
If artificial intelligence (AI) technology continues to develop at the present pace, it’s predicted that by 2030, the dimensions of AI models could expand 10,000 times from what it’s now.
SingularityHub recently cited a report from non-profit research organization Epoch AI, which predicted that AI will advance dramatically over the subsequent 10 years.
To create this scenario, the Epoch researchers conducted detailed simulations of the 4 biggest constraints on AI scaling.
To start with, power was cited as the most important problem.
Meta’s latest model, Rama 3, was trained with 16,000 Nvidia chips that devour 27 megawatts (MW) of electricity, which is reminiscent of the annual power consumption of 23,000 U.S. households.
Even with improved power efficiency, training frontier models would require 200 times more power by 2030, or 6 gigawatts (GW), reminiscent of 30 percent of the ability consumed by all data centers today.
Few single power plants have that sort of capability, and AI corporations will need to search out locations that may draw power from multiple power plants. Given the present planned growth in utilities, that’s a bit tight, however it’s still possible to produce power through 2030.
A promising solution to resolve this bottleneck is to distribute training across multiple data centers. This method requires high-speed, high-bandwidth fiber connections, and Google’s Gemini Ultra is claimed to have used this method.
Overall, it presented various power supply scenarios, from 1GW of a single power plant to as much as 45GW using distributed power sources. The more power you utilize, the larger the model you’ll be able to train, concluding which you could use as much as 10,000 times more computing power than ‘GPT-4’.
Power is used to run AI chips, essentially the most critical component of AI learning.
To predict the computing infrastructure used for model training, we took under consideration GPU design corporations like Nvidia, TSMC that manufactures them, and the high-bandwidth memory corporations that support them. Epoch sees that while dual GPU production may provide some leeway, there could possibly be shortages in memory and packaging.
In any case, considering the expansion rate of the chip industry, it is predicted that 200 to 400 million AI chips might be used for AI training by 2030.
In reality, this field is so broad in scope that it’s difficult to predict, but considering the expected chip capability, it was concluded that it could have a computing infrastructure about 50,000 times greater than GPT-4.
The following area we checked out was data for AI learning. There’s much disagreement amongst experts on this area, and there are predictions that data will run out in the subsequent two years.
Nevertheless, Epoch doesn’t see data exhaustion as holding back model growth until a minimum of 2030. As an alternative, it writes that at the present rate of growth, quality text data will run out inside five years, and that copyright litigation adds uncertainty. Nevertheless, even when the courts side with copyright holders, the immediate impact on data supply is prone to be limited on account of the complex procedures involved in contracts and litigation.
Relatively, we focused more on the rise of multimodal data and the practicality of synthetic data. Particularly, we identified that within the case of synthetic data, it shouldn’t be only practical, but in addition costs money to create it.
Combining text, non-text, and artificial data like that is estimated to be enough to coach an AI model with computing power 80,000 times more powerful than GPT-4.
Finally, the educational delay time of the model we checked out is said to the dimensions of the algorithm. The larger the model, the longer the educational time, which is a very important think about determining the model development cycle.
Simply applying all these aspects results in the conclusion that AI training will be scaled as much as 1,000,000 times more computing power than GPT-4.
Nevertheless, there’s a bottleneck here: power cannot sustain with the rise in chips. Taking all this under consideration, the model concludes that the present trend can only proceed until the primary bottleneck, that’s, the ability limit, is reached in five years.
