
Weight & Bias (W&B), an American AI developer platform, announced on the 2nd that it has began operating the 'Horangi Korean LLM Leaderboard', which discloses the rating of the Korean language performance evaluation results of enormous language models (LLM).
The Tiger Leaderboard is the second Korean LLM performance evaluation leaderboard following Upstage and the Korea Intelligence Agency (NIA)'s 'Ko-LLM Leaderboard'.
W&B announced that, through domestic partner firms and internal voting, they selected the name Tiger, which is most familiar to Koreans as a result of the 1988 Olympic mascot and the Dangun myth. He also said, “We’re also successfully operating a Japanese LLM leaderboard named 'Nezumi (mouse)' in Japan, which is called after the engineer's Twitter ID.”
Its strengths include not only evaluating the language understanding and language generation abilities of the LLM model from various angles, but additionally providing result reports and interactive evaluation functions.
Evaluation indicators are categorized into ‘language understanding’ and ‘language production’.
Language understanding uses a question-and-answer evaluation system to guage the power to accurately understand input content and answer within the required format.
Language generation outputs answers to the model in a free format and performs qualitative evaluation using 'GPT-4'. This evaluation system utilizes the MT-Bench framework developed in collaboration with Stability AI.
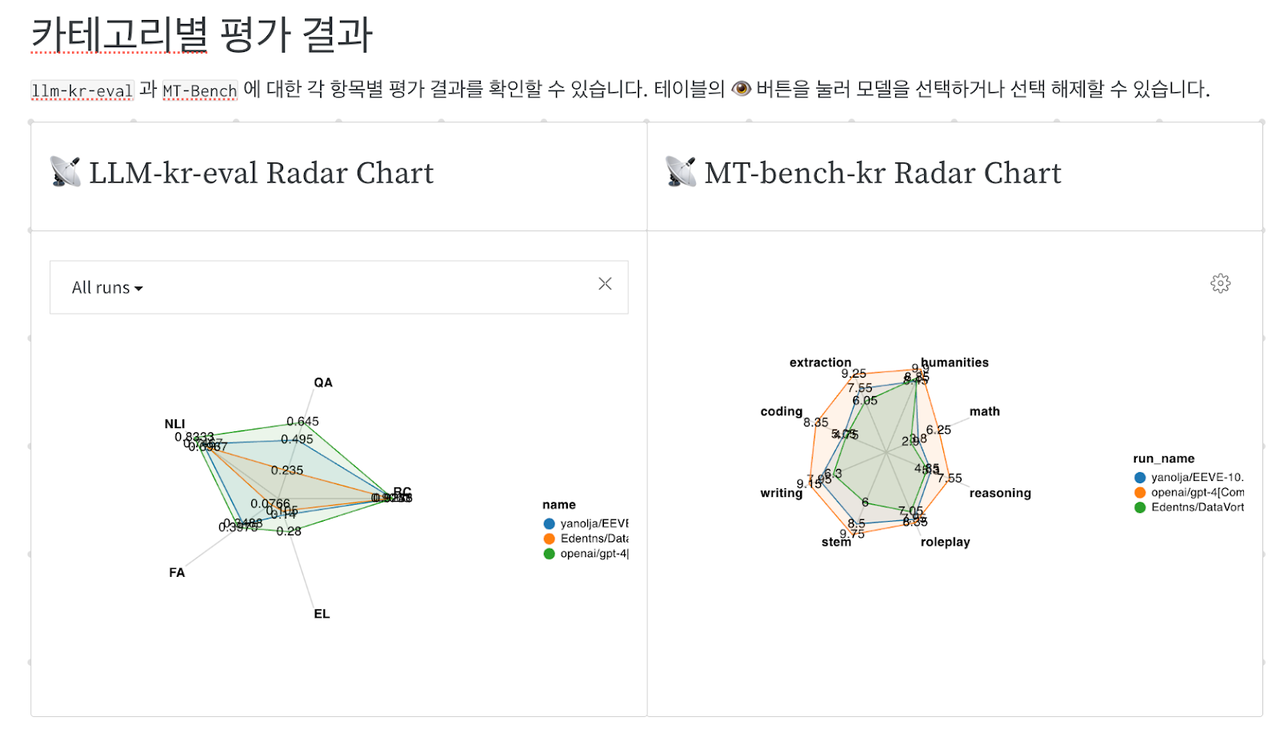
Each evaluation category consists of subcategories in keeping with specific purposes. In language generation, the strength of the model is verified in evaluation axes reminiscent of writing, reasoning, and data extraction.
A W&B official explained, “It helps you understand the strengths of the model and choose the model that suits your purpose by allowing you to match the required indicators for every model characteristic.”
He also emphasized that model performance could be measured without making the model public.
In other words, unlike Hugging Face, which requires all model weights and parameters in addition to scores for every item to be disclosed, Tiger Leaderboard focuses on performing evaluations on the corporate's infrastructure and may keep evaluation results private.
A W&B official said, “Before releasing the model, we use W&B's package to guage the performance of every LLM characteristic and help with development.” The reason is that conducting a mock evaluation before being evaluated on the actual leaderboard may help develop LLM performance.
He also said, “W&B views Korea as an important market within the Asia-Pacific market,” and added, “We plan to work closely with academia through the W&B platform and support Korean firms in solving the duty of improving LLM model performance.”
As well as, “Information on the evaluation approach to the tiger leaderboard is blogYou may check it at, and detailed information and specific usage instructions will probably be available on April eleventh. Host a free webinar“We plan to guide you thru the 12 months,” he said.
Meanwhile, in April of this 12 months, W&B not only launched various functions specialized for LLM development support and announced integration with major LLM application development frameworks reminiscent of Langchain and Llamindex, but additionally launched a platform that may visually manage and confirm the event process. It’s provided.
As well as, in Korea, we’ve a product support system through sales partnerships with Leaders Systems and Penta Systems.
Reporter Park Soo-bin sbin08@aitimes.com