
사람의 음성이나 소리, 음악과 같은 다양한 오디오 입력을 듣고 이해하고 추론할 수 있는 인공지능(AI) 시스템이 등장했다. 기존 음성을 텍스트로 전환하는 STT(음성 텍스트 전환) 방식을 넘어, 다양한 유형의 오디오를 동시에 학습하고 이해할 수 있는 ‘오디오 전문’ 멀티모달 아키텍처를 실현했다는 점에서 주목된다.
벤처비트는 24일(현지시간) 중국 칭화대학교와 바이트댄스 연구진이 음성, 소리, 음악과 같은 오디오 입력을 이해하고 추론할 수 있는 대형언어모델(LLM) ‘새몬(SALMONN)’에 관한 논문을 온라인 아카이브(arXiv)에 게재했다고 보도했다.
이에 따르면 새몬은 음성 처리용과 일반 오디오용 등 두가지 특수 AI 모델을 오디오 프롬프트에 대한 텍스트 응답을 생성할 수 있는 단일 LLM으로 병합했다.
여러 유형의 오디오 데이터를 별도로 저장하는 대신 결합해 단일 임베딩에 보관한다. 음성과 일반 오디오 입력을 새로운 토큰 세트로 임베딩한 토큰의 혼합 시퀀스와 함께 질문을 위한 텍스트 프롬프트를 입력하면 LLM이 응답하게 된다.
특히 이 모델은 여러 유형의 데이터를 한번에 분석할 수 있다. 예를 들어 폭발음과 총소리가 들리는 가운데 ‘내가 지금 어디에 있는지 추측해 보라’고 말하면 ‘전쟁터’라고 답하는 식이다.
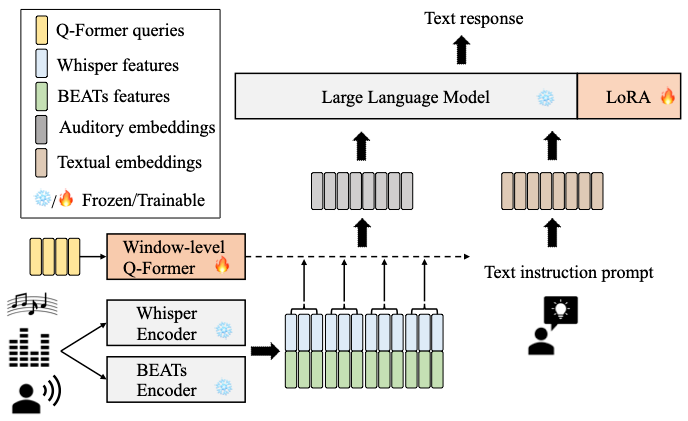
사람처럼 동시에 여러 오디오에서 정보를 수집하고 정보를 전체적으로 처리할 수 있다. 즉 어떤 소리가 들리는지, 화자가 남자인지 여자인지, 노래하는지 말하는지, 말의 의미는 무엇인지 등에 대한 전체적인 이해를 제공한다.
기존의 음성 전용 입력이나 오디오 전용 입력 대신 새몬을 통해 모든 종류의 오디오 입력을 인식하고 이해할 수 있기 때문에 다국어 음성 인식 및 번역, 오디오 및 음성 공동 추론과 같은 새 기능을 제공할 수 있다. 결과적으로 이는 LLM에 ‘청각 능력’을 부여하는 것으로 이해할 수 있다.
연구진은 “기존의 음성 및 오디오 처리 작업과 비교하면 새몬은 LLM의 일반 지식과 인지 능력을 활용해 오디오 인식 능력을 한차원 끌어올렸다고 볼 수 있다”라고 주장했다.
다만 연구진은 아직 모델이 추론적인 면에서 한계가 있음을 인정했다. 새몬은 오픈소스로 제공되며, 허깅페이스에서 사용할 수 있다.
박찬 기자 cpark@aitimes.com