
Going beyond the present Search Augmented Generation (RAG), which conducts searches based on a single knowledge source, predictions have emerged that so-called ‘RAG agents’, which extract information from multiple knowledge sources using various tools, will turn into the mainstream.
Vector database company Weaviate predicted on the thirteenth (local time) that RAG agent might be a ‘game changer’ for corporations in Large Language Model (LLM)-based applications. blog postintroduced.
A basic RAG pipeline consists of two principal elements: a ‘retriever’ and a ‘generator’.
Retriever uses a vector database and embedding model to investigate user questions and find essentially the most similar content in indexed documents. The generator uses LLM based on the retrieved data to generate answers that reflect the relevant business context.
While this architecture is helpful for providing businesses with accurate answers, it has limitations when leveraging multiple source of knowledge.
Existing RAG pipelines cannot provide information beyond a single source of data, which makes them applicable only to specific applications. Moreover, because the data retrieved by the retriever is the premise for the model’s answers, incorrect sources can affect accuracy.
One solution to solve this is thru AI agents (agentic AI). AI Agent is a technique wherein an LLM-based AI agent with memory and reasoning functions plans multiple steps of labor and performs complex tasks using various external tools.
It could possibly be applied to the Retriever component of the RAG pipeline, allowing it to retrieve information from greater than a single knowledge source using web searches, calculators, and various software APIs. Select a tool that matches the user’s query, check to see if there may be relevant information, extract accurate information through re-search if essential, after which pass it to the generator to generate the ultimate answer.
This approach expands the knowledge base of the LLM application, providing more accurate and validated responses to even complex questions. For instance, if support content is stored within the Vector database and a user asks the query “What are essentially the most steadily raised issues today?” the RAG agent will check today’s date through an internet search and store that information within the Vector database. Combined with information, it may provide an entire answer.
By adding tool-enabled AI agents, search agents can route inquiries to specific knowledge sources, adding an extra layer where retrieved information may be verified before processing. This permits the RAG agent pipeline to supply accurate responses.
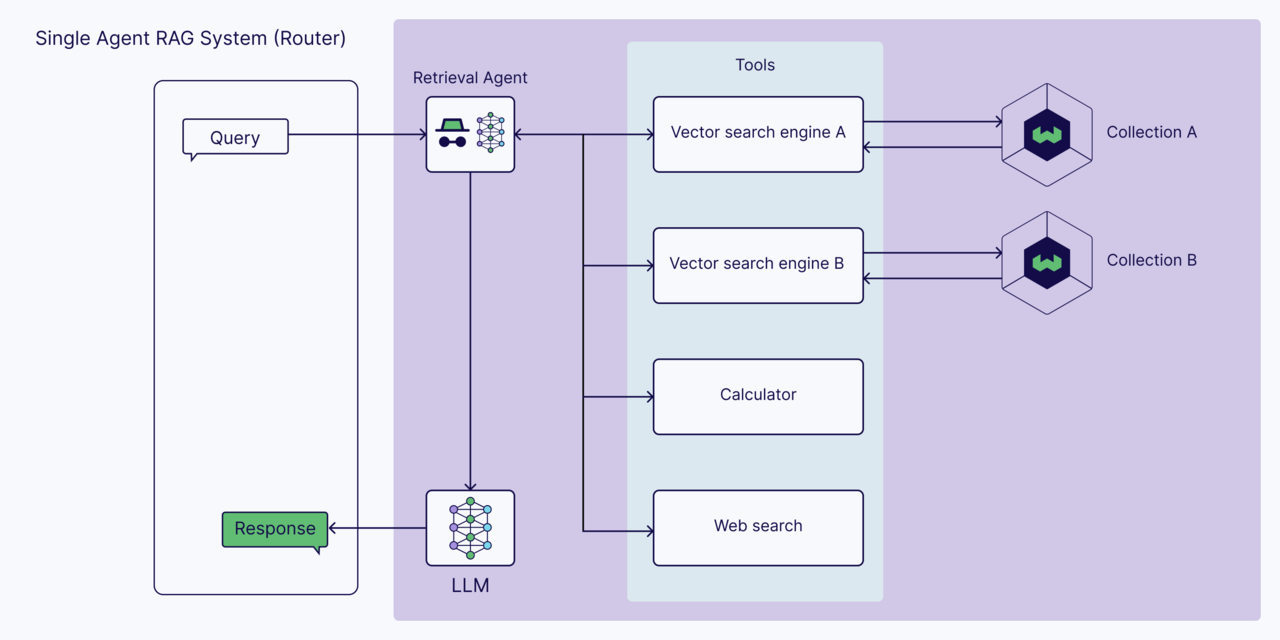
We introduced two ways to establish the RAG agent pipeline.
One is a single agent system, which searches and verifies data through multiple knowledge sources. One other method is a multi-agent system, where several specialized agents retrieve data from each knowledge source, and a master agent processes this information and passes it to the generator.
Nevertheless, the RAG agent identified that multi-step processing could cause delays. Moreover, the computational cost may increase as more requests are made.
Reporter Park Chan cpark@aitimes.com