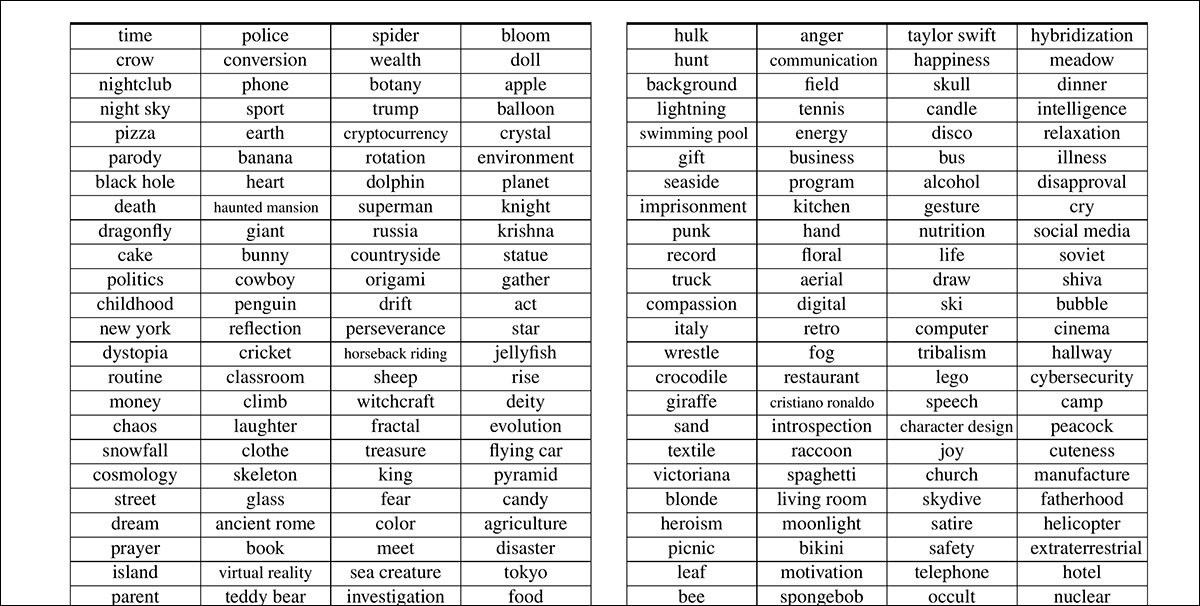
The VideoUFO dataset encompasses a high volume of novel videos trawled from YouTube – ‘novel’ within the sense that the videos in query don’t feature in video datasets which might be currently popular within the literature, and due to this fact in the numerous subsets which were curated from them (and lots of the videos were in actual fact uploaded subsequent to the creation of the older datasets thar the paper mentions).
In actual fact, the authors claim that there’s – a formidable demonstration of novelty.
One reason for this could be that the authors would only accept YouTube videos with a Creative Commons license that might be less prone to hamstring users further down the road: it’s possible that this category of videos has been less prioritized in prior sweeps of YouTube and other high-volume platforms.
Secondly, the videos were requested on the idea of pre-estimated user-need (see image above), and never indiscriminately trawled. These two aspects together could lead on to such a novel collection. Moreover, the researchers checked the YouTube IDs of any contributing videos (i.e., videos which will later have been split up and re-imagined for the VideoUFO collection) against those featured in existing collections, lending credence to the claim.
Though not every part in the brand new paper is kind of as convincing, it’s an interesting read that emphasizes the extent to which we’re still moderately on the mercy of uneven distributions in datasets, when it comes to the obstacles the research scene is commonly confronted with in dataset curation.
The recent work is titled , and comes from two researchers, respectively from the University of Technology Sydney in Australia, and Zhejiang University in China.

A ‘Personal Shopper’ for AI Data
The material and ideas featured in the entire sum of web images and videos don’t necessarily reflect what the typical end user may find yourself asking for from a generative system; even where content and demand are likely to collide (as with porn, which is plentifully available on the web and of great interest to many gen AI users), this may increasingly not align with the developers’ intent and standards for a brand new generative system.
Besides the high volume of NSFW material uploaded day by day, a disproportionate amount of net-available material is prone to be from advertisers and people attempting to govern search engine optimisation. Business self-interest of this type makes the distribution of material removed from impartial; worse, it’s difficult to develop AI-based filtering systems that may deal with the issue, since algorithms and models developed from meaningful hyperscale data may in themselves reflect the source data’s tendencies and priorities.
