
LMSYS, famous for ‘Chatbot Arena’, which evaluates human preferences, has unveiled ‘Multimodal Arena’, which evaluates the image understanding ability of artificial intelligence (AI) models. Here too, OpenAI’s ‘GPT-4o’ took first place.
LMSYS announced on the twenty eighth (local time) that it had launched a leaderboard for Chatbot Arena’s vision model through X (Twitter).
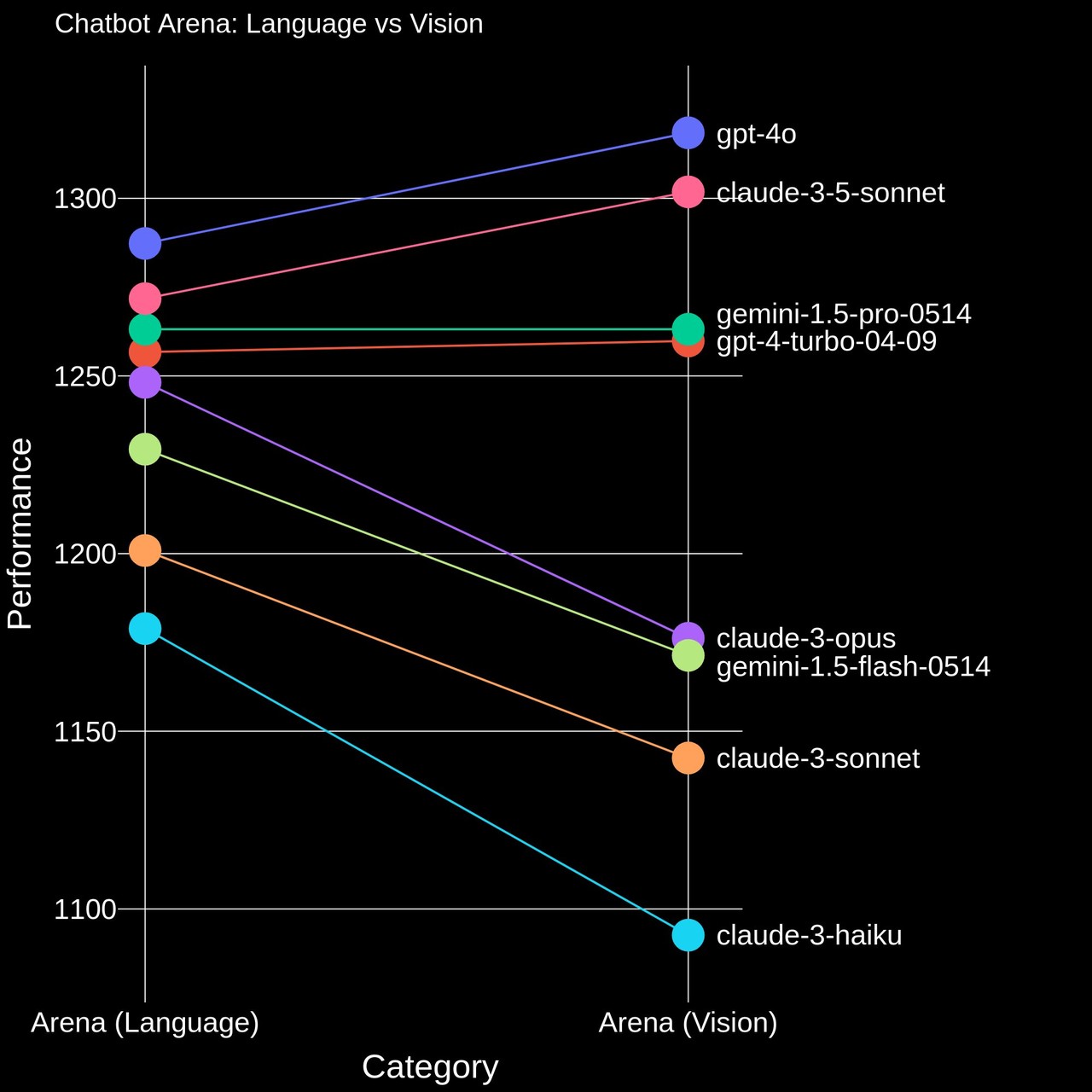
In response to this, after greater than 17,000 user votes for various use cases over the past two weeks, GPT-4o is currently leading.
It’s followed by Anthropic’s ‘Claude 3.5 Sonnet’, while Google’s LMM ‘Gemini 1.5 Pro’ stays in third place.
Amongst open source models, ‘LLaVA-v1.6-34B’ released by Microsoft’s MSRA Lab and Antropic’s ‘Claude 3 Haiku’ are tied for eighth place with similar scores.
LMSYS is a company run by the University of California, Berkeley, UC San Diego, and Carnegie Mellon University. Their Chatbot Arena, which appeared a 12 months ago, is different from existing benchmarks in that users blindly ask inquiries to two chatbots and vote for the outcomes they like.
For the reason that end of last 12 months, issues regarding the utility of benchmarks have been repeatedly raised, and Chatbot Arena is gaining great popularity, attracting attention as a brand new alternative.
Accordingly, LMSYS has expanded the benchmark goal from existing language skills to pictures. Within the multimodal arena, users ask two random models to perform various tasks comparable to image description, math problem solving, document understanding, meme explanation, and story writing, after which compare the outcomes and vote.
GPT-4o won the Chatbot Arena and have become the double champion. Claude 3.5 Sonnet won the subsections ‘Coding’ and ‘Hard Prompts’, but still got here in second within the two essential categories of Chatbot and Multimodal.
In fact, it is thought that LMM’s image understanding ability continues to be significantly inferior to that of humans.
VentureBeat cited the outcomes of a benchmark (CharXiv) recently introduced by researchers at Princeton University and identified that the accuracy of GPT-4o was only 47.1%. This rating is way behind the human accuracy rate of 80.5%.
Meanwhile, benchmarks for evaluating LLM performance have gotten increasingly diverse. The representative LLM leaderboard of Hugging Face was also significantly upgraded on the twenty seventh, the day before.
This evaluation shows that interest in and importance of benchmarks have increased. It’s because it objectively compares the performance of LLMs, promotes research in related fields, and serves as a very important reference for firms searching for to adopt models.
LMSYS can be receiving a wide range of requests from users. A post calling for the creation of a brand new leaderboard that compares the flexibility to create specific foreign languages or images and videos is attracting attention.
Reporter Lim Da-jun ydj@aitimes.com