
Apple has open-sourced a learning framework for models that may perform a wide range of vision AI functions. This permits a single model to handle dozens of various modality tasks, which is claimed to be according to Apple’s on-device AI policy.
VentureBeat reported on the first (local time) that Apple is collaborating with the Swiss Federal Institute of Technology Lausanne (EPFL) to develop a ‘Hugging Face’4M(Massively Multimodal Masked Modeling)It was introduced that a demo of ‘ was released.
4M is a learning framework for multimodal models that process various vision AI tasks with a single image. It’s the primary real demo to be released in only seven months after the open source paper was published at NeurIPS in December last 12 months.
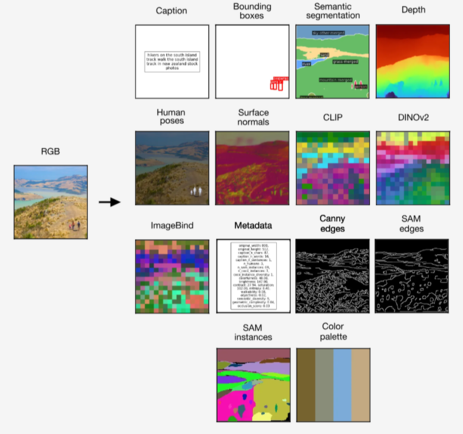
Training the model with it will enable a wide range of vision tasks, including caption generation through image evaluation, bounding boxes, object segmentation, metadata, depth, image binding, geometric and semantic modalities, and neural network feature maps.
For instance, one can generate modalities equivalent to object segmentation, depth, bounding boxes, and captions from RGB images, and one can generate RGB images, object segmentation, depth, and bounding boxes from captions.
In 4M, tokenizing each modality individually after which grouping them into token sequences allows training a single transformer encoder-decoder on a various set of modalities. 4M trains by mapping a random subset of tokens to a different set.
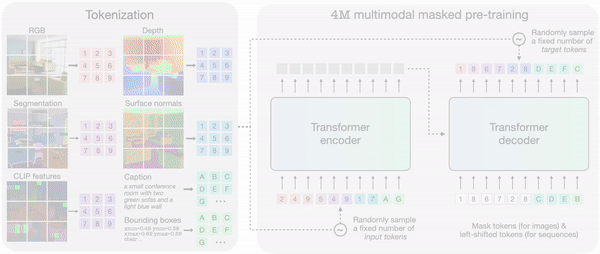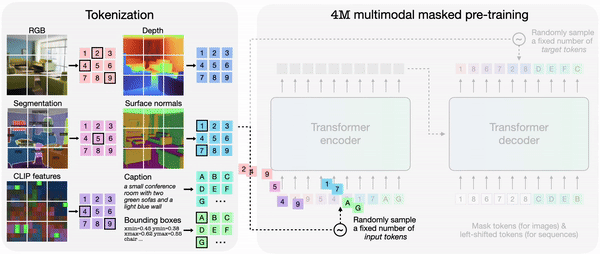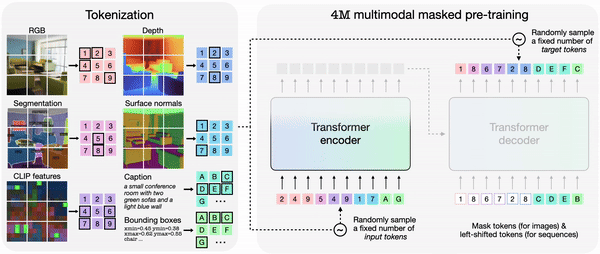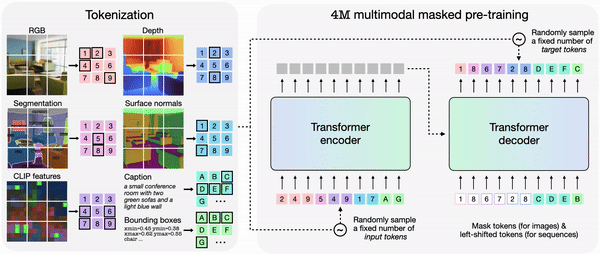
The trained 4M model can generate arbitrary modalities by combining other modalities, and might perform predictions with only partial inputs. As a substitute of predicting individually, 4M can reconnect the newly generated modality as input to generate the following modality. Because of this, it’s explained that every one trained modalities might be predicted in a consistent manner.
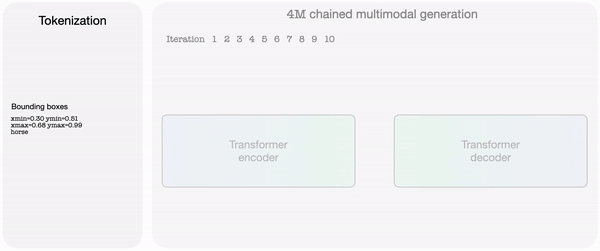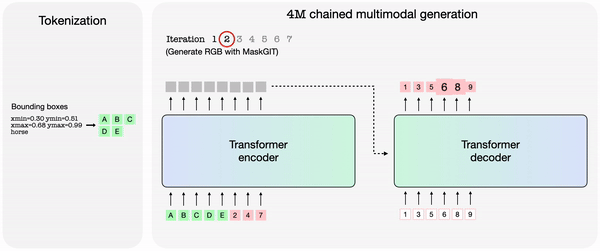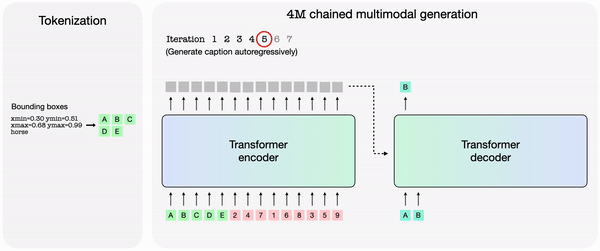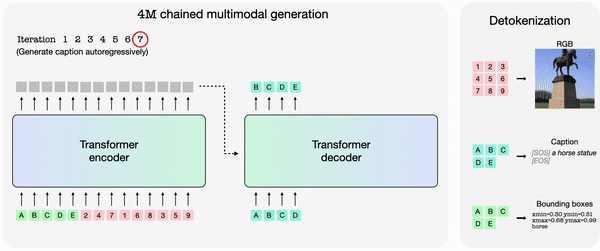
Apple also released models trained on 4M, equivalent to ‘4M-7 198M’, ‘4M-21 705M’, and ‘4M-84 2.8B’. The 4M framework and related models were released as open source under the Apache 2.0 license.
The best advantage of this framework is that it not only shows excellent performance in various vision tasks, but in addition might be widely applied to existing programs.
That’s, ‘Siri’ might be made to grasp and reply to complex multi-part queries that include text, images, spatial information, etc.
Additionally it is expected to be useful for creating and editing video content with natural language prompts within the Mac video editing tool ‘Final Pro Cut’, and for the mixed reality (MR) headset ‘Vision Pro’.
VentureBeat said, “While Apple Intelligence has focused on personalized on-device AI experiences for devices like iPhones and Macs, 4M hints at the corporate’s longer-term AI ambitions,” adding, “The model’s ability to govern 3D scenes via natural language input could have interesting implications for Vision Pro and Apple’s augmented reality (AR) efforts.”
Reporter Park Chan cpark@aitimes.com