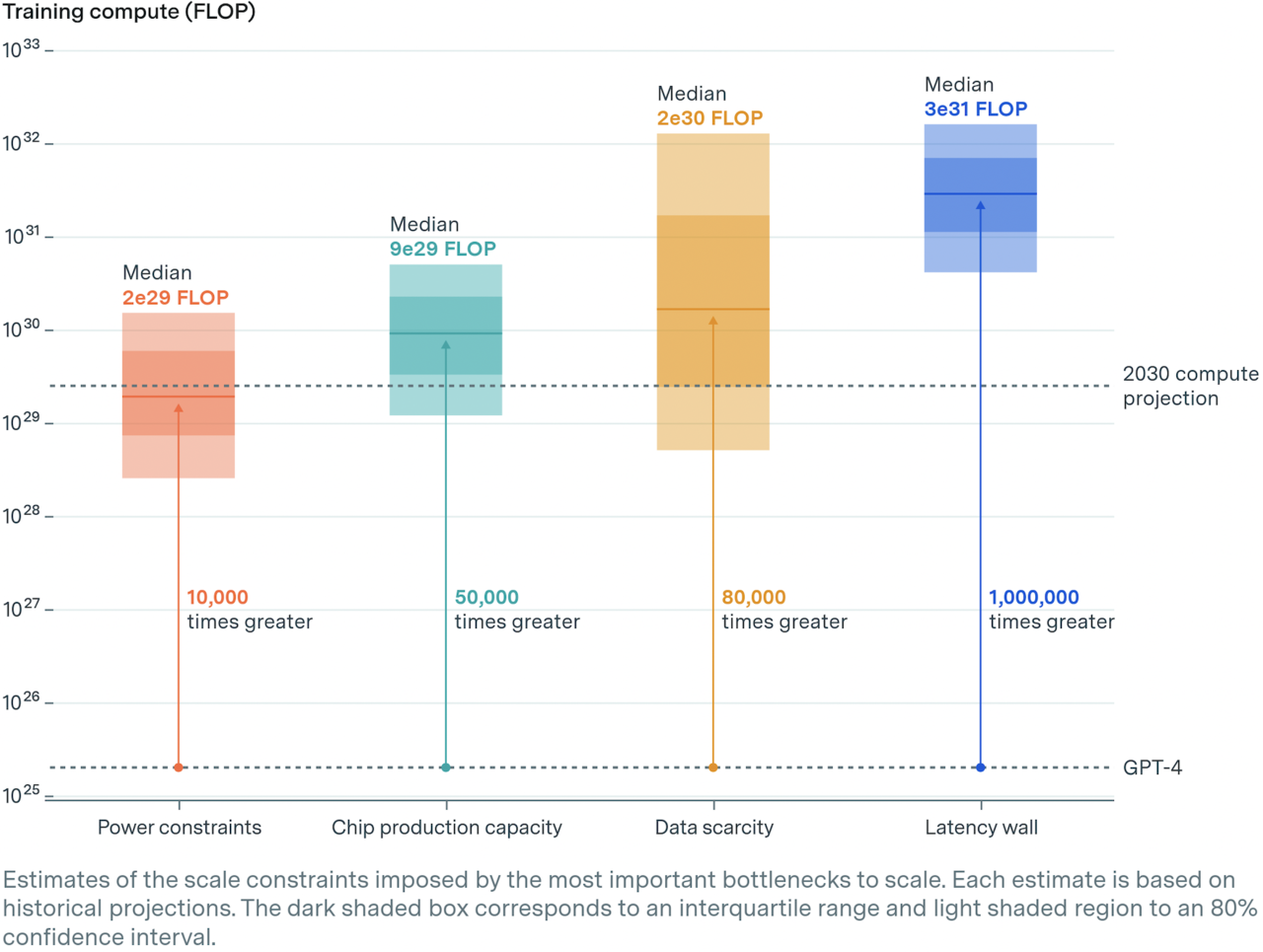
“Taking these phenomena under consideration comprehensively, Epoch says that inside 10 years, training runs of as much as 2e29 FLOPs might be possible,” he said. “This represents a scale-up of roughly 10,000x over current models, and suggests that this scaling trend could proceed uninterrupted until 2030.”
He also emphasized, “If things proceed this manner, AI will advance dramatically in 10 years, much like the difference between ‘GPT-2’ in 2019, which was limited to basic text generation, and ‘GPT-4’ in 2023, which has sophisticated problem-solving capabilities.”
Finally, he identified that for such development to be possible, there should be a social belief that the present atmosphere, by which investment far outstrips returns, can proceed.
Reporter Im Dae-jun ydj@aitimes.com