Subsequently the authors of the brand new work have approached the issue by reversing the proposition, through determining what users are prone to want, and obtaining videos that align with these needs.
On the surface, this approach seems just as prone to trigger a semantic race to the underside as to attain a balanced, Wikipedia-style neutrality. Calibrating data curation around user demand risks amplifying the preferences of the lowest-common-denominator while marginalizing area of interest users, since majority interests will inevitably carry greater weight.
Nonetheless, let’s take a take a look at how the paper tackles the challenge.
Distilling Concepts with Discretion
The researchers used the 2024 VidProM dataset because the source for topic evaluation that might later inform the project’s web-scraping.
This dataset was chosen, the authors state, since it is the one publicly-available 1m+ dataset ‘written by real users’ – and it ought to be stated that this dataset was itself curated by the 2 authors of the brand new paper.
The paper explains*:
The authors indicate that certain concepts are distinct but notably adjoining, resembling and . Too granular a criteria for cases of this type would result in concept embeddings (as an example) for every kind of dog breed, as an alternative of the term ; whereas too broad a criteria could corral an excessive variety of sub-concepts right into a single over-crowded concept; due to this fact the paper notes the balancing act obligatory to guage such cases.
Singular and plural forms were merged, and verbs restored to their base (infinitive) forms. Excessively broad terms – resembling , , and – were removed.
Thus 1,291 topics were obtained (with the total list available within the source paper’s supplementary section).
Select Web-Scraping
Next, the researchers used the official YouTube API to hunt videos based on the standards distilled from the 2024 dataset, looking for to acquire 500 videos for every topic. Besides the requisite creative commons license, each video needed to have a resolution of 720p or higher, and needed to be shorter than 4 minutes.
In this fashion 586,490 videos were scraped from YouTube.
The authors compared the YouTube ID of the downloaded videos to quite a lot of popular datasets: OpenVid-1M; HD-VILA-100M; Intern-Vid; Koala-36M; LVD-2M; MiraData; Panda-70M; VidGen-1M; and WebVid-10M.
They found that only one,675 IDs (the aforementioned 0.29%) of the VideoUFO clips featured in these older collections, and it must be conceded that while the dataset comparison list will not be exhaustive, it does include all the most important and most influential players within the generative video scene.
Splits and Assessment
The obtained videos were subsequently segmented into multiple clips, in line with the methodology outlined within the Panda-70M paper cited above. Shot boundaries were estimated, assemblies stitched, and the concatenated videos divided into single clips, with temporary and detailed captions provided.

The temporary captions were handled by the Panda-70M method, and the detailed video captions by Qwen2-VL-7B, along the rules established by Open-Sora-Plan. In cases where clips didn’t successfully embody the intended goal concept, the detailed captions for every such clip were fed into GPT-4o mini, in an effort to ascertain whether it was truly a fit for the subject. Though the authors would have preferred evaluation via GPT-4o, this might have been too expensive for thousands and thousands of video clips.
Video quality assessment was handled with six methods from the VBench project .
Comparisons
The authors repeated the subject extraction process on the aforementioned prior datasets. For this, it was obligatory to semantically-match the derived categories of VideoUFO to the inevitably different categories in the opposite collections; it must be conceded that such processes supply only approximated equivalent categories, and due to this fact this may increasingly be too subjective a process to vouchsafe empirical comparisons.
Nonetheless, within the image below we see the outcomes the researchers obtained by this method:
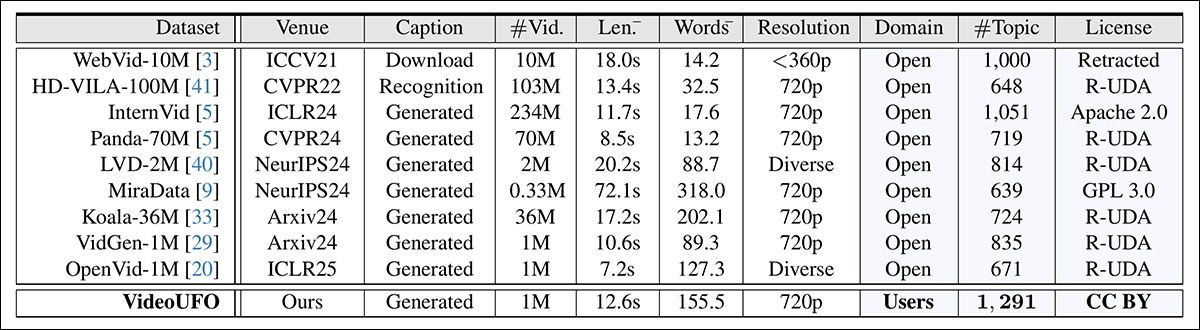
The researchers acknowledge that their evaluation relied on the present captions and descriptions provided in each dataset. They admit that re-captioning older datasets using the identical method as VideoUFO could have offered a more direct comparison. Nevertheless, given the sheer volume of knowledge points, their conclusion that this approach can be prohibitively expensive seems justified.
