
HuggingFace has released a brand new open source Large Language Model (LLM) leaderboard following recent criticisms concerning the effectiveness of benchmarks. The primary rankings show strong performances from Chinese models.
Tom’s Hardware reported that in the primary rating of the brand new ‘Open LLM Leaderboard’ announced by Hugging Face on the twenty seventh (local time), 4 Chinese models were in the highest 10, with China’s Alibaba’s ‘Qwen’ taking first place.
The second leaderboard release of HuggingFace is available in response to recent criticism that existing evaluation criteria aren’t any longer sufficient to accurately evaluate model performance, as benchmark datasets have turn into older and model performance has improved dramatically.
“Previous benchmarks were too easy for recent model performance, like evaluating highschool students on middle school questions,” said Clement Delang, founder and CEO of HuggingFace, via X (Twitter), explaining the explanation for the change. “Particularly, there have been reports of AI developers sacrificing performance in other areas in an effort to improve their scores on some key benchmarks.”
He continued, “With the discharge of the brand new leaderboard, we expect the benchmark field to mature,” and explained, “We used a supercomputer equipped with 300 ‘H100’s to re-run recent evaluations comparable to MMLU-Pro.” .
The brand new leaderboard tests open source LLMs across 4 tasks: ▲ Knowledge Test ▲ Reasoning in Long Context ▲ Complex Mathematical Ability ▲ Following Directions. Six benchmarks are used to check this, including ▲ Solving a 1,000-word murder mystery ▲ Explaining a PhD-level problem in layman’s terms ▲ Solving essentially the most difficult highschool math equations.
For this reason, the leaderboard was completely modified. Q.one, who took the lead on the brand new leaderboard, also took third and tenth place with three versions.
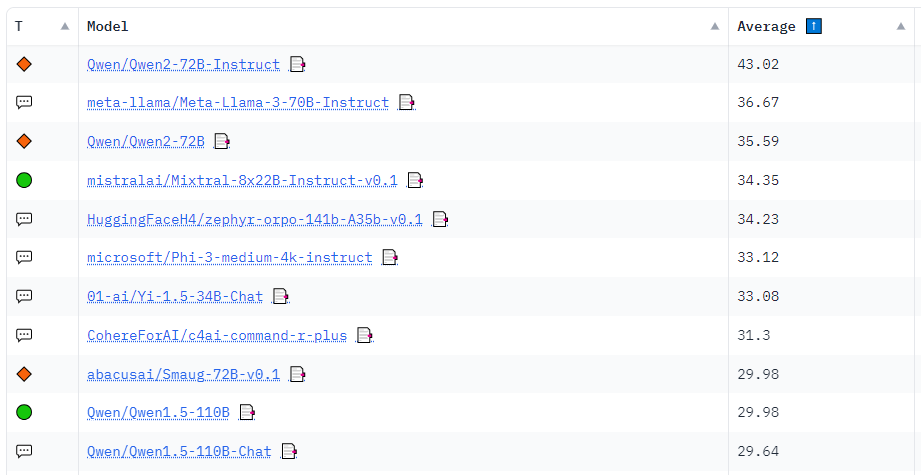
2nd place is Meta’s ‘Rama3-70B’, 4th place is Mistral’s ‘Mixtral-8x22B’, fifth place is Huggingface’s ‘Zephyr-141B’, sixth place is Microsoft’s (MS) ‘Phi-3-Medium’, seventh place is China’s 01.AI’s ‘Yi-1.5-34B’, and eighth place is Abakusa’s ‘Smaug-72B’, which was the primary to exceed a mean rating of 80 on the prevailing leaderboard, etc. are existing major models.
Nevertheless, ‘Rama 3’ fell behind the primary place Qwon by a mean of 6.35 points on the brand new leaderboard.
This evaluation shows that Rama 3 had an excessive proportion of coaching data from the prevailing leaderboard, proving that LLM performance ultimately relies on training data.
Also, the model of domestic startup TwoDigit, which previously ranked first, disappeared from the highest 10. The typical rating in the highest tier was also significantly lowered from the previous 80 points to 30-40 points.
Meanwhile, the brand new Hugging Face Leaderboard allows anyone to submit a model and be tested.
Nevertheless, following criticism that the prevailing leaderboard was overflowing with variant models submitted for easy testing purposes, this time we’ll filter to check only the major models.
Reporter Park Chan cpark@aitimes.com