
Microsoft (MS) has released a brand new series of small language models (sLMs) called ‘Phi 3.5’. The benchmark results claim that it outperforms Google’s ‘Gemma 1.5’, Meta’s ‘Rama 3.1’, and OpenAI’s ‘GPT-4o Mini’ in some functions.
VentureBeat reported on the twentieth (local time) that MS has released as open source ▲’pi-3.5-mini-instruct’ for fast inference with 3.82 billion parameters, ▲’pi-3.5-MoE-instruct’ for advanced inference with 41.9 billion parameters, and ▲’pi-3.5-vision-instruct’ for image and video evaluation with 4.15 billion parameters.
Pie-3.5-mini-Instruct is designed for code generation, including inference, and mathematical problem solving in limited computing environments resembling laptops and mobile devices. It’s optimized for performance related to multilingual and complicated conversations, and supports a context window of 128,000 tokens, allowing for reviewing large amounts of text directly.
Particularly, it outperformed comparable models resembling ‘Rama-3.1-8B-Instruct’ and ‘Mistral-7B-Instruct’ on the RepoQA benchmark, which measures long context code understanding.
Pie-3.5-MoE-Instruct is designed to perform well on various inference tasks by adopting the Mixed Experts (MoE) approach and supports a context window of 128,000 tokens.
MoE splits a big language model (LLM) into small expert models (Expert), and connects or mixes several sorts of expert models depending on the query. Because it only processes the expert models required for a given request, pi-3.5-MoE-Instruct prompts only 6.6 billion of the full 41.9 billion parameters to perform the duty. This makes it much cheaper and time-consuming than running all the large model.
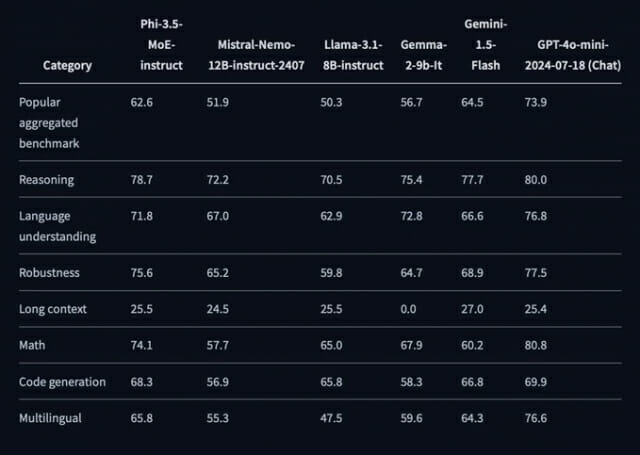
Through this, it achieved results that surpassed GPT-4o mini in some benchmark results. Within the ‘MMLU’ benchmark, which evaluates language understanding in various fields resembling STEM, humanities, and social sciences, it scored 2-3% higher on average than GPT-4o mini. It also achieved high performance in ‘RepoQA’, which evaluates understanding of code or information extraction from long contexts.
Pie-3.5-Vision-Instruct is a multimodal model that integrates each text and image processing functions. It is especially suitable for tasks resembling general image understanding, optical character recognition, chart and table understanding, and video summarization. It supports 128,000 token context windows to administer complex multi-frame visual tasks.
The present Pi 3.5 series models are Download from Hugging FaceIt could possibly be used for business purposes and might be fine-tuned together with your own data. It is usually licensed under MS’s MIT license, so there are not any restrictions on business use, modification, or distribution.
Reporter Park Chan cpark@aitimes.com