Generation
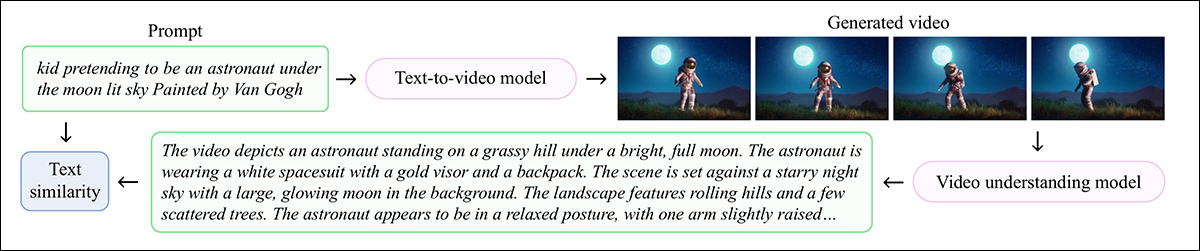
The authors developed a benchmark to guage text-to-video models’ performance on user-focused concepts, titled . This entailed choosing 791 nouns from the 1,291 distilled user topics in VideoUFO. For every chosen topic, ten text prompts from VidProM were then randomly chosen.
Each prompt was passed through to a text-to-video model, with the aforementioned Qwen2-VL-7B captioner used to guage the generated results. With all generated videos thus captioned, SentenceTransformers was used to calculate cosine similarity for each the input prompt and output (inferred) description in each case.
The evaluated generative models were: Mira; Show-1; LTX-Video; Open-Sora-Plan; Open Sora; TF-T2V; Mochi-1; HiGen; Pika; RepVideo; T2V-Zero; CogVideoX; Latte-1; Hunyuan Video; LaVie; and Pyramidal.
Besides VideoUFO, MVDiT-VidGen and MVDit-OpenVid were the choice training datasets.
The outcomes consider the Tenth-Fiftieth worst-performing and best-performing topics across the architectures and datasets.
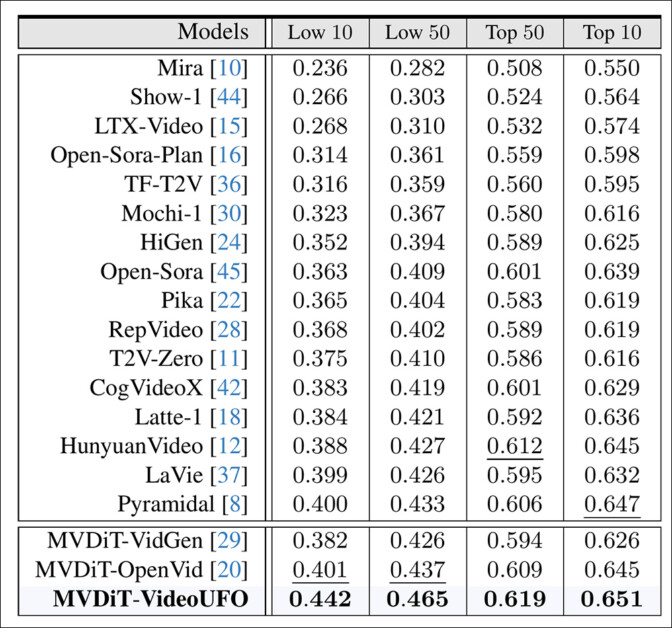
Here the authors comment:
Conclusion
VideoUFO is an impressive offering if only from the standpoint of fresh data. If there was no error in evaluating and eliminating YouTube IDs, and if the dataset comprises a lot material that’s recent to the research scene, it’s a rare and potentially beneficial proposition.
The downside is that one needs to offer credence to the core methodology; in case you do not believe that user demand should inform web-scraping formulas, you would be buying right into a dataset that comes with its own sets of troubling biases.
Further, the utility of the distilled topics depends upon each the reliability of the distilling method used (which is mostly hampered by budget constraints), and in addition the formulation methods for the 2024 dataset that gives the source material.
That said, VideoUFO actually merits further investigation – and it’s available at Hugging Face.
*