
Code embeddings are a transformative solution to represent code snippets as dense vectors in a continuous space. These embeddings capture the semantic and functional relationships between code snippets, enabling powerful applications in AI-assisted programming. Much like word embeddings in natural language processing (NLP), code embeddings position similar code snippets close together within the vector space, allowing machines to grasp and manipulate code more effectively.
What are Code Embeddings?
Code embeddings convert complex code structures into numerical vectors that capture the meaning and functionality of the code. Unlike traditional methods that treat code as sequences of characters, embeddings capture the semantic relationships between parts of the code. That is crucial for various AI-driven software engineering tasks, comparable to code search, completion, bug detection, and more.
For instance, consider these two Python functions:
def add_numbers(a, b):
return a + b
def sum_two_values(x, y):
result = x + y
return result
While these functions look different syntactically, they perform the identical operation. A great code embedding would represent these two functions with similar vectors, capturing their functional similarity despite their textual differences.
Vector Embedding
How are Code Embeddings Created?
There are different techniques for creating code embeddings. One common approach involves using neural networks to learn these representations from a big dataset of code. The network analyzes the code structure, including tokens (keywords, identifiers), syntax (how the code is structured), and potentially comments to learn the relationships between different code snippets.
Let’s break down the method:
- Code as a Sequence: First, code snippets are treated as sequences of tokens (variables, keywords, operators).
- Neural Network Training: A neural network processes these sequences and learns to map them to fixed-size vector representations. The network considers aspects like syntax, semantics, and relationships between code elements.
- Capturing Similarities: The training goals to position similar code snippets (with similar functionality) close together within the vector space. This permits for tasks like finding similar code or comparing functionality.
Here’s a simplified Python example of how you may preprocess code for embedding:
import ast
def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Add more node types as needed
return tokens
# Example usage
code = """
def greet(name):
print("Hello, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
This tokenized representation can then be fed right into a neural network for embedding.
Existing Approaches to Code Embedding
Existing methods for code embedding could be classified into three major categories:
Token-Based Methods
Token-based methods treat code as a sequence of lexical tokens. Techniques like Term Frequency-Inverse Document Frequency (TF-IDF) and deep learning models like CodeBERT fall into this category.
Tree-Based Methods
Tree-based methods parse code into abstract syntax trees (ASTs) or other tree structures, capturing the syntactic and semantic rules of the code. Examples include tree-based neural networks and models like code2vec and ASTNN.
Graph-Based Methods
Graph-based methods construct graphs from code, comparable to control flow graphs (CFGs) and data flow graphs (DFGs), to represent the dynamic behavior and dependencies of the code. GraphCodeBERT is a notable example.
TransformCode: A Framework for Code Embedding
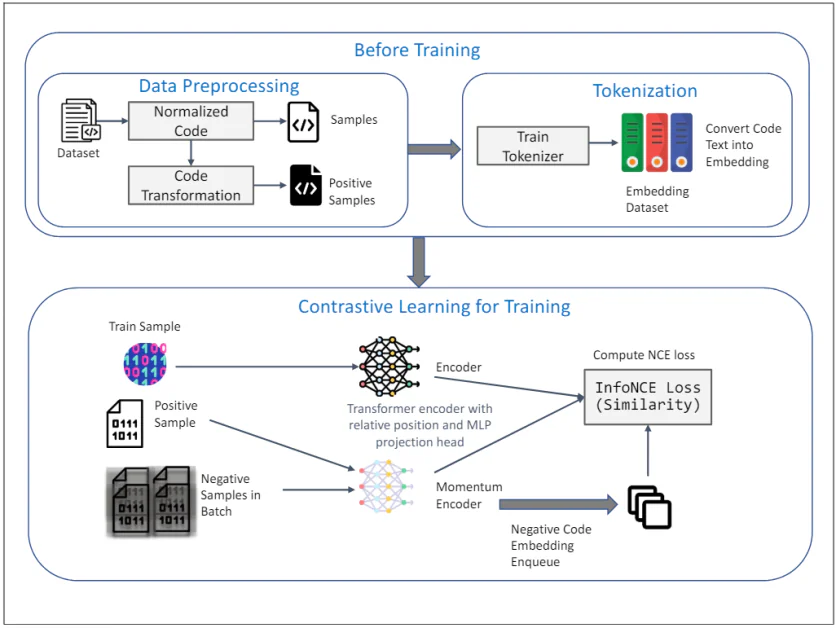
TransformCode: Unsupervised learning of code embedding
TransformCode is a framework that addresses the constraints of existing methods by learning code embeddings in a contrastive learning manner. It’s encoder-agnostic and language-agnostic, meaning it will probably leverage any encoder model and handle any programming language.
