
OpenAI has released a framework for training large language models (LLMs) to have the ability to clarify things to users. It features the introduction of the previously introduced ‘game theory’ to elaborate the reasons of LLMs.
VentureBeat reported on the seventeenth (local time) that OpenAI published a study explaining a brand new technique to improve the accuracy and explainability of LLM’s responses. Post your paper within the archiveHe said he did it.
It is rather vital for LLMs to supply comprehensible texts, especially when coping with complex tasks reminiscent of solving mathematical problems.
This approach is designed to enhance trust in artificial intelligence (AI) systems in tasks where accuracy is paramount. It is predicated on the paper “Prover-Verifier Game” published by the University of Toronto and the AI Vector Lab in 2021.
On this study, two models are pitted against one another as a ‘prover’ and a ‘verifier’. The smarter model takes on the role of a ‘prover’ and must explain the answer to a given problem, while the less smart model takes on the role of a ‘verifier’ and must show whether the prover is correct or fallacious.
The goal of the sport is to show the prover to generate responses which can be comprehensible enough for the verifier to grasp. Based on OpenAI, this permits the AI model to offer more comprehensible and verifiable output to human users.
OpenAI pitted a more powerful GPT-4 model against a much weaker model because the verifier. The prover was instructed to alternate between the “helpful” and “sly” roles in each round of the sport, attempting to confuse the verifier. They tested this method using elementary school math problems.
When set to the helpful role, the prover is rewarded for generating an accurate response that the verifier likes and confirms as valid. When set to the cunning role, the prover is rewarded for generating a false response that may idiot the verifier.
Within the early stages of the test, a sly prover could easily idiot the verifier with incorrect answers. Nevertheless, because the interaction continued, the verifier, learning through interaction, learned to catch the prover’s subtle mistakes.
In addition they found that in the first place, the prover model produced accurate but difficult-to-understand responses. As the sport progressed, the researchers reported that the prover model outputted explanations that were increasingly easier for the opponent to grasp.
We also found that the verifier model was twice as effective as humans at detecting incorrect responses generated by the cunning prover model.
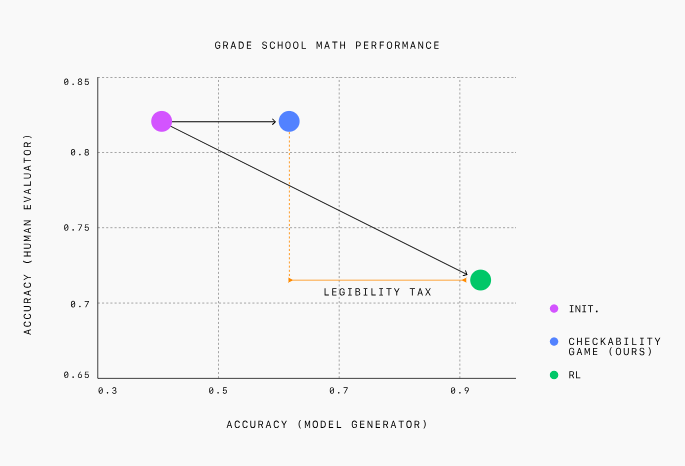
The researchers concluded that combining the 2 models in this fashion produces AI explanations which can be easier to grasp. They said this approach is a promising technique to construct AI systems in industries reminiscent of medicine, finance, and law that require trustworthiness and accuracy.
Based on the researchers, the largest advantage of this method is that it relies much less on human guidance and evaluation than other explainability solutions, potentially eliminating the necessity for direct human supervision.
Reporter Park Chan cpark@aitimes.com