The diagram above illustrates the framework of TransformCode for unsupervised learning of code embedding using contrastive learning. It consists of two major phases: Before Training and Contrastive Learning for Training. Here’s an in depth explanation of every component:
Before Training
1. Data Preprocessing:
- Dataset: The initial input is a dataset containing code snippets.
- Normalized Code: The code snippets undergo normalization to remove comments and rename variables to a typical format. This helps in reducing the influence of variable naming on the educational process and improves the generalizability of the model.
- Code Transformation: The normalized code is then transformed using various syntactic and semantic transformations to generate positive samples. These transformations be certain that the semantic meaning of the code stays unchanged, providing diverse and robust samples for contrastive learning.
2. Tokenization:
- Train Tokenizer: A tokenizer is trained on the code dataset to convert code text into embeddings. This involves breaking down the code into smaller units, comparable to tokens, that could be processed by the model.
- Embedding Dataset: The trained tokenizer is used to convert the whole code dataset into embeddings, which serve because the input for the contrastive learning phase.
Contrastive Learning for Training
3. Training Process:
- Train Sample: A sample from the training dataset is chosen because the query code representation.
- Positive Sample: The corresponding positive sample is the transformed version of the query code, obtained throughout the data preprocessing phase.
- Negative Samples in Batch: Negative samples are all other code samples in the present mini-batch which are different from the positive sample.
4. Encoder and Momentum Encoder:
- Transformer Encoder with Relative Position and MLP Projection Head: Each the query and positive samples are fed right into a Transformer encoder. The encoder incorporates relative position encoding to capture the syntactic structure and relationships between tokens within the code. An MLP (Multi-Layer Perceptron) projection head is used to map the encoded representations to a lower-dimensional space where the contrastive learning objective is applied.
- Momentum Encoder: A momentum encoder can also be used, which is updated by a moving average of the query encoder’s parameters. This helps maintain the consistency and variety of the representations, stopping the collapse of the contrastive loss. The negative samples are encoded using this momentum encoder and enqueued for the contrastive learning process.
5. Contrastive Learning Objective:
- Compute InfoNCE Loss (Similarity): The InfoNCE (Noise Contrastive Estimation) loss is computed to maximise the similarity between the query and positive samples while minimizing the similarity between the query and negative samples. This objective ensures that the learned embeddings are discriminative and robust, capturing the semantic similarity of the code snippets.
The whole framework leverages the strengths of contrastive learning to learn meaningful and robust code embeddings from unlabeled data. Using AST transformations and a momentum encoder further enhances the standard and efficiency of the learned representations, making TransformCode a robust tool for various software engineering tasks.
Key Features of TransformCode
- Flexibility and Adaptability: Could be prolonged to varied downstream tasks requiring code representation.
- Efficiency and Scalability: Doesn’t require a big model or extensive training data, supporting any programming language.
- Unsupervised and Supervised Learning: Could be applied to each learning scenarios by incorporating task-specific labels or objectives.
- Adjustable Parameters: The variety of encoder parameters could be adjusted based on available computing resources.
TransformCode introduces A knowledge-augmentation technique called AST transformation, applying syntactic and semantic transformations to the unique code snippets. This generates diverse and robust samples for contrastive learning.
Applications of Code Embeddings
Code embeddings have revolutionized various facets of software engineering by transforming code from a textual format to a numerical representation usable by machine learning models. Listed here are some key applications:
Improved Code Search
Traditionally, code search relied on keyword matching, which frequently led to irrelevant results. Code embeddings enable semantic search, where code snippets are ranked based on their similarity in functionality, even in the event that they use different keywords. This significantly improves the accuracy and efficiency of finding relevant code inside large codebases.
Smarter Code Completion
Code completion tools suggest relevant code snippets based on the present context. By leveraging code embeddings, these tools can provide more accurate and helpful suggestions by understanding the semantic meaning of the code being written. This translates to faster and more productive coding experiences.
Automated Code Correction and Bug Detection
Code embeddings could be used to discover patterns that always indicate bugs or inefficiencies in code. By analyzing the similarity between code snippets and known bug patterns, these systems can mechanically suggest fixes or highlight areas which may require further inspection.
Enhanced Code Summarization and Documentation Generation
Large codebases often lack proper documentation, making it difficult for brand spanking new developers to grasp their workings. Code embeddings can create concise summaries that capture the essence of the code’s functionality. This not only improves code maintainability but in addition facilitates knowledge transfer inside development teams.
Improved Code Reviews
Code reviews are crucial for maintaining code quality. Code embeddings can assist reviewers by highlighting potential issues and suggesting improvements. Moreover, they will facilitate comparisons between different code versions, making the review process more efficient.
Cross-Lingual Code Processing
The world of software development just isn’t limited to a single programming language. Code embeddings hold promise for facilitating cross-lingual code processing tasks. By capturing the semantic relationships between code written in numerous languages, these techniques could enable tasks like code search and evaluation across programming